在ELFK架构中加入kafka
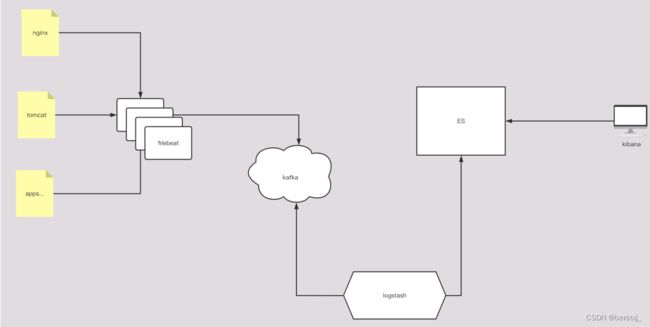
传统的ELFK架构中,filebeat到logstash这个过程中,由于logstash要进行日志的分析处理,而filebeat至进行日志的收集和发送,处理过程较为简单,所以当日志量非常巨大的时候,logstash会由于处理不及时导致日志或数据的丢失,这时候可以在filebeat和logstash之间加入kafka存储信息,在logstash处理不及时的时候,日志或数据不至于丢失。
kafka的安装和配置
直接下载解压安装即可
wget https://downloads.apache.org/kafka/3.3.1/kafka_2.12-3.3.1.tgz由于新版本的kafka自带zookeeper,作为实验使用,就不再单独下载zk了
kafka的配置如下
[root@VM-20-10-centos config]# cat server.properties |egrep -v "^#|^$"
broker.id=0
listeners=PLAINTEXT://10.0.20.10:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/tmp/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.retention.check.interval.ms=300000
zookeeper.connect=10.0.20.10:2181
zookeeper.connection.timeout.ms=18000
group.initial.rebalance.delay.ms=0这里主要需要配置的就是kafka的ip和port及zookeeper的ip和port
数据目录因为只是实验使用,就不再修改
zookeeper配置如下,基本采用默认
[root@VM-20-10-centos config]# cat zookeeper.properties |egrep -v "^#|^$"
dataDir=/tmp/zookeeper
clientPort=2181
maxClientCnxns=0
admin.enableServer=false配置好后启动应用,这里需要注意的是,先起zookeeper,再起kafka
启动脚本如下
[root@VM-20-10-centos bin]# nohup ./zookeeper-server-start.sh ../config/zookeeper.properties > zknohup.out 2>&1 &
[root@VM-20-10-centos bin]# nohup ./kafka-server-start.sh ../config/server.properties > kafkanohup.out 2>&1 &
创建一个topic
创建topic
[root@VM-20-10-centos bin]# ./kafka-topics.sh --create --topic testxj --bootstrap-server 10.0.20.10:9092
Created topic testxj.
修改topic分区数为3
[root@VM-20-10-centos bin]# ./kafka-topics.sh --bootstrap-server 10.0.20.10:9092 --topic testxj --alter --partitions 3
查看topic信息
[root@VM-20-10-centos bin]# ./kafka-topics.sh --describe --bootstrap-server 10.0.20.10:9092
Topic: testxj TopicId: 18qGviHQQ0WO1FZt0Z8qNg PartitionCount: 3 ReplicationFactor: 1 Configs:
Topic: testxj Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic: testxj Partition: 1 Leader: 0 Replicas: 0 Isr: 0
Topic: testxj Partition: 2 Leader: 0 Replicas: 0 Isr: 0修改filebeat和logstash配置进行测试
先不直接将kafka加入elfk中,而是先测试一下使用是否正常
filebeat使用标准输入,logstash输出到标准输出
filebeat配置
[root@VM-20-10-centos filebeat]# vim filebeat_2_kafka.yml
filebeat.inputs:
- type: stdin
output.kafka:
hosts:
- 10.0.20.10:9092
topic: "testxj"logstash配置
[root@VM-20-10-centos conf.d]# vim logstash_from_kafka.conf
input {
kafka {
bootstrap_servers => "10.0.20.10:9092"
topics => ["testxj"]
group_id => "testxj-logstash"
}
}
output{
stdout {}
}配置好后,直接前台启动进程进行测试
filebeat启动并向kafka写入aaaaaa和bbbbbb
[root@VM-20-10-centos filebeat]# filebeat -e -c ./filebeat_2_kafka.yml
。。。。
2023-01-20T00:24:13.736+0800 INFO [monitoring] log/log.go:144 Non-zero metrics in the last 30s {"monitoring": {"metrics": {"beat":{"cpu":{"system":{"ticks":10,"time":{"ms":4}},"total":{"ticks":20,"time":{"ms":8},"value":20},"user":{"ticks":10,"time":{"ms":4}}},"handles":{"limit":{"hard":100002,"soft":100001},"open":9},"info":{"ephemeral_id":"b783c9f8-6a5a-444c-b5a1-f73ef61f8cd7","uptime":{"ms":90024}},"memstats":{"gc_next":6031808,"memory_alloc":3031768,"memory_total":6498752,"rss":3366912}},"filebeat":{"events":{"added":1,"done":1},"harvester":{"open_files":0,"running":1}},"libbeat":{"config":{"module":{"running":0}},"output":{"events":{"acked":1,"batches":1,"total":1}},"outputs":{"kafka":{"bytes_read":1512,"bytes_write":376}},"pipeline":{"clients":1,"events":{"active":0,"published":1,"retry":1,"total":1},"queue":{"acked":1}}},"registrar":{"states":{"current":0}},"system":{"load":{"1":1.22,"15":0.63,"5":0.49,"norm":{"1":0.61,"15":0.315,"5":0.245}}}}}}
aaaaaaa
2023-01-20T00:24:35.872+0800 INFO kafka/log.go:53 producer/broker/0 state change to [open] on testxj/2
2023-01-20T00:24:43.736+0800 INFO [monitoring] log/log.go:144 Non-zero metrics in the last 30s {"monitoring": {"metrics": {"beat":{"cpu":{"system":{"ticks":10,"time":{"ms":1}},"total":{"ticks":20,"time":{"ms":4},"value":20},"user":{"ticks":10,"time":{"ms":3}}},"handles":{"limit":{"hard":100002,"soft":100001},"open":9},"info":{"ephemeral_id":"b783c9f8-6a5a-444c-b5a1-f73ef61f8cd7","uptime":{"ms":120024}},"memstats":{"gc_next":6031808,"memory_alloc":4337120,"memory_total":7804104,"rss":544768}},"filebeat":{"events":{"added":1,"done":1},"harvester":{"open_files":0,"running":1}},"libbeat":{"config":{"module":{"running":0}},"output":{"events":{"acked":1,"batches":1,"total":1}},"outputs":{"kafka":{"bytes_read":50,"bytes_write":355}},"pipeline":{"clients":1,"events":{"active":0,"published":1,"total":1},"queue":{"acked":1}}},"registrar":{"states":{"current":0}},"system":{"load":{"1":0.74,"15":0.61,"5":0.44,"norm":{"1":0.37,"15":0.305,"5":0.22}}}}}}
bbbbbbblogstash启动并从kafka中读取信息并向屏幕输出,可以看到信息读取成功
[root@VM-20-10-centos bin]# ./logstash -r -f ../conf.d/logstash_from_kafka.conf
Sending Logstash logs to /usr/local/logstash/logs which is now configured via log4j2.properties
[2023-01-20T00:24:00,706][WARN ][logstash.config.source.multilocal] Ignoring the 'pipelines.yml' file because modules or command line options are specified
[2023-01-20T00:24:01,268][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"6.4.2"}
[2023-01-20T00:24:03,696][INFO ][logstash.pipeline ] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50}
[2023-01-20T00:24:03,759][INFO ][logstash.pipeline ] Pipeline started successfully {:pipeline_id=>"main", :thread=>"#"}
[2023-01-20T00:24:03,805][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2023-01-20T00:24:03,983][INFO ][org.apache.kafka.clients.consumer.ConsumerConfig] ConsumerConfig values:
auto.commit.interval.ms = 5000
auto.offset.reset = latest
bootstrap.servers = [10.0.20.10:9092]
check.crcs = true
client.id = logstash-0
connections.max.idle.ms = 540000
enable.auto.commit = true
exclude.internal.topics = true
fetch.max.bytes = 52428800
fetch.max.wait.ms = 500
fetch.min.bytes = 1
group.id = testxj-logstash
heartbeat.interval.ms = 3000
interceptor.classes = []
internal.leave.group.on.close = true
isolation.level = read_uncommitted
key.deserializer = class org.apache.kafka.common.serialization.StringDeserializer
max.partition.fetch.bytes = 1048576
max.poll.interval.ms = 300000
max.poll.records = 500
metadata.max.age.ms = 300000
metric.reporters = []
metrics.num.samples = 2
metrics.recording.level = INFO
metrics.sample.window.ms = 30000
partition.assignment.strategy = [class org.apache.kafka.clients.consumer.RangeAssignor]
receive.buffer.bytes = 65536
reconnect.backoff.max.ms = 1000
reconnect.backoff.ms = 50
request.timeout.ms = 305000
retry.backoff.ms = 100
sasl.jaas.config = null
sasl.kerberos.kinit.cmd = /usr/bin/kinit
sasl.kerberos.min.time.before.relogin = 60000
sasl.kerberos.service.name = null
sasl.kerberos.ticket.renew.jitter = 0.05
sasl.kerberos.ticket.renew.window.factor = 0.8
sasl.mechanism = GSSAPI
security.protocol = PLAINTEXT
send.buffer.bytes = 131072
session.timeout.ms = 10000
ssl.cipher.suites = null
ssl.enabled.protocols = [TLSv1.2, TLSv1.1, TLSv1]
ssl.endpoint.identification.algorithm = null
ssl.key.password = null
ssl.keymanager.algorithm = SunX509
ssl.keystore.location = null
ssl.keystore.password = null
ssl.keystore.type = JKS
ssl.protocol = TLS
ssl.provider = null
ssl.secure.random.implementation = null
ssl.trustmanager.algorithm = PKIX
ssl.truststore.location = null
ssl.truststore.password = null
ssl.truststore.type = JKS
value.deserializer = class org.apache.kafka.common.serialization.StringDeserializer
[2023-01-20T00:24:04,043][INFO ][org.apache.kafka.common.utils.AppInfoParser] Kafka version : 1.1.0
[2023-01-20T00:24:04,043][INFO ][org.apache.kafka.common.utils.AppInfoParser] Kafka commitId : fdcf75ea326b8e07
[2023-01-20T00:24:04,205][INFO ][org.apache.kafka.clients.Metadata] Cluster ID: phZ-gSpnRyiDNlzsg7DbUw
[2023-01-20T00:24:04,211][INFO ][org.apache.kafka.clients.consumer.internals.AbstractCoordinator] [Consumer clientId=logstash-0, groupId=testxj-logstash] Discovered group coordinator 10.0.20.10:9092 (id: 2147483647 rack: null)
[2023-01-20T00:24:04,214][INFO ][org.apache.kafka.clients.consumer.internals.ConsumerCoordinator] [Consumer clientId=logstash-0, groupId=testxj-logstash] Revoking previously assigned partitions []
[2023-01-20T00:24:04,214][INFO ][org.apache.kafka.clients.consumer.internals.AbstractCoordinator] [Consumer clientId=logstash-0, groupId=testxj-logstash] (Re-)joining group
[2023-01-20T00:24:04,241][INFO ][org.apache.kafka.clients.consumer.internals.AbstractCoordinator] [Consumer clientId=logstash-0, groupId=testxj-logstash] Successfully joined group with generation 1
[2023-01-20T00:24:04,242][INFO ][org.apache.kafka.clients.consumer.internals.ConsumerCoordinator] [Consumer clientId=logstash-0, groupId=testxj-logstash] Setting newly assigned partitions [testxj-0, testxj-1, testxj-2]
[2023-01-20T00:24:04,265][INFO ][org.apache.kafka.clients.consumer.internals.Fetcher] [Consumer clientId=logstash-0, groupId=testxj-logstash] Resetting offset for partition testxj-0 to offset 20.
[2023-01-20T00:24:04,265][INFO ][org.apache.kafka.clients.consumer.internals.Fetcher] [Consumer clientId=logstash-0, groupId=testxj-logstash] Resetting offset for partition testxj-1 to offset 13.
[2023-01-20T00:24:04,265][INFO ][org.apache.kafka.clients.consumer.internals.Fetcher] [Consumer clientId=logstash-0, groupId=testxj-logstash] Resetting offset for partition testxj-2 to offset 0.
[2023-01-20T00:24:04,314][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
{
"@timestamp" => 2023-01-19T16:24:35.918Z,
"@version" => "1",
"message" => "{\"@timestamp\":\"2023-01-19T16:24:34.871Z\",\"@metadata\":{\"beat\":\"filebeat\",\"type\":\"doc\",\"version\":\"6.8.23\",\"topic\":\"testxj\"},\"prospector\":{\"type\":\"stdin\"},\"input\":{\"type\":\"stdin\"},\"beat\":{\"name\":\"VM-20-10-centos\",\"hostname\":\"VM-20-10-centos\",\"version\":\"6.8.23\"},\"host\":{\"name\":\"VM-20-10-centos\"},\"message\":\"aaaaaaa\",\"source\":\"\",\"offset\":0,\"log\":{\"file\":{\"path\":\"\"}}}"
}
{
"@timestamp" => 2023-01-19T16:24:49.772Z,
"@version" => "1",
"message" => "{\"@timestamp\":\"2023-01-19T16:24:48.766Z\",\"@metadata\":{\"beat\":\"filebeat\",\"type\":\"doc\",\"version\":\"6.8.23\",\"topic\":\"testxj\"},\"input\":{\"type\":\"stdin\"},\"beat\":{\"name\":\"VM-20-10-centos\",\"hostname\":\"VM-20-10-centos\",\"version\":\"6.8.23\"},\"host\":{\"name\":\"VM-20-10-centos\"},\"offset\":0,\"log\":{\"file\":{\"path\":\"\"}},\"message\":\"bbbbbbb\",\"source\":\"\",\"prospector\":{\"type\":\"stdin\"}}"
} 在ELFK中使用kafka
filebeat的配置修改为
[root@VM-12-8-centos filebeat]# egrep -v "#|^$" filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /data/shell/access.log
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 3
setup.kibana:
output.kafka:
hosts: ["10.0.20.10:9092"]
topic: "testxj"
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~logstash的配置修改为
[root@VM-20-10-centos conf.d]# cat logstash_to_elasticsearch.conf
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
kafka {
bootstrap_servers => "10.0.20.10:9092"
topics => ["testxj"]
group_id => "testxj-logstash"
}
}
filter {
grok {
match => { "message" => "%{IP:clientip} - (%{USERNAME:user}|-) \[%{HTTPDATE:timestamp}\] \"(%{WORD:request_verb} %{NOTSPACE:request} HTTP/%{NUMBER:httpversion}\s*|%{GREEDYDATA:request})\" %{NUMBER:status:int} %{NUMBER:body_sent:int} \"%{GREEDYDATA:http_referer}\" \"%{GREEDYDATA:http_user_agent}\" \"(%{IPV4:http_x_forwarded_for}|-)\"" }
remove_field => "message"
}
date {
match => [ "time_local", "dd/MMM/yyyy:HH:mm:ss Z" ]
}
geoip {
source => "clientip"
fields => ["city_name","country_name","ip"]
}
useragent {
source => "http_user_agent"
target => "acesss_useragent"
}
}
output {
elasticsearch {
hosts => ["http://10.0.20.10:9200"]
index => "nginx-accesslog-%{+YYYY.MM.dd}"
document_type => "nginx-accesslog"
template_overwrite => true
#user => "elastic"
#password => "changeme"
}
stdout {
codec =>rubydebug
}
}最后启动进程即可