Paxos 算法详解(一)
前言
提到分布式算法,就不得不提 Paxos 算法,在过去几十年里,它基本上是分布式共识的代 名词,因为当前最常用的一批共识算法都是基于它改进的。比如,Fast Paxos 算法、 Cheap Paxos 算法、Raft 算法、ZAB 协议等等。
兰伯特提出的 Paxos 算法包含 2 个部分:
- 一个是 Basic Paxos 算法,描述的是多节点之间如何就某个值(提案 Value)达成共 识;
- 另一个是 Multi-Paxos 思想,描述的是执行多个 Basic Paxos 实例,就一系列值达成共 识
可因为兰伯特提到的 Multi-Paxos 思想,缺少代码实现的必要细节(比如怎么选举领导 者),所以在理解上比较难。
Basic Paxos 是 Multi-Paxos 思想的核心,说白了,Multi-Paxos 就是多执行 几次 Basic Paxos
思考题。
假设我们要实现一个分布式集群,这个集群是由节点 A、B、C 组成,提供只读 KV 存储服 务。你应该知道,创建只读变量的时候,必须要对它进行赋值,而且这个值后续没办法修 改。因此一个节点创建只读变量后就不能再修改它了,所以所有节点必须要先对只读变量的 值达成共识,然后所有节点再一起创建这个只读变量。
那么,当有多个客户端(比如客户端 1、2)访问这个系统,试图创建同一个只读变量(比 如 X),客户端 1 试图创建值为 3 的 X,客户端 2 试图创建值为 7 的 X,这样要如何达成 共识,实现各节点上 X 值的一致呢?带着这个问题,我们进入今天的学习。
三种角色:
为了帮助人们更好地理解 Basic Paxos 算法,兰伯特在 讲解时,也使用了一些独有而且比较重要的概念,提案、准备(Prepare)请求、接受 (Accept)请求、角色等等,其中最重要的就是“角色”。因为角色是对 Basic Paxos 中 最核心的三个功能的抽象,比如,由接受者(Acceptor)对提议的值进行投票,并存储接 受的值。
他们之间的关系如下:
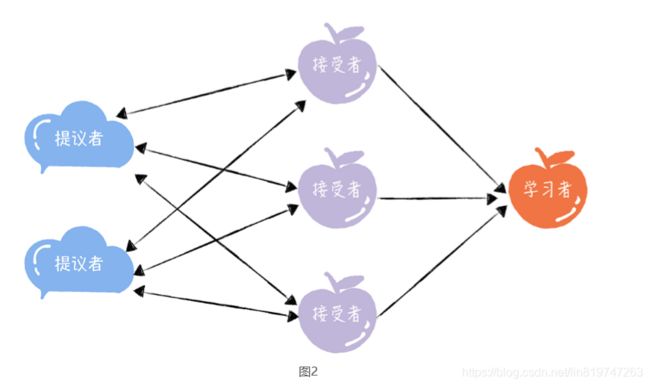
提议者(Proposer):提议一个值,用于投票表决。为了方便演示,你可以把图 1 中的 客户端 1 和 2 看作是提议者。但在绝大多数场景中,集群中收到客户端请求的节点,才 是提议者(图 1 这个架构,是为了方便演示算法原理)。这样做的好处是,对业务代码 没有入侵性,也就是说,我们不需要在业务代码中实现算法逻辑,就可以像使用数据库 一样访问后端的数据。
接受者(Acceptor):对每个提议的值进行投票,并存储接受的值,比如 A、B、C 三 个节点。 一般来说,集群中的所有节点都在扮演接受者的角色,参与共识协商,并接受 和存储数据。
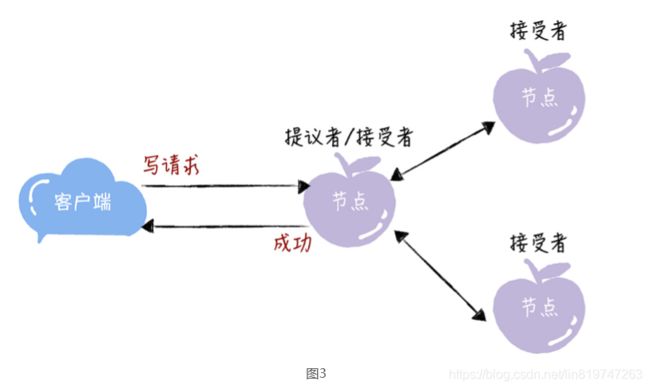
讲到这儿,你可能会有疑惑:前面不是说接收客户端请求的节点是提议者吗?这里怎么又是 接受者呢?这是因为一个节点(或进程)可以身兼多个角色。想象一下,一个 3 节点的集 群,1 个节点收到了请求,那么该节点将作为提议者发起二阶段提交,然后这个节点和另外 2 个节点一起作为接受者进行共识协商,就像下图的样子:
学习者(Learner):被告知投票的结果,接受达成共识的值,存储保存,不参与投票的 过程。一般来说,学习者是数据备份节点,比如“Master-Slave”模型中的 Slave,被 动地接受数据,容灾备份。
这三种角色,在本质上代表的是三种功能:
- 提议者代表的是接入和协调功能,收到客户端请求后,发起二阶段提交,进行共识协 商;
- 接受者代表投票协商和存储数据,对提议的值进行投票,并接受达成共识的值,存储保 存;
- 学习者代表存储数据,不参与共识协商,只接受达成共识的值,存储保存。
在 Basic Paxos 中,兰伯特也使用提案代表一个提议。不过在提案中, 除了提案编号,还包含了提议值。为了方便演示,我使用[n, v]表示一个提案,其中 n 为提 案编号,v 为提议值。
我想强调一下,整个共识协商是分 2 个阶段进行的(也就是我在 03 讲提到的二阶段提 交)。那么具体要如何协商呢?
我们假设客户端 1 的提案编号为 1,客户端 2 的提案编号为 5,并假设节点 A、B 先收到 来自客户端 1 的准备请求,节点 C 先收到来自客户端 2 的准备请求。
准备(Prepare)阶段
先来看第一个阶段,首先客户端 1、2 作为提议者,分别向所有接受者发送包含提案编号的 准备请求
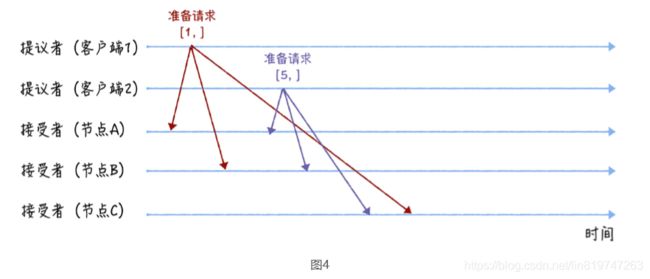
你要注意,在准备请求中是不需要指定提议的值的,只需要携带提案编号就可以了,这是很 多同学容易产生误解的地方。
接着,当节点 A、B 收到提案编号为 1 的准备请求,节点 C 收到提案编号为 5 的准备请求 后,将进行这样的处理:
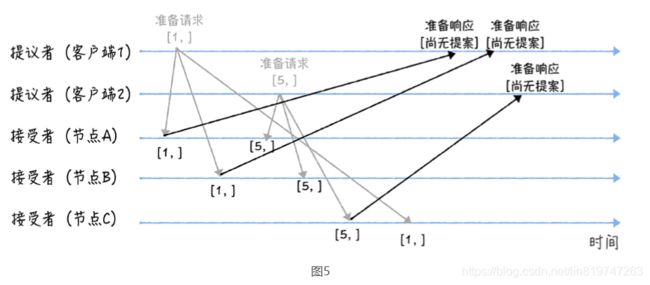
由于之前没有通过任何提案,所以节点 A、B 将返回一个 “尚无提案”的响应。也就是 说节点 A 和 B 在告诉提议者,我之前没有通过任何提案呢,并承诺以后不再响应提案编 号小于等于 1 的准备请求,不会通过编号小于 1 的提案。
节点 C 也是如此,它将返回一个 “尚无提案”的响应,并承诺以后不再响应提案编号小 于等于 5 的准备请求,不会通过编号小于 5 的提案。
另外,当节点 A、B 收到提案编号为 5 的准备请求,和节点 C 收到提案编号为 1 的准备请 求的时候,将进行这样的处理过程:
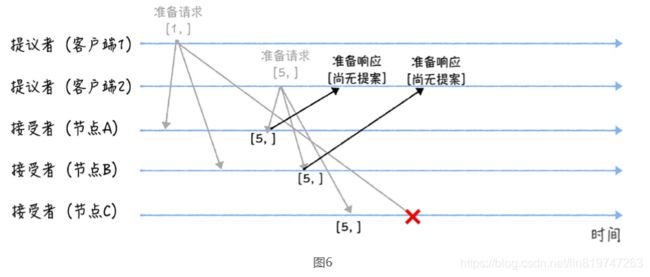
当节点 A、B 收到提案编号为 5 的准备请求的时候,因为提案编号 5 大于它们之前响应 的准备请求的提案编号 1,而且两个节点都没有通过任何提案,所以它将返回一个 “尚 无提案”的响应,并承诺以后不再响应提案编号小于等于 5 的准备请求,不会通过编号 小于 5 的提案。
当节点 C 收到提案编号为 1 的准备请求的时候,由于提案编号 1 小于它之前响应的准备 请求的提案编号 5,所以丢弃该准备请求,不做响应。
接受(Accept)阶段
第二个阶段也就是接受阶段,首先客户端 1、2 在收到大多数节点的准备响应之后,会分别 发送接受请求:
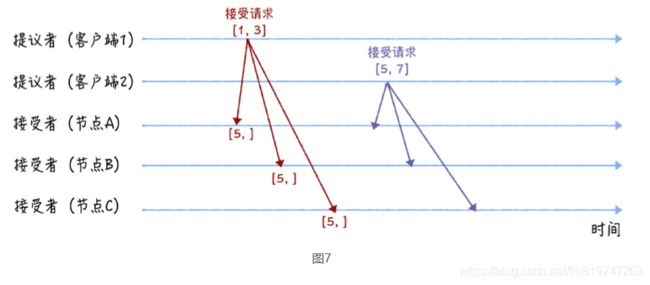
当客户端 1 收到大多数的接受者(节点 A、B)的准备响应后,根据响应中提案编号最大 的提案的值,设置接受请求中的值。因为该值在来自节点 A、B 的准备响应中都为空 (也就是图 5 中的“尚无提案”),所以就把自己的提议值 3 作为提案的值,发送接受 请求[1, 3]。
当客户端 2 收到大多数的接受者的准备响应后(节点 A、B 和节点 C),根据响应中提 案编号最大的提案的值,来设置接受请求中的值。因为该值在来自节点 A、B、C 的准备 响应中都为空(也就是图 5 和图 6 中的“尚无提案”),所以就把自己的提议值 7 作为 提案的值,发送接受请求[5, 7]。
当三个节点收到 2 个客户端的接受请求时,会进行这样的处理:
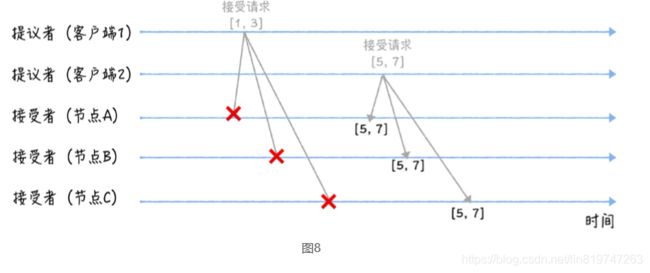
当节点 A、B、C 收到接受请求[1, 3]的时候,由于提案的提案编号 1 小于三个节点承诺 能通过的提案的最小提案编号 5,所以提案[1, 3]将被拒绝。
当节点 A、B、C 收到接受请求[5, 7]的时候,由于提案的提案编号 5 不小于三个节点承 诺能通过的提案的最小提案编号 5,所以就通过提案[5, 7],也就是接受了值 7,三个节 点就 X 值为 7 达成了共识。
通过上面的演示过程,你可以看到,最终各节点就 X 的值达成了共识。那么在这里我还想 强调一下,Basic Paxos 的容错能力,源自“大多数”的约定,你可以这么理解:当少于一半的节点出现故障的时候,共识协商仍然在正常工作