Redis缓存机制(详解)
1.Redis 是什么?
*redis是*一个运行在内存上的key-value存储系统。是NoSQL数据库之一
2.缓存穿透,缓存击穿,缓存雪崩
/**缓存穿透*/
它会先查询Redis,Redis没有会查询数据库,数据库也没有这就是缓存穿透
业界主流解决方案:布隆过滤器布隆过滤器的使用步骤
布隆过滤器的使用步骤:
1.针对现有所有数据,生成布隆过滤器
2.在业务逻辑层,判断Redis之前先检查这个id是否在布隆过滤器中
3.如果布隆过滤器判断这个id不存在,直接返回
4.如果布隆过滤器判断id存在,在进行后面业务执行
/**缓存击穿*/
一个计划在Redis保存的数据,业务查询,查询到的数据Redis中没有,但是数据库中有
/**缓存雪崩*/
同一时间发生少量击穿是正常的,但是如果出现同一时间大量击穿现象就会造成缓存雪崩
大量缓存失效,导致请求都压在mysql上,mysql承担不了,非常可能导致异常
要想避免这种情况,就需要避免大量缓存同时失效
大量缓存同时失效的原因:通常是同时加载的数据设置了相同的有效期导致的
那么我们需要在设置有效期时添加一个随机数,大量数据就不会同时失效了,/**缓存使用原则*/
什么时候,什么样的数据能够保存在Redis中?
1.数据量不能太大
2.使用越频繁,Redis保存这个数据越值得
3.保存在Redis中的数据一般不会是数据库中频繁修改的
/**缓存淘汰策略*/
Redis将数据保存在内存中, 内存的容量是有限的
allkeys-random:所有数据中随机删除数据 3.Redis持久化策略有两种( RDB本质上就是数据库快照, AOF为(日志)备份 )
/**Redis持久化*/
Redis将信息保存在内存。
内存的特征就是一旦断电,所有信息都丢失,对于Redis来讲,所有数据丢失,就需要从数据库从新查询所有数据,这个是慢的。
所以Redis支持了持久化方案,在当前服务器将Redis中的数据保存在本地硬盘上。
Redis持久化策略有两种:
1./**RDB:(Redis Database Backup)*/
RDB本质上就是数据库快照(就是当前Redis中所有数据转换成二进制的对象,保存在硬盘上)
默认情况下,会生成一个dump.rdb的文件
当Redis断电或宕机,需要恢复数据时,可以恢复成dump.rdb生成时的所有内容
我们可以在Redis的配置文件中添加如下配置信息
60表示秒数,既1分钟
5表示key被修改的次数
配置效果:1分钟内如果有5个key以上被修改,就启动rdb数据库快照程序
优点: 因为是整体Redis数据的二进制格式,数据恢复是整体恢复的
缺点:生成的rdb文件是一个硬盘上的文件,读写效率是较低的,如果突然断电,只能恢复最后一次生成的rdb中的数据
2./**AOF(Append Only File): */
AOF策略是将Redis运行过的所有命令(日志)备份下来
这样即使Redis断电,我们也可以根据运行过的日志,恢复为断电前的样子实际情况下,Redis非常繁忙时,我们会将 日志命令缓存之后,整体发送给备份,减少io次数以提高备份的性能和对Redis性能的影响。
我们可以在Redis的配置文件中添加如下配置信息
经过这个设置,就能保存运行过的指令的日志了,理论上任何运行过的指令都可以恢复。
优点: 相对RDB来讲,信息丢失的较少
缺点: 因为保存的是运行的日志,所以占用空间较大实际开发中RDB和AOF是可以同时开启的
4.Redis存储原理,Redis集群(主从复制、读写分离、哨兵模式、哨兵集群、分片集群)
/**Redis存储原理*/
Redis将内存划分为16384个区域(类似hash槽)
将数据的key使用CRC16算法计算出一个值,取余16384
得到的结果是0~16383
将这个key保存在计算结果对应的槽位
再次查询这个key时,直接到这个槽位查找,效率很高
实际上这就是"散列表"
提高查询的效率
/**Redis集群*/
Redis最小状态是一台服务器
这个服务器的运行状态,直接决定Redis是否可用
如果它离线了,整个项目就会无Redis可用,系统会面临崩溃,为了防止这种情况的发生,我们可以准备一台备用机
1./**主从复制*/
也就是主机(master)工作时,安排一台备用机(slave)实时同步数据,万一主机宕机,我们可以切换到备机运行
缺点,这样的方案,slave节点没有任何实质作用,只要master不宕机它就和没有一样,没有体现价值
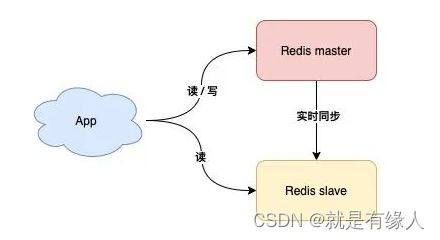
2./**读写分离*/
这样slave在master正常工作时也能分担Master的工作了
但是如果master宕机,实际上主备机的切换,实际上还是需要人工介入的,这还是需要时间的
那么如果想实现故障时自动切换,一定是有配置好的固定策略的
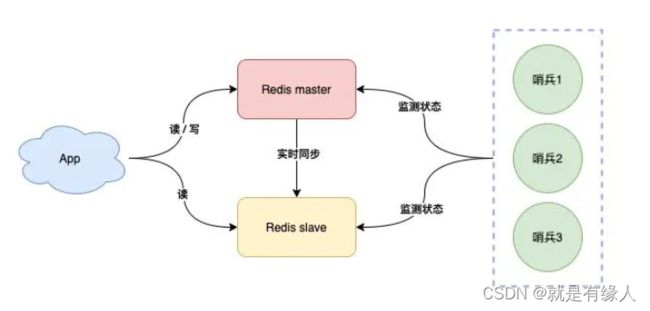
3./**哨兵模式*/
哨兵主要负责的就是三个任务:监控、故障自动切换和通知。
哨兵节点每隔固定时间向所有节点发送请求
如果正常响应认为该节点正常
如果没有响应,认为该节点出现问题,哨兵能自动切换主备机
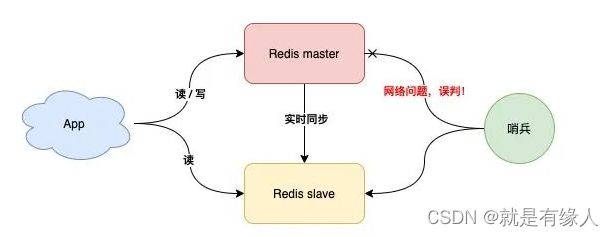
如果主机master下线,自动切换到备机运行,但是这样的模式存在问题。
但是如果哨兵判断节点状态时发生了误判,那么就会错误将master下线,降低整体运行性能。
4./**哨兵集群*/
我们可以将哨兵节点做成集群,由多个哨兵投票决定是否下线某一个节点
哨兵集群中,每个节点都会定时向master和slave发送ping请求
如果ping请求有2个(集群的半数节点)以上的哨兵节点没有收到正常响应,会认为该节点下线
5./**分片集群*/
当业务不断扩展,并发不断增高时
只有一个节点支持写操作无法满足整体性能要求时,系统性能就会到达瓶颈
这时我们就要部署多个支持写操作的节点,进行分片,来提高程序整体性能哨兵集群
读写分离
哨兵误判
5.持久化的意义?
redis持久化的意义,在于故障恢复,数据恢复,也可以归类到高可用的一个环节里面去。
6.edis的高性能如何保证?
线程模型,数据结构,持久化,网络模型
7.Redis的高可靠性如何保证?
持久化,主从复制,哨兵机制
8.Redis的高可扩展性如何保证?
数据分片+负载均衡