day48——杂项
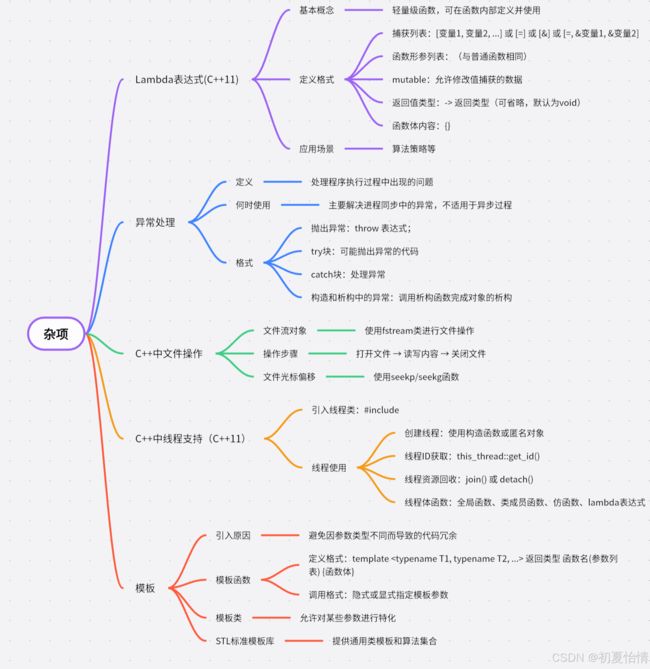 一、Lambda表达式(C++11)
一、Lambda表达式(C++11)
1.1 基本概念
lambda表达式相当于在函数中定义一个轻量版函数,可以直接使用,也可以赋值给其他函数指针变量使用
1.2 定义格式
1> 格式 : [捕获列表](函数形参列表)[mutable] [->返回值类型]{函数体内容};
2> 解析
1、捕获列表:分为值捕获和引用捕获
值捕获:值捕获时,表达式中的数据和外界的数据属于不同的数据,并且在非mutable的lambda表达式中值捕获数据可读不可写
[变量1,变量2,。。。,变量n]:将这些数据都进行值捕获
[=]:将外界的变量全部进行值捕获
[=,&变量1,&变量2]:除了将变量1和变量2进行引用捕获外,其他都是值捕获
引用捕获:表达式中的数据和外界数据属于相同的数据,对数据操作时可读可写
[&变量1,&变量2,。。。,&变量n]:将这些数据都进行引用捕获
[&]:将外界的变量全部进行引用捕获
[&,变量1,变量2]:除了变量1和变量2是值捕获外,其他都是引用捕获
2、(函数形参列表):表达式的形参,跟函数形参格式一致,用于外界传递数据使用
3、mutable:该关键字修饰的lambda表达式,运行对值捕获的数据进行修改
4、->返回值类型:表示lambda表达式的返回值类型,如果不写,默认为void,此时如果表达式体内,写了return,则返回结果根据return后的类型而定
一般情况下省略
5、{}:中是函数体内容
6、表达式结果后,需要使用分号结束
#include
using namespace std;
//外部定义
void show()
{
cout<<"hello world"< 1.3 常用情况
lambda表达式常用于算法的相关策略
#include
#include //算法库
//定义全局函数作为策略
int comp(int a, int b)
{
return a>b; //前面的数据大于后面的数据
}
//定义仿函数当作策略
class comp1
{
public:
comp1() {}
int operator()(int a, int b)
{
return a>b;
}
};
using namespace std;
int main()
{
int arr[] = {3,7,2,1,4,9,3,6};
int len = sizeof(arr)/sizeof(arr[0]); //求数组容量
//将数组进行排序
//sort(arr, arr+len); //:如果不加策略,默认是升序排序
//sort(arr, arr+len, comp); //加了策略的排序函数:全局函数作为策略
//sort(arr, arr+len, comp1()); //仿函数当作执行策略
sort(arr, arr+len, [](int a, int b){return a>b;}); //lambda表达式当作策略
//输出数据
cout<<"数组中的数据为:";
for(auto val:arr)
{
cout< 二、异常处理
2.1 什么是异常处理
1> 异常就是程序执行过程中出现的问题
2> "异常"问题并不是经常出现
3> C语言中处理异常使用的是函数返回值完成,可以根据不同的异常返回不同的结果
4> C++中支持异常处理机制,完成一些不能使用返回值来完成的异常情况
2.2 何时使用异常处理
1> 异常处理主要解决进程同步过程中出现的异常情况,不能解决进程异步过程中的情况
2> 经常处理的错误:数组溢出、算数溢出、内存分配不足、指针越界、构造空间不足。。。
2.3 异常处理的格式
1、在可能产生异常的地方使用关键字:throw 抛出异常
2、try
{
可能会抛出异常的语句
}catch(接收异常的形参)
{
处理异常
}注意:任何函数在定义时,可以指定能抛出的异常格式如下
返回值类型 函数名(形参列表) throw(异常类型1,异常类型2,。。。。)
如果某个函数一定不会抛出异常,格式为
返回值类型 函数名(形参列表) noexcept
2.4 异常实例
#include
using namespace std;
//定义两数相除的函数
double division(const double &op1, const double &op2) throw(string, double)
{
if(op2 == 0)
{
throw string("除数不能为0"); //抛出异常对象
}
//人为创建一个异常
if(op1 == op2)
{
throw 0.0;
}
return op1/op2;
}
int main()
{
//使用时将可能产生异常的代码放入到try中
try {
cout<<"结果为"< 2.5 构造和析构中的异常
1> 关于析构的步骤
1、程序收到一个异常
2、初始化异常参数
3、将从对应的try语句块内处理异常,并调用析构函数完成对对象的析构
4、处理最后一个catch语句
2> 自定义异常类及测试析构函数在异常中的调用
#include
using namespace std;
//自定义异常类
class MyException
{
public:
MyException() {}
MyException(string m):err_msg(m) {}
~MyException() {}
string what(){return err_msg;} //返回本次异常的错误信息
private:
string err_msg;
};
//定义一个测试类
class Demo
{
public:
Demo() {cout<<"Demo ::构造函数"< 2.6 系统提供异常类
1> 系统提供的异常类都是由 exception 类派生出来的
2> 系统的异常一般如下
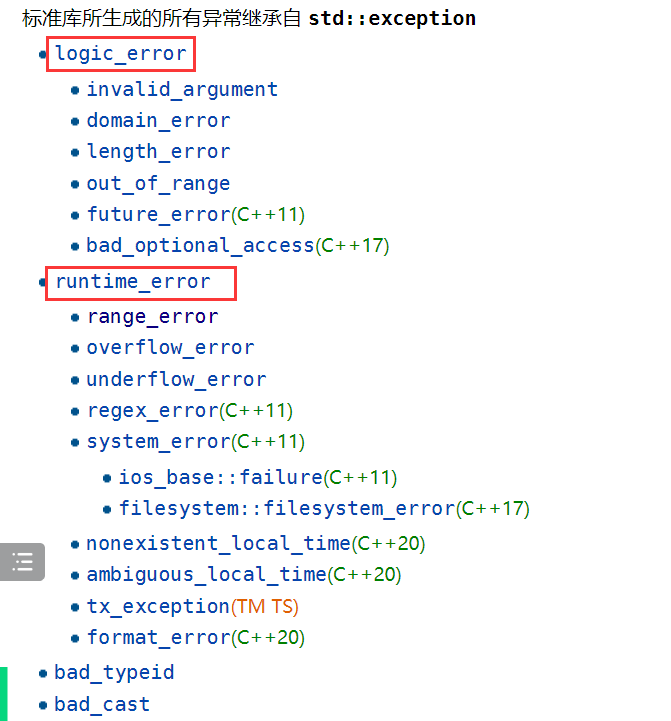
#include
#include
using namespace std;
int main()
{
int arr[10] = {0};
int num;
try {
int index;
cin >> index;
if(index <0 || index >=10)
{
throw out_of_range("数组下标越界");
}
num = arr[index];
} catch (string &e) {
cout<<"异常信息: "< 练习:
定义函数,传入三角形的三条边,求出三角形的周长
要求:如果传入的三角形的任意一边为负数,则抛出参数异常错误
如果传入的三边不能构成三角形,则抛出长度异常的错误
也可以抛出自定义的异常
#include
#include
using namespace std;
int primeter(int a, int b, int c) throw(invalid_argument, length_error)
{
//判断参数是否合法
if(a<=0 || b<=0 || c<=0)
{
throw invalid_argument("参数不合法");
}
//判断参数长度是否合法
if(a+b<=c || a+c<=b || b+c<=a)
{
throw length_error("长度不合法");
}
return a+b+c;
}
int main()
{
int a,b,c;
cout<<"请输入>>>";
cin >> a >> b >> c;
try {
int res = primeter(a, b, c);
cout<<"周长为:"< 三、C++中文件操作
3.1 文件流对象的介绍
1> C++中提供文件流对象,来完成对文件的操作
2> 对于文件的操作,使用的时 fstream 类的对象
ios_base
/ \
istream ostream
| \ / |
| iostream |
ifstream ofstream
\ /
fstream3.2 关于文件的操作
1> 打开文件和关闭文件
1、使用fstream的有参构造函数来完成
2、使用fstream类调用无参构造实例一个文件对象
调用成员函数open来完成
#if 0
//方式1:使用构造函数打开文件
fstream file("./test.txt", ios_base::out|ios_base::in|ios_base::trunc);
//判断文件有没有打开
if(!file.is_open())
{
cout<<"文件打开失败"<2> 读写内容
C++也提供了多种数据的读写
1、使用插入和提取运算符重载函数完成
2、可以使用成员函数get、put、read、write完成
3> 文件光标的偏移
可以使用成员函数 seekp(移动写光标)、seekg(移动读光标)来完成
练习:使用C++中的IO操作,完成两个文件的拷贝
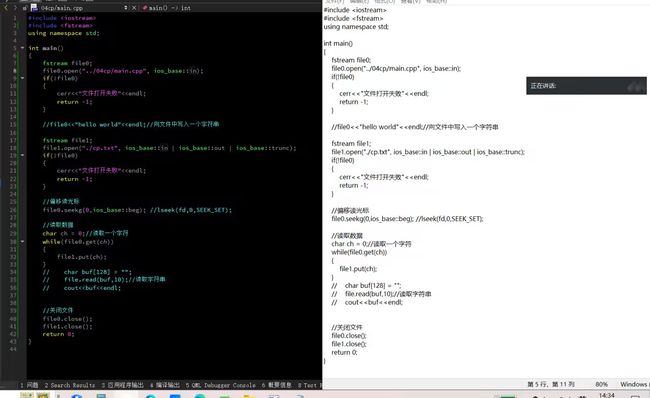
四、C++中线程支持(C++11)
4.1 线程支持类的引入
1> 需要引入类 thread
2> 所在头文件 #include
4.2 线程的相关使用
1> 创建线程:可以使用构造函数完成
注意:线程体函数,跟C语言的有所不同
也可以使用匿名对象完成构造
2> 线程体Id的获取:this_thread::get_id()
3> 线程资源回收:join()
4> 线程分离态:detach();
5> 线程体函数可以是全局函数、类中成员函数、仿函数、lambda表达式
#include
#include //线程支持库
using namespace std;
//定义线程体函数
void task()
{
while(1)
{
cout<<"我是分支线程:"< 五、模板
5.1 模板的引入
1> 有时候程序性定义函数或者定义类时,可能由于参数的类型不同,导致相同功能的函数或者相同功能的类需要定义多个,造成程序的冗余
2> 此时我们就可以引入模板的概念:当调用函数时或者使用类进行实例化对象时,不仅将实参值传递过去,而且也要讲类型作为参数传递过去
3> 模板分为模板函数和模板类
5.2 模板函数
1> 所谓模板函数,就是在定义函数时,函数的参数的类型和参数值都不给定,等到函数调用时,根据传进来的实参的类型和值来确定该函数的具体实现
2> 定义格式
tamplate
类型 函数名(参数类型1 参数名1, 参数类型2,参数名2, 。。。)
{函数体内容} 3> 调用格式:
1、跟普通函数的调用一样(隐式调用)
2、调用函数时,在函数名后面使用<>给定类型参数(显式调用)
4> 同一个模板生命下,只能定义一个函数,如果要定义多个,需要声明多个模板
5> 显性调用时的原则:尖找尖 圆找圆
#include
using namespace std;
/*
//两整数qiu和
int sum(int m, int n)
{
return m+n;
}
//两个小数求和
double sum(double m, double n)
{
return m+n;
}
//两个字符串求和
string sum(string m, string n)
{
return m+n;
}
*/
//定义模板函数
template
T sum(T m, T n)
{
return m+n;
}
template
T sum(T m, T n, T k)
{
return m+n+k;
}
//与上一个模板函数构成重载关系
template
T2 sum(T1 m, T2 n)
{
return m+n;
}
int main()
{
cout << sum(3,7) << endl; //10 隐士调用
cout << sum(3,7.5) << endl; //10.7 显示调用:尖找尖 圆找圆
cout << sum(string("3"),string("7")) << endl; //37
return 0;
} 5.3 模板函数的特化
1> 允许定义模板函数时,给某些参数指定类型,这样的模板就是特化模板
2> 当基础模板和特化模板同时存在时
如果时隐式调用函数,则调用的是基础模板
如果是显示调用函数,则调用的是特化模板
#include
using namespace std;
//定义模板函数
template
T sum(T m, T n)
{
cout<<"_______基础模板___________"<
T sum(int m, int n)
{
cout<<"_______特化模板__________"<(520,1314); //模板函数的显示调用时,如果基础模板和特化模板同时存在,则调用特化模板
return 0;
} 5.4 模板类
1> 程序员在定义类的过程中,可能会因为类型的不同,导致同一功能的类,需要定义多个
例如:定义一个链表中的节点,由于数据域类型的不同,导致节点需要定义多个
2> 定义格式
tamplate
class 类名
{
类型 成员名;
} #include
using namespace std;
//模板类的定义格式
template
class Node
{
public:
T data; //数据域
Node *next; //指针域
public:
Node():next(NULL) {}
Node(T e); //类内声明
~Node() {}
};
//当模板类中的函数类内声明类外定义时需要注意两点:
//1、需要为该函数单独声明一个模板
//2、但凡后面有出现模板类名时,在后面都要显性调用<>给定类型
template
Node::Node(T e):data(e), next(NULL)
{
cout< n1(520); //此时就定义了一个整型节点
Node n2("hello"); //此时就定义了一个字符串节点
Node *ptr = &n1; //定义指针指向第一个节点
Node n3(1314);
ptr->next = &n3;
return 0;
} 3> 注意:
1、定义模板时,如果成员函数是类内声明类外定义,那么需要在类外定义时,重新声明一个模板
2、在类外任意处,如果需要使用类名,都必须后面显示使用<>,表示该类是模板
3、使用模板类实例化对象时,必须显式调用,不能隐式调用
4> 模板类也有模板类的特化
5.5 STL标准模板库(非常重要)
C++ STL (Standard Template Library标准模板库) 是通用类模板和算法的集合,它提供给程序员一些标准的数据结构的实现如 queues(队列), lists(链表), 和 stacks(栈)等.
C++ STL 提供给程序员以下三类数据结构的实现:
顺序结构
C++ Vectors
C++ Lists
C++ Double-Ended Queues
容器适配器
C++ Stacks
C++ Queues
C++ Priority Queues
联合容器
C++ Bitsets
C++ Maps
C++ Multimaps
C++ Sets
C++ Multisets
程序员使用复杂数据结构的最困难的部分已经由STL完成. 如果程序员想使用包含int数据的stack, 他只要写出如下的代码:
stack
接下来, 他只要简单的调用 push() 和 pop() 函数来操作栈. 借助 C++ 模板的威力, 他可以指定任何的数据类型,不仅仅是int类型. STL stack实现了栈的功能,而不管容纳的是什么数据类型.
5.5.1 vector动态数组
1> 常用函数
1、构造函数
vector(); //无参构造
vector( size_type num, const TYPE &val ); //有参构造,使用 num个val来构造一个vector
vector( const vector &from ); //拷贝构造
vector( input_iterator start, input_iterator end ); //使用一个容器的起始位置到终止为止的内容构造一个vector
2> 实例演示
#include
#include //将头文件引入
using namespace std;
int main()
{
vector v1; //定义一个存放整数的vector 无参构造
//判空函数 empty
if(v1.empty())
{
cout<<"v1 is empty"< v2(5, "hello");
cout<<"此时容器中的数据分别时:";
for(auto val:v2)
{
cout< v3(arr+2, arr+8); //将[arr+2,arr+8)的所有数据给v3初始化
cout<<"此时容器中的数据分别时:";
for(auto val:v3)
{
cout< 5.5.2 迭代器
C++ Iterators(迭代器)
选代器可被用来访问一个容器类的所包函的全部元素,其行为像一个指针。举个例子,你可用一个选代器来实现对vector容器中所含元素的遍历。有这么几种选代器如下:
| 迭代器 | 描述 |
| input\_iterator | 提供读功能的向前移动选代器,它们可被进行增加(++),比较与解引用(*)。 |
| output\_iterator | 提供写功能的向前移动选代器,它们可被进行增加(++),比较与解引用(*)。 |
| forward\_iterator | 可向前移动的,同时具有读写功能的选代器。同时具有input和output选代器的功能,并可对选代器的值进行储 存。 |
| bidirectional\_iterator | 双向选代器,同时提供读写功能,同forward选代器,但可用来进行增加(++)或减少(--)操作。 |
| random\_iterator | 随机选代器,提供随机读写功能.是功能最强大的选代器,具有双向选代器的全部功能,同时实现指针般的算术 与比较运算。 |
| reverse\_iterator | 如同随机选代器或双向选代器,但其移动是反向的。(Either a random iterator or a bidirectional iterator that moves in reverse direction.)(我不太理解它的行为) |
第种容器类都联系于一种类型的选代器。第个STL算法的实现使用某一类型的选代器。举个例子,vector容器类就有一个random-access随机选代器,这也意味着其可以使用随机读写的算法。既然随机选代器具有全部其它选代器的特性,这也就是说为其它选代器设计的算法也可被用在vector容器上。
每个容器中,都定义了符合自己使用的迭代器类型
#include
#include //将头文件引入
using namespace std;
int main()
{
vector v1; //定义一个存放整数的vector 无参构造
//判空函数 empty
if(v1.empty())
{
cout<<"v1 is empty"< v2(5, "hello");
cout<<"此时容器中的数据分别时:";
for(auto val:v2)
{
cout< v3(arr+2, arr+8); //将[arr+2,arr+8)的所有数据给v3初始化
cout<<"此时容器中的数据分别时:";
for(auto val:v3)
{
cout<::iterator ptr; //定义了一个迭代器(指针)
cout<<"使用迭代器访问成员:";
for(ptr=v1.begin(); ptr!=v1.end(); ptr++)
{
cout<<*ptr<<" ";
}
cout<