LLM大模型学习:LLM大模型推理加速
文 Mia / 叶娇娇 推理优化部署、推理加速技术是现在,尤其在大模型时代背景之下,消费级 GPU 和边端设备仍为主流的状况下。推理加速是实际工程落地的首要考虑因素之一,今天笔者来聊聊涉及到的可以实现大模型推理加速的技术。
目录
一、模型优化技术
二、模型压缩技术
三、硬件加速
四、GPU 加速
五、模型并行化和分布式计算技术
一、模型优化
学习常见的模型优化技术,如模型剪枝、量化、分片、蒸馏等,掌握相应的实现方法。
1.1 剪枝
模型通常是过参数的,即很多参数或者 neuron 是冗余的 (例如非常接近 0),因此我们可以移除这些参数来对模型进行压缩。
- 单个权重 (Weight) 剪枝 —— 非结构化
- 核内权重 (Intra Kernel Weight) 剪枝 / 核的稀疏化 —— 结构化
- 卷积核 (Kernel/ Filter) / 特征图 (Feature Map) / 通道 (Channel) 剪枝 —— 结构化
- 中间隐层 (Layer) 剪枝
网络剪枝大体上可以分为两个分支:
- unstructured pruning(非结构化剪枝)
- structured pruning(结构化剪枝)
unstructured pruning 是指对于 individual weights 进行 prune;structured pruning 是指对于 filter/channel/layer 的 prune。
对模型剪枝优化的整体流程如下:
- 训练:训练大型的过度参数化的模型,得到最佳网络性能,以此为基准;
- 修剪:根据特定标准修剪训练的大模型,即重新调整网络结构中的通道或层数等,来得到一个精简的网络结构;
- 微调:微调修剪的模型以重新获得丢失的性能,这里一般做法是将修剪后的大网络中的保留的(视为重要的)参数用来初始化修剪后的网络,即继承大网络学习到的重要参数,再在训练集上 finetune 几轮。
重要性判断
那么怎么判断哪些参数是冗余或者不重要的呢?对权重 (weight) 而言,我们可以通过计算它的 l1,l2 值来判断重要程度对 neuron 而言,我们可以给出一定的数据集,然后查看在计算这些数据集的过程中 neuron 参数为 0 的次数,如果次数过多,则说明该 neuron 对数据的预测结果并没有起到什么作用,因此可以去除。
为什么要剪枝?
那我们不禁要问,既然最后要得到一个小的 network,那为什么不直接在数据集上训练小的模型,而是先训练大模型?
- 解释一
一个比较普遍接受的解释是因为模型越大,越容易在数据集上找到一个局部最优解,而小模型比较难训练,有时甚至无法收敛。
- 解释二
2018 年的一个发表在 ICLR 的大乐透假设 (Lottery Ticket Hypothesis) 观察到下面的现象: [arxiv.org/abs/1803.03…]
首先看最左边的网络,它表示大模型,我们随机初始化它权重参数(红色)。然后我们训练这个大模型得到训练后的模型以及权重参数(紫色)。最后我们对训练好的大模型做剪枝得到小模型。
实际操作分析
前面提到模型剪枝可以从 weight 和 neuron 两个角度进行,下面就分别介绍实际可操作性:
- weight pruning
每个节点的输出和输出节点数都会变得不规则,这样一来有两个方面的问题:- 使用 Pytorch,Keras 实现起来不方便 - GPU 是对矩阵运算做加速,现在都变得不规则,看起来似乎 GPU 面对这种情况也无能为力。2016 年的一篇文章对 AlexNet 就做了这样的实验,实验结果是模型参数去掉了将近 90%,最后的准确率只降低了 2% 左右,说明 weight pruning 的确能够在保证模型准确率的同时减少了模型大小,but!最后实验发现模型计算的速度似乎并没有提速,甚至对有的结构的修改使得速度降低了。
- neuron pruning
删减 neuron 之后网络结构能够保持一定的规则,实现起来方便,而且也能起到一定的加速作用。
示例:
Optimum 是针对大模型(基于 transformer 的)视觉、语音、语音提出的框架,通过和 ONNX Runtime 的集成进行训练,为许多流行的 Hugging Face 模型提供了一个开放的解决方案,针对特定的硬件(Nvidia GPU、Intel)在微调大模型、训练与推理取得进步,可以将训练时间缩短 35% 或更多。使用方法参见: tps://[hf.co/docs/optimu…]
例如,可以使用 Optimum 支持的 Intel Neural Compressor 工具集对一些模型库进行剪枝优化,相关的剪枝详细说明可以参见文档 https:// : [github.com/intel/neura…]
1.2 量化
量化就是将这些连续的权值进一步稀疏化、离散化。进行离散化之后,相较于原来的连续稠密的值就可以用离散的值来表示了。
- less bits
一个很直观的方法就是使用更少 bit 来存储数值,例如一般默认是 32 位,那我们可以用 16 或者 8 位来存数据。
- weight clustering
最左边表示网络中正常权重矩阵,之后我们对这个权重参数做聚类,比如最后得到了 4 个聚类,那么为了表示这 4 个聚类我们只需要 2 个 bit,即用 00,01,10,11 来表示不同聚类。之后每个聚类的值就用均值来表示。这样的一个缺点就是误差可能会比较大。
- 感知量化训练 Quantization Aware Training (QAT)
- 训练后量化 Post-traning Quantization (PTQ) Static/ Dynamic
- 量化部署 Deployment of Quantization
特点
- 参数压缩
- 提升速度
- 降低内存
- 功耗降低
- 提升芯片面积
量化落地挑战
- 硬件支持程度
- 不同硬件支持的低比特指令不同
- 精度挑战
- 软件算法是否能加速
示例:
AutoGPT 库
Hugging Face 的 AutoGPT 库支持 GPTQ 量化 Transformer 支持的大模型.AutoGPTQ 代码库覆盖了大量的 transformers 模型,并且经集成了包括 CUDA 算子在内的最常用的优化选项。对于更多高级选项如使用 Triton 算子和(或)兼容注意力的算子融合,请查看 AutoGPTQ 代码库。感兴趣的朋友可以尝试,非常推荐! [github.com/PanQiWei/Au…]
使用 AutoGPT 量化大语言模型做测评,使用长度为 512 个词元的提示文本,并精确地生成 512 个新词元,在英伟达 A100-SXM4-80GB GPU 上运行,在表格里记录了不同算子的内存开销和推理性能,全面的、可复现的测评结果可以在下列链接取得: [github.com/huggingface…]
1.3 蒸馏
整个知识蒸馏过程中会用到两个模型:大模型(Teacher Net)和小模型(Student Net)。
具体方法是我们先用大模型在数据集上学习到收敛,并且这个大模型要学的还不错,因为后面我们要用大模型当老师来教小模型学习嘛,如果大模型本身都没学好还教个锤子,对吧?
我们以 MNIST 数据集为例,假设大模型训练好了,现在对于一张数字为 “1” 的图像,大模型的输出结果是由 0.7 的概率是 1, 0.2 的概率是 7, 0.1 的概率是 9,这是不是有一定的道理?相比如传统的 one-hot 格式的 label 信息,这样的 label 包含更多的信息,所以 Student Net 要做的事情就是对于这张数字为 “1” 的图像,它的输出结果也要尽量接近 Teacher Net 的预测结果。
那 Student Net 到底如何学习呢?首先回顾一下在多类别分类任务中,我们用到的是 softmax 来计算最终的概率。
但是这样有一个缺点,因为使用了指数函数,如果在使用 softmax 之前的预测值是 x1=100, x2=10, x3=1, 那么使用 softmax 之后三者对应的概率接近于 y1=1, y2=0, y3=0,那这和常规的 label 无异了,所以为了解决这个问题就引入了一个新的参数 T, 称之为 Temperature。
1.4 结构设计 Architecture Design
- Low Rank Approximation (低秩近似)
但是低秩近似之所以叫低秩,是因为原来的矩阵的秩最大可能是 min (M,N), 而新增一层后可以看到矩阵 U 和 V 的秩都是小于等于 K 的,我们知道 rank (AB)≤min (rank (A), rank (B)), 所以相乘之后的矩阵的秩一定还是小于等于 K。那么这样会带来什么影响呢?那就是原先全连接层能表示更大的空间,而现在只能表示小一些的空间了。
而低秩近似的原理就是在两个全连接层之间再插入一层 K。是不是很反直观?插入一层后,参数还能变少?
- Depthwise Separable Convolution
首先看一下标准卷积所需要的参数量。输入数据由两个 6_6 的 feature map 组成,之后用 4 个大小为 3_3 的卷积核做卷积,最后的输出特征图大小为 4_4_4。每个卷积核参数数量为 2_3_3=18, 所以总共用到的参数数量为 4*18=72。
而 Depthwise Separable 卷积分成了两步。
首先是输入数据的每个通道只由一个二维的卷积核负责,即卷积核通道数固定为 1,而不是像上面那样,每个卷积核的通道数和输入通道数保持一致。这样最后得到的输出特征图的通道数等于输入通道数。
因为第一步得到的输出特征图是用不同卷积核计算得到的,所以不同通道之间是独立的,因此我们还需要对不同通道之间进行关联。为了实现关联,在第二步中使用了 1_1 大小的卷积核,通道数量等于输入数据的通道数量。另外 1_1 卷积核的数量等于预期输出特征图的通道数,在这里等于 4。最后我们可以得到和标准卷积一样的效果,而且参数数量更少:3_3_2+(1_1_2)*4=26。
二、模型压缩
模型压缩和量化技术:需要掌握模型压缩和量化技术,如低秩分解、矩阵分解、哈希表、矩阵量化等,以及它们在减少模型计算量和内存占用方面的作用。
模型压缩算法能够有效降低参数冗余,从而减少存储占用、通信带宽和计算复杂度,有助于深度学习的应用部署,具体可划分为如下几种方法(量化、剪枝与 NAS 是主流方向):
- 线性或非线性量化:1/2bits, INT4, INT8, FP16 和 BF16 等;
- 结构或非结构剪枝:Sparse Pruning, Channel pruning 和 Layer drop 等;
- 网络结构搜索 (NAS: Network Architecture Search):ENAS、Evolved Transformer、NAS FCOS、NetAdapt 等离散搜索,DARTS、AdaBert、Proxyless NAS、FBNet 等可微分搜索,SPOS、FairNAS、BigNAS、HAT、DynaBert 与 AutoFormer 等 One-shot 搜索;
- 其他:权重矩阵的低秩分解、知识蒸馏与网络结构精简设计(Mobile-net, SE-net, Shuffle-net, PeleeNet, VoVNet, MobileBert, Lite-Transformer, SAN-M)等;
三、硬件加速
了解常见的硬件加速技术,如 ASIC、FPGA、GPU 等,了解它们的特点、优缺点和使用方法。
AI 芯片目前三种方案。GPU 目前被英伟达和 AMD 牢牢把控。ASIC 目前最火,TPU、NPU 等属于 ASIC 范畴。
FPGA 的并行处理能力应该是大于 GPU 的,GPU 主要优势在计算,而且用起来也比 FPGA 方便,还是偏软件的思维。FPGA 还是硬件思维,计算能力强,控制也强,低延时,但是开发和应用都不如 GPU 方便。
总结:FPGA 比 GPU 更灵活,但开发周期更长,使用门槛更高,时延更低,功耗更低,并行度等于或大于 GPU,但是一些特定计算比如浮点计算不如 GPU。[感谢 FPGA 专家小方~]
四、GPU 加速
了解 GPU 的基本原理和使用方法,掌握 CUDA 和 cuDNN 等 GPU 加速工具的使用。
跟训练一样,推理的加速离不开算子融合这一方案。不过相对于训练而言,在推理上进行算子融合有更好的灵活性,主要体现有两点:
- 推理上的算子融合不需要考虑反向,所以 Kernel 开发过程中不需要考虑保存计算梯度所需要的中间结果;
- 推理过程允许预处理,我们可以对一些只需要一次计算便可重复使用的操作,提前算好,保留结果,每次推理时直接调用从而避免重复计算。
在 NVIDIA GPU 环境上,我们通过 CUDA Kernel 来执行大部分运算,矩阵乘法(GEMM),激活函数,softmax 等,一般来说每个操作都对应一次 Kernel 调用。但是每次 Kernel 调用都有一些额外开销,比如 gpu 和 cpu 之间的通信,内存拷贝等,因此我们可以将整个 Attention 的计算放进同一个 Kernel 实现,省略这些开销,在 Kernel 中也可以实现一些 Attention 专用的优化。比如 Facebook 的 xformers 库就为各种 Attention 变种提供了高效的 CUDA 实现。主流的推理库也基本都自带了高效的 Kernel 实现。
在推理侧,我们可以进行不少的算子融合,这里给出的是我们在 Transformer 模型中常见的一些算子融合的 pattern 以及实现相关 pattern 所需要用到的工具。
举个例子,我们单独列出矩阵乘法和卷积,是因为有一大类算子融合是围绕它们进行的,对于矩阵乘法相关的融合,我们可以考虑采用 cublas,cutlass,cudnn 这三个库;对于卷积,我们可以采用 cudnn 或者 cutlass。那么对于矩阵乘法的算子融合而言,在 Transformer 模型中,我们归纳为 gemm + elementwise 的操作,比如 gemm + bias, gemm + bias + 激活函数等,这一类的算子融合,我们可以考虑直接调用 cublas 或 cutlass 来实现。
五、模型并行化和分布式计算技术
随着模型规模增大,单台设备往往不足以满足推理需求,所以需要将模型和数据拆分为多个子模型、子集,并分布在多个 GPU 或计算节点上进行处理,能够有效提高整体推理速度。掌握模型并行化和分布式计算的基本原理和实现方法,了解模型并行化在大模型推理加速中的应用。
在大模型的训练和推理过程中,我们有以下几种主流的分布式并行方式:
- 数据并行(DataParallel):将模型放在多个 GPU 上,每个 GPU 都包含完整的模型,将数据集切分成多份,每个 GPU 负责推理一部分数据。
- 流水线并行(PipelineParallel):将模型纵向拆分,每个 GPU 只包含模型的一部分层,数据在一个 GPU 完成运算后,将输出传给下一个 GPU 继续计算。
- 张量并行(TensorParallel):将模型横向拆分,将模型的每一层拆分开,放到不同的 GPU 上,每一层的计算都需要多个 GPU 合作完成。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图
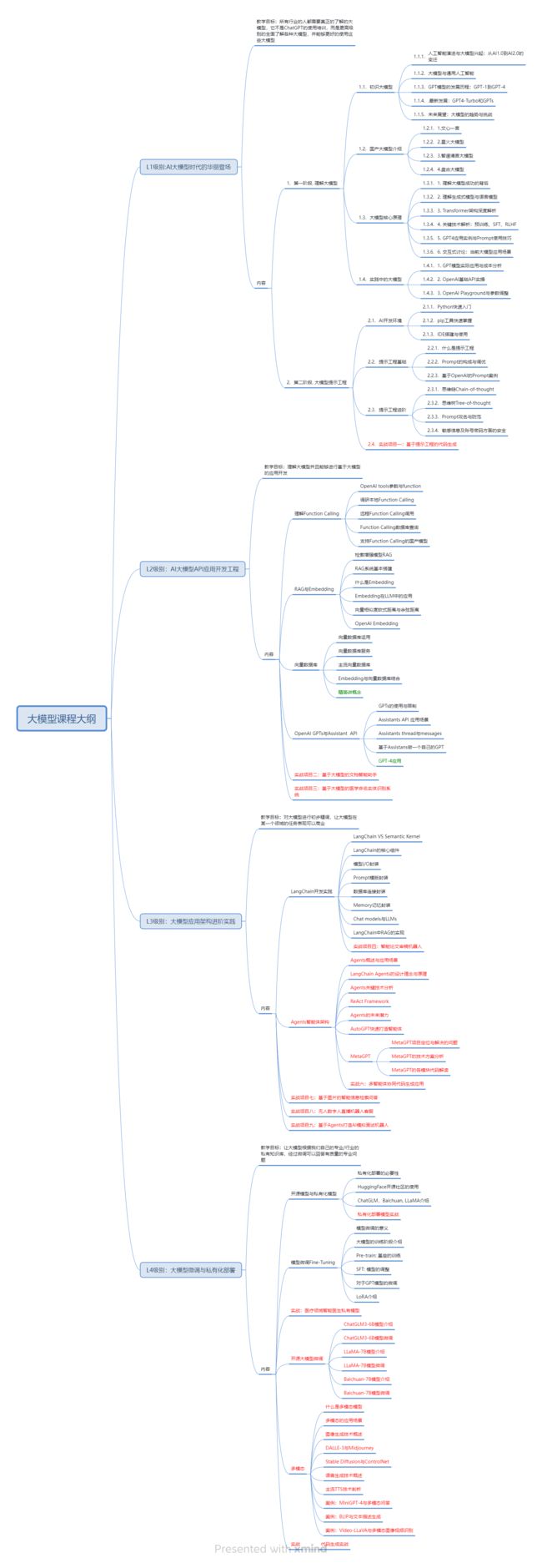
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。
(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。
4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

学会后的收获:
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】

本文转自 https://blog.csdn.net/m0_65555479/article/details/141993768?spm=1001.2014.3001.5501,如有侵权,请联系删除。