缩小模拟与现实之间的差距:使用 NVIDIA Isaac Lab 训练 Spot 四足动物运动
目录
在 Isaac Lab 中训练四足动物的运动能力
目标
观察和行动空间
域随机化
网络架构和 RL 算法细节
先决条件
用法
训练策略
执行训练好的策略
结果
使用 Jetson Orin 在 Spot 上部署经过训练的 RL 策略
先决条件
Jetson Orin 上的硬件和网络设置
Jetson 上的软件设置
运行策略
开始开发您的自定义应用程序
由于涉及复杂的动力学,为四足动物开发有效的运动策略对机器人技术提出了重大挑战。训练四足动物在现实世界中上下楼梯可能会损坏设备和环境。因此,模拟器在学习过程中在安全性和时间限制方面都发挥着关键作用。
利用深度强化学习 (RL) 在模拟环境中训练机器人可以更有效、更安全地执行复杂任务。然而,这种方法带来了一个新的挑战:如何确保在模拟中训练的策略无缝转移到现实世界。换句话说,我们如何缩小模拟与现实 (sim-to-real) 之间的差距?
缩小模拟与现实之间的差距需要高保真、基于物理的模拟器进行训练,高性能人工智能计算机(如NVIDIA Jetson)以及具有关节级控制的机器人。强化学习研究员套件是与波士顿动力公司、NVIDIA和人工智能研究所合作开发的,它将这些功能结合在一起,实现四足动物从虚拟世界到现实世界的无缝部署。它包括一个关节级控制 API,用于Spot 四足机器人控制机器人的移动方式,安装硬件用于 NVIDIA Jetson AGX Orin有效载荷以运行策略(AGX Orin 单独出售),以及NVIDIA Isaac Lab中 Spot 的模拟环境。
Isaac Lab 是一款轻量级参考应用程序,基于NVIDIA Isaac Sim平台构建,专门针对大规模机器人学习进行了优化。它利用基于 GPU 的并行化进行大规模并行物理模拟,以提高最终策略性能并减少机器人强化学习的训练时间。凭借其高保真物理和域随机化功能,Isaac Lab 弥合了模拟与现实之间的差距,实现了将训练好的模型无缝部署到物理机器人上,零样本。要了解更多信息,请参阅使用 NVIDIA Isaac Sim 4.0 和 NVIDIA Isaac Lab 通过 AI 和模拟增强机器人工作流程。
这篇文章解释了如何在 Isaac Sim 和 Isaac Lab 中为 Spot 创建运动 RL 策略,并使用 RL Researcher Kit 中的组件将其部署到硬件上。
在 Isaac Lab 中训练四足动物的运动能力
本节介绍如何在 Isaac Lab 中训练运动 RL 策略。
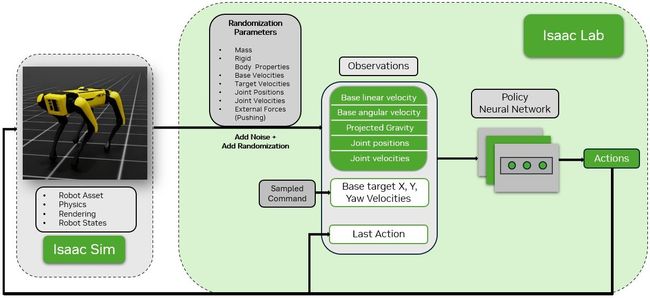
图 1. 从 Isaac Sim 到 Isaac Lab 的运动策略训练框架的工作流程
目标
训练 Spot 机器人在平坦地形上行走时跟踪目标 x、y 和偏航基准速度。
观察和行动空间
每次重置时目标速度都会随机化,并与图 1 中所示的其他观察结果一起提供。动作空间仅包括 12 个 DOF 关节位置,这些位置作为参考关节位置传递给低级关节控制器。
域随机化
各种参数在关键训练阶段都会被随机化,如图 1 中的随机化参数所示。这些随机化有助于模型确保在实际部署中的稳健性。此过程称为域随机化。
网络架构和 RL 算法细节
运动策略的结构为一个三层的多层感知器 (MLP),包含 [512, 256, 128] 个神经元,并使用RSL-rl的近端策略优化 (PPO) 算法进行训练,该算法针对 GPU 计算进行了优化。
先决条件
为了训练运动策略,您需要以下内容:
- 配备 NVIDIA RTX GPU 的系统。有关详细的最低规格,请参阅Isaac Sim 文档。
- NVIDIA Isaac Sim、Isaac Lab和RSL-rl。
用法
本节介绍如何训练策略、重放策略并检查结果。
训练策略
cd ./isaaclab.sh -p source/standalone/workflows/rsl_rl/train.py --task Isaac-Velocity-Flat-Spot-v0 --num_envs 4096 --headless --video --enable_cameras
|
--video --enable_cameras参数记录代理在训练期间的行为视频;因此,它是可选的。
执行训练好的策略
此步骤将播放训练好的模型,并将.pt 策略导出到日志目录中的导出文件夹中的.onnx。
cd ./isaaclab.sh -p source/standalone/workflows/rsl_rl/play.py --task Isaac-Velocity-Flat-Spot-v0 --num_envs 64
|
结果
视频 1 演示了 Spot 机器人上训练好的策略。机器人能够按照目标 x、y 和偏航速度在平坦的地形上行走。通过 4,096 个环境和 15,000 次迭代,相当于在 NVIDIA RTX 4090 GPU 上进行大约 4 小时的训练时间,我们实现了每秒 85,000 到 95,000 帧 (FPS) 的训练速度。
视频 1. 在 Isaac Lab 模拟中对 Spot 机器人进行训练后的策略测试
使用 Jetson Orin 在 Spot 上部署经过训练的 RL 策略
将模拟训练的模型部署到现实世界以用于机器人应用会带来多项挑战,包括实时控制、安全约束和其他现实条件。Isaac Lab 的精确物理和域随机化功能可以将模拟训练的策略部署到 Jetson Orin zero shot 上的真实 Spot 机器人上,从而在虚拟和现实世界中实现类似的性能。
图 2 展示了真实的 Spot 机器人框架策略部署。策略神经网络在真实机器人上加载并推理。使用 Boston Dynamics State API 计算与模拟中相同的观测值。
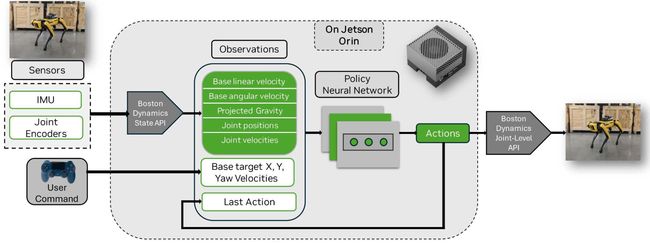
图2. Real Spot机器人框架策略部署
将训练好的模型传输到 Spot 机器人需要将模型部署到边缘并以低延迟和高频率控制机器人。NVIDIA Jetson AGX Orin高性能计算能力和低延迟 AI 处理可确保快速推理和响应时间,这对于现实世界的机器人应用至关重要。模拟策略可以直接部署进行推理,从而简化部署过程。
先决条件
部署需要以下内容:
- 使用以太网端口、电源线和安装支架将 Jetson Orin 连接并配置为自定义有效载荷的 Spot 机器人。按照提供的设置说明进行操作。
- 来自 Spot RL Researcher Kit 的部署代码和Spot Python SDK 。
- 通过蓝牙连接到 Jetson Orin 的 PS4 Gamepad 控制器。
- 外部 PC 通过 SSH 进入 Jetson 并运行代码。
- 来自 Isaac Lab 的训练模型和配置文件。
Jetson Orin 上的硬件和网络设置
- 在装有 Ubuntu 22.04 的外部 PC 上安装SDK 管理器。
- 按照如何使用 SDK 管理器刷新 L4T BSP的说明,使用SDK管理器刷新 Jetson Orin 和 JetPack 6。完成后重新启动。
- 将 Jetson Orin 连接到显示端口、键盘和鼠标。
- 使用步骤2中设置的用户名和密码登录Jetson Orin。
- 为了实现 Jetson Orin 与 Spot 之间的通信,请手动设置 Jetson Orin 上以太网端口的有线网络配置。阅读选择 IP 地址的说明。
- 转到设置->网络->有线-> + 添加 IPv4(路由)下的信息:地址 - Jetson IP 地址(我们选择 192.168.50.5)、网络掩码 - 255.255.255.0,以及默认网关 -192.168.50.3
- 单击添加按钮
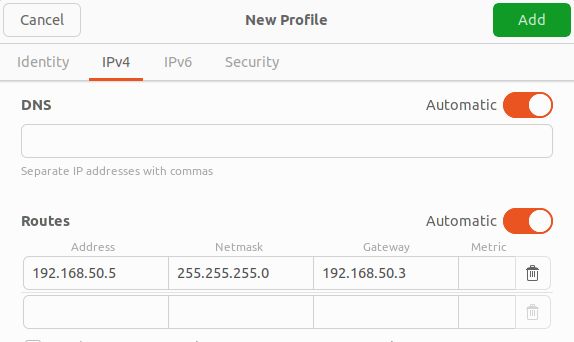
图 3. Jetson Orin 有线网络配置
Jetson 上的软件设置
首先,将模拟训练的策略从 .pt 转换为 .onnx,并导出环境配置。这在用于训练的 PC 上完成。
cd ./isaac_lab.sh -p source/standalone/workflows/rsl_rl/play.py --task Isaac-Velocity-Flat-Spot-v0
|
结果将位于模型训练日志目录中的导出文件夹中。该文件夹包含 env_cfg.json 和 .onnx 文件。
1. 在训练PC上创建一个文件夹,并将env.yaml文件和.onnx文件复制到该文件夹中。注意:env.yaml在params文件夹中,.onnx文件在训练日志目录的导出文件夹中。
2. 在训练 PC 上,使用 SSH 将步骤 1 中的文件夹复制到 Jetson Orin。确保 PC 和 Jetson 处于同一网络,例如现场本地 wifi。在 PC 的终端上,运行以下命令:
scp -P 20022 -r /path/to/folder/* orinusername@network_IP:
|
3. 接下来,从主目录在 Orin 的终端上运行以下命令:
mkdir spot-rl-deployment && cd spot-rl-deployment && mkdir models
git clone https://github.com/boston-dynamics/spot-rl-example.git
cd spot-rl-example && mkdir external && cd external && mkdir spot_python_sdk
|
4.下载带有联合级别 API 的Spot Python SDK,并将内容解压到步骤 3 中的 spot_python_sdk 文件夹中。
5.安装部署代码依赖项:
cd ~/spot-rl-deployment/spot-rl-example
sudo apt update
sudo apt install python3-pip
cd external/spot_python_sdk/prebuilt
pip3 install bosdyn_api-4.0.0-py3-none-any.whl
pip3 install bosdyn_core-4.0.0-py3-none-any.whl
pip3 install bosdyn_client-4.0.0-py3-none-any.whl
pip3 install pygame
pip3 install pyPS4Controller
pip3 install spatialmath-python
pip3 install onnxruntime
|
6.将 env.yaml 文件转换为 env_cfg.json 文件:
cd ~/spot-rl-deployment/spot-rl-example/python/utils/
python env_convert.py
#input the path to the .yaml file e.g ~/env.yaml
#The file outputs a env_cfg.json file in the same directory as the .yaml file
|
7. 将步骤 6 中的 env_cfg.json 和步骤 2 中训练好的模型 policy.onnx 文件移到 models 文件夹中:
mv env_cfg.json policy.onnx ~/spot-rl-deployment/models
|
运行策略
1. 打开 Spot 电源,按下机器人背面的电机锁定按钮。确保 Jetson Orin 电源已打开。

图 4. Spot 的后面板
2. 在 Spot 平板电脑控制器上打开 Spot 应用程序。选择一个机器人,然后按照提示登录并操作 Spot。确保从平板电脑释放控制权以运行策略:打开电机状态菜单(电源图标),导航到高级设置,然后选择释放控制权。
3. 将 PC 连接到 Spot 本地 Wi-Fi,并从终端通过 SSH 连接到 Orin。Spot 将端口 20022 转发到其有效负载,因此可以通过打开与 Spot IP 和此端口的 SSH 连接来访问 Orin。IPv4 地址 192.168.50.3 是 Spot IP。
ssh e.g
ssh |
4. 使用以下方式将无线游戏手柄连接到 Orin bluetoothctl:
bluetoothctl
scan on // wait for devices populate ~5s
scan off
devices
|
在列出的设备中找到游戏手柄的 Mac 地址。将游戏手柄置于配对模式,按住 Select 和 PlayStation 按钮约 5 秒钟,然后继续bluetoothctl。如果在完成后续步骤之前退出配对模式,您可能需要重复此过程。
trust {MAC}
pair {MAC}
connect {MAC}
exit
|
5. 运行 RL 策略:
cd ~/spot-rl-deployment/spot-rl-example/python
python spot_rl_demo.py /spot-rl-deployment/models --gamepad-config ./gamepad_config.json
|
出现提示时输入 Spot 的用户名和密码。Spot 会站立,但策略不会接管,直到您按下 Enter 键。现在,您可以使用 Gamepad 驱动机器人。再次按下 Enter 键,让 Spot 安静地坐下并退出。
6. 使用PS4游戏手柄控制。
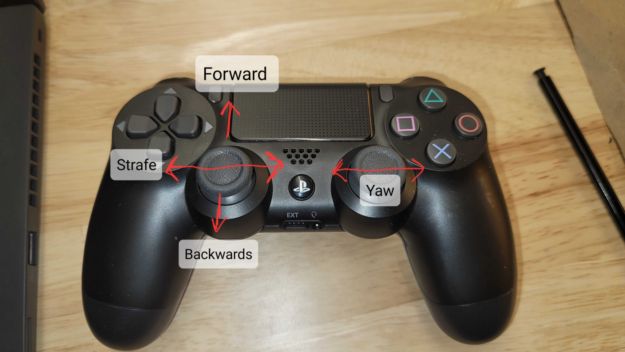
图 5. 用户可以使用游戏手柄控制器驾驶 Spot
使用左操纵杆进行 x、y 移动,右操纵杆进行旋转,如 Gamepad 图所示。请注意,使用其他 Gamepad(例如 PS5 控制器)将需要不同的轴映射。这指的是根据 pygame 的轴索引。可以使用来自的axis_mapping脚本打印每个轴的值,以确定不同控制器的正确映射。 test_controller.py~/spot-rl-deployment/spot-rl-example/python/utils/test_controller.py
7. 使用游戏手柄配置选项运行策略:
python spot_rl_demo.py ~/spot-rl-deployment/models --gamepad-config /home/gamepad_config.json
|
视频 2 展示了经过模拟训练后真实的 Spot 机器人的运行情况。
视频 2. Spot 机器人使用 NVIDIA Isaac Lab 的训练进行行走
开始开发您的自定义应用程序
Spot RL Researcher Kit 中提供的代码库是您在模拟中创建自己的自定义 RL 任务并将其部署到硬件的起点。要构建自定义应用程序,您可以通过添加自己的机器人模型、环境、奖励函数、课程学习、域随机化等来修改和扩展当前代码库。
有关如何使用 Isaac Lab 为您的特定任务训练策略的详细指导,请参阅文档。在其他机器人上部署训练好的策略特定于机器人架构;但是,如果 Spot 用户的应用程序需要额外的观察,他们可以修改当前的部署代码。
获取强化学习研究人员套件和 Spot 机器人并开始开发您的自定义应用程序。