SQL SERVER索引优化系列之一:工作原理&聚簇索引|非聚簇索引
摘自:http://crm.xingfa.com/HelpDesk/Archiver.asp?ThreadID=8587 感谢作者
我们来简单地看看SQL SERVER索引是如何工作的,关于索引的一些概念就不说了。
聚簇索引:
(图A)
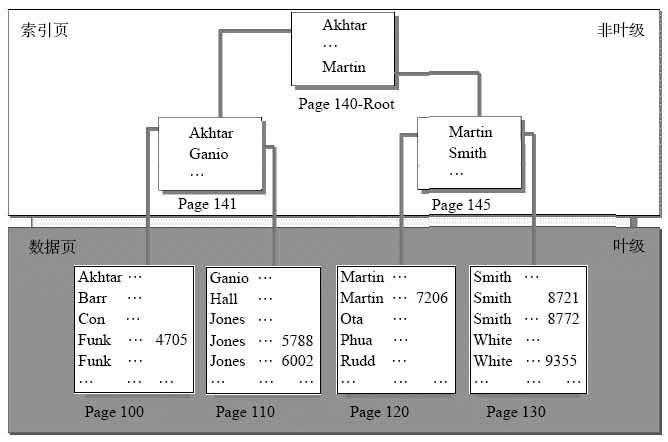
我们来看图A,聚簇索引的结构图。
数据页就是数据库里实际存储数据的地方,可以看到是按页1页1页存的。
假设那个列是”LastName”。
因为是聚集索引,所以它是按照顺序排下来的。可以看到,索引是一棵树,首先先看一下这棵树是怎么形成的。
先看Page100和Page110的最上面,由它们形成了Page141,Page141的第一条数据是Page100的第一条数据,Page141的最后一条数据是Page110的第一条数据。同理由Page120和Page130形成Page145,Page141和Page145形成根Page140.
好了,然后来看看它是如何查找数据的。
我们来找”Rudd”这个姓。
首先它会从根即Page140开始找,因为”Rudd”的值比”Martin”大(只要比较一下他们首字母就知道了,按26个字母顺序R排在M的后面),所以会往”Martin”的后面找,即找到Page145,然后在比较一下”Rudd”和”Smith”,”Rudd”比”Smith”小,所以会往左边找即Page120,然后在Page120逐行扫描下来直到找到”Rudd”。
如果不建索引的话,SQL SERVER会从第一页开始按顺序每页逐行扫描过去,直到找到”Rudd”。显然如果对于一个百万行的表来说,效率是极其低下的,如果建了索引,非常快就能找到。
非聚簇索引:
(图B)
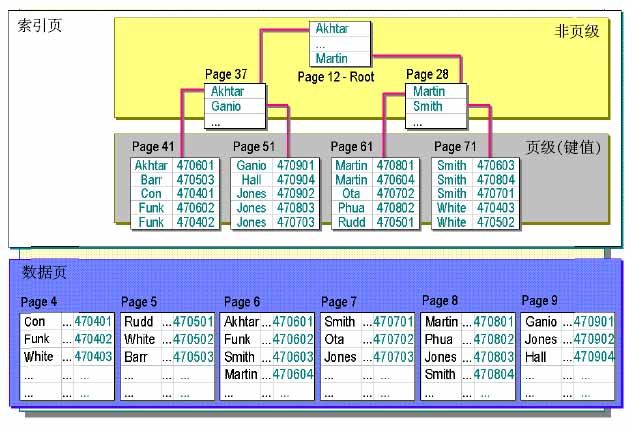
看图B,非聚簇索引的结构图。
聚簇索引和非聚簇索引的区别就是:聚簇索引的数据物理存储顺序和索引顺序一致的,也就是它的数据就是按顺序排下来的。非聚簇索引的数据存储是无序的,不按索引顺序排列。
从图B可以看到数据页里是无序的。那么它的索引是如何建立的呢?
再看图B,它是把这个索引列的数据复制了一份然后按顺序排下来,再建立索引。每行数据都有一个指针。
我们再来找”Rudd”.首先从索引页的根开始找,查找原理跟聚集索引是一样的。在索引页的Page61找到”Rudd”,它的指针是470501,然后在数据页的Page5找到470501,这个位置就是”Rudd”在数据库中的实际位置,这样就找到了”Rudd”。
好了,索引的基本工作原理就是这样,可能实际上要复杂些。
在前面说过了索引能极大的提高数据的检索速度,那为什么不在每一个列上建索引呢?初学者可能会困惑这个问题,而且通常不知道哪些列该建索引,哪些不该建, 甚至于会把like模糊查询的列也作为索引列,其实like是不使用索引的,只有等于,大于,IN等操作符会使用索引。SQLSERVER对于数据的插入,更新和删除,都要更新相应的索引。这无疑会大大增加更新时间。另外,如果某个数据页已满,这时如果要在该页插入数据时,就会造成页分裂产生碎片(后面还会说到),而影响性能。所以仅当查询的性能比更新的性能更重要时才建索引。
考虑建索引的列
1. 主键
2. 外键
3. 频繁检索的列和按排序顺序频繁检索的列
通常where 后面的条件引用的列都是考虑建索引的列,模糊查询除外(如like查询)
不考虑建索引的列
1.很少或从来不在查询中引用的列
2.只有两个或若干个值的列(比如只有男和女两个值的列)
3.小表(行数很少的表,这时候SQL SERVER花费在索引上的时间比直接扫描表的时间还更长)
SQL SERVER对于建立索引的列,都要付出一定的代价来维护这个索引。另外SQLSERVER会自动分析是否使用该列的索引,比如对于只有男和女两个值的列,如果给它建立索引,SQLSERVER自行分析后,会认为改列使用索引查找的效率不大,因为返回结果集的百分比比较大,于是SQLSERVER会将统计数据记录下来,当下次查找该列时,就会根据该统计数据来决定是否要使用改列的索引。
对于返回结果集百分比比较大的列(比如有100万的数据,而查找的结果将返回50万),SQLSERVER就可能不会使用该列上的索引,而采用全表扫描的方法。可自行测试,插入2000条数据,有1999条数据是一样的,比如ForumID为2的有1999条,ForumID为3的只有一条,这时使用
SET SHOWPLAN_TEXT ON –显示执行计划,可查看查询语句使用了哪些索引
GO
SELECT * FROM Posts WHERE ForumID=2
会发现没有使用ForumID列的索引。
SELECT * FROM Posts WHERE ForumID=3
则使用了ForumID列的索引
进行大批量插入或更新应先删除索引最后再重建索引,避免每插入或更新一条数据时都要更新相应的索引,而影响更新速度。
复合索引(指两列或多列组成的索引,通常where后面由多个列组成的条件时,可以把这些列建成一个复合索引)
1) 只有当WHERE子句中指定索引键的第一列时才使用该索引。
例子:
CREATE INDEX Posts_INDEX
ON Posts(ThreadID,ForumID)
如果SELECT * FROM Posts WHERE ForumID=2 则查询不会使用Posts_INDEX索引
而 SELECT * FROM Posts WHERE ThreadID=10 则会使用Posts_INDEX索引
2) 索引不应过大(<= 8个字节为最好,int型相当于4个字节,SmallInt相当于2个字节)。
3) 首先定义最具唯一性的列(顺序不一样,索引是不一样的)
比如:A列有30%的数据是重复的,B列有10%的列是重复的,C列有25%的数据是重复的,这时候建立索引的列的顺序应当是 B C A
建立索引还有一个比较重要的选项:填充因子。下一篇继续。
建SQL SERVER索引的时候有一个选项,即Fillfactor(填充因子)。
这个可能很少人会去注意它,但它也是比较重要的。大家可能也都知道有这个东西,但是如何去使用它,可能会比较迷糊。另外,即使你理解了它的原理,也不一定能使用好它,这个还要具体分析索引字段的更新频率等等。
记得看书知道有这么个东西,但是都是看的迷迷糊糊的,不知道干吗的,好象设置不设置都一样的。其实,像索引这些东西,当数据达到几十万上百万的时候,它的效果就表现的很明显。
填充因子定义:索引中叶级页的数据充满度。它的作用:当系统新建或重建索引时,在每一个索引页上预先留出一部分空间。使得系统在新增索引信息时能够保持索引页不分裂。它的目的是使索引的页分裂最小并对性能微调。
(图A)
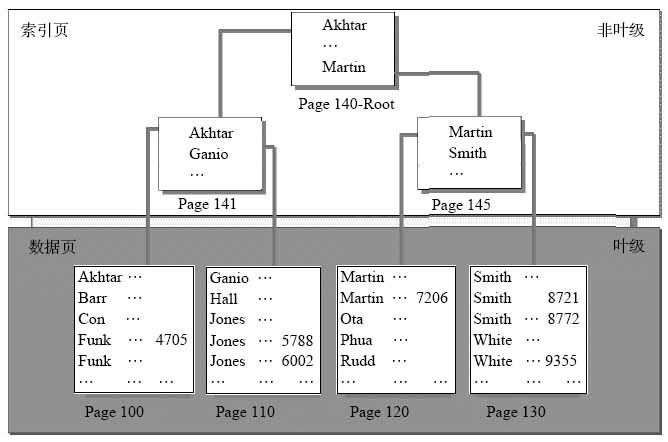
看图A,通过前面说的我们知道数据是按页存的,根据定义,填充因子是指图A中的Page100(Page110,Page120,Page130)的数据的充满度。如果按默认,填充因子是为0(0和100%是一样的),即完全充满。如果设置60%,则Page100的数据只充满空间的60%,会有40%的剩余空间。
填充因子只在创建索引时执行;索引创建后,当表中进行数据的添加、删除或更新时,不会保持填充因子。即创建索引完后添加数据,比如添加”COM”,则会添加在Page100的”CON”的前面,此时Page100的剩余空间将小于40%。因为充满度只有60%,所以”Barr”和”CON”之间会有空隙,所以”COM”将直接插入他们之间,不会照成数据移动和页分裂。如果充满度是100%即整页充满数据,则会照成”CON”及它后面的数据都向后移动1位,然后在”CON”前面插入”COM”,而Page100会大约一半的行(后半部)移到新页中以便为新行腾出空间(这种重组称为页拆分。页拆分会降低性能并使表中的数据存储产生碎片.),在这些移动的过程中一方面速度明显下降,另一方面会产生碎片。添加完数据后要使填充因子继续保持60%则需要重建索引。
有人将填充因子比喻成下面这个例子:
为了给一个班的10个同学排一下顺序,我们可以给每一位同学一个编号,如:
a. 从1,2,3,4,5,6,7,9,10。这时,我们说填充因子是100.
此时,如果又来了新同学,而其排名要在中间某位置的话,我们就要改变许多个同学的号码,如新同学排第5位,就需要4号以后的同学号码都加1,再将新同学编为5号才行.
b.我们又可以给同学这样编号:1,3,5,7,9,11,13,15,17,19
也同样完成了顺序的排列.我们说这时填充因子是50%,此时如果来了新同学,又是排在第5位的话,那么我们只需将其号码编为8就行了.其它同学都不用变.
可见,填充因子大的时候,点用的号码空间小,耗费资源少,小的时候,占用资源加大,但操作方便,迅速.
填充因子大的时候,插入或修改记录后重新索引的工作会很大,磁盘IO操作增加,性能必然降低,但其占用空间小.填充因子小的时候,索引文件占用磁盘及内存空间相对要大,但是,系统本身重新索引所需IO操作减少,性能提高,只是多占用一些存储空间. 孰轻孰重要自已决定。
通常只有当不会对数据进行更改时(例如,在只读表中)才会使设置100%。另外,只有当在表中根据现有数据创建新索引,并且可以精确预见将来会对这些数据进行哪些更改时,将填充因子选项设置为另一个值才有用。所以填充因子不是很容易设置的。