深入理解java虚拟机(十四)正确利用 JVM 的方法内联
在IntelliJ IDEA里面Ctrl+Alt+M用来拆分方法。选中一段代码,敲下这个组合,很easy。Eclipse也用类似的快捷键,使用 Alt+Shift+M。我讨厌长的方法,提起这个以下这种方法我就认为太长了:
public void processOnEndOfDay(Contract c) {
if (DateUtils.addDays(c.getCreated(), 7).before(new Date())) {
priorityHandling(c, OUTDATED_FEE);
notifyOutdated(c);
log.info("Outdated: {}", c);
} else {
if (sendNotifications) {
notifyPending(c);
}
log.debug("Pending {}", c);
}
}
首先,它有个条件推断可读性非常差。先无论它怎么实现的,它做什么的才最关键。我们先把它拆分出来:
public void processOnEndOfDay(Contract c) {
if (isOutDate(c)) {
priorityHandling(c, OUTDATED_FEE);
notifyOutdated(c);
log.info("Outdated: {}", c);
} else {
if (sendNotifications) {
notifyPending(c);
}
log.debug("Pending {}", c);
}
}
private boolean isOutDate(Contract c) {
return DateUtils.addDays(c.getCreated(), 7).before(new Date());
}
非常明显,这种方法不应该放到这里:
public void processOnEndOfDay(Contract c) {
if (c.isOutDate()) {
priorityHandling(c, OUTDATED_FEE);
notifyOutdated(c);
log.info("Outdated: {}", c);
} else {
if (sendNotifications) {
notifyPending(c);
}
log.debug("Pending {}", c);
}
}
注意到什么不同吗?我的IDE把isOutdated方法改成Contract的实例方法了,这才像样嘛。只是我还是不爽。这种方法做的事太杂了。一个分支在处理业务相关的逻辑priorityHandling,以及发送系统通知和记录日志。还有一个分支在则依据推断条件做系统通知,同一时候记录日志。我们先把处理过期合同拆分成一个独立的方法.
public void processOnEndOfDay(Contract c) {
if (c.isOutDate()) {
handleOutdated(c);
} else {
if (sendNotifications) {
notifyPending(c);
}
log.debug("Pending {}", c);
}
}
private void handleOutdated(Contract c) {
priorityHandling(c, OUTDATED_FEE);
notifyOutdated(c);
log.info("Outdated: {}", c);
}
有人会认为这样已经够好了,只是我认为两个分支并不正确称令人扎眼。handleOutdated方法层级更高些,而else分支更偏细节。软件应该清晰易读,因此不要把不同层级间的代码混到一起。这样我会更惬意:
public void processOnEndOfDay(Contract c) {
if (c.isOutDate()) {
handleOutdated(c);
} else {
stillPending(c);
}
}
private void stillPending(Contract c) {
if (sendNotifications) {
notifyPending(c);
}
log.debug("Pending {}", c);
}
private void handleOutdated(Contract c) {
priorityHandling(c, OUTDATED_FEE);
notifyOutdated(c);
log.info("Outdated: {}", c);
}
这个样例看起来有点装,只是事实上我想证明的是还有一个事情。尽管如今不太常见了,只是还是有些开发者不敢拆分方法,操心这种话影响执行效率。他们不知道JVM事实上是个很棒的软件(它事实上甩Java语言好几条街),它内建有很多很令人吃惊的执行时优化。首先 短方法更利于JVM判断。流程更明显, 作用域更短,副作用也更明显。假设是长方法JVM可能直接就跪了。第二个原因则更重要:
方法内联
假设JVM监測到一些小方法被频繁的运行,它会把方法的调用替换成方法体本身。比方说以下这个:
private int add4(int x1, int x2, int x3, int x4) {
return add2(x1, x2) + add2(x3, x4);
}
private int add2(int x1, int x2) {
return x1 + x2;
}
能够肯定的是执行一段时间后JVM会把add2方法去掉,并把你的代码翻译成:
private int add4(int x1, int x2, int x3, int x4) {
return x1 + x2 + x3 + x4;
}
注意这说的是JVM,而不是编译器。javac在生成字节码的时候是比較保守的,这些工作都扔给JVM来做。事实证明这种设计决策是很明智的:
JVM更清楚执行的目标环境 ,CPU,内存,体系结构,它能够更积极的进行优化。 JVM能够发现你代码执行时的特征,比方,哪个方法被频繁的执行,哪个虚方法仅仅有一个实现,等等。 旧编译器编译的.class在新版本号的JVM上能够获取更快的执行速度。更新JVM和又一次编译源码,你肯定更倾向于后者。
我们对这些如果做下測试。我写了一个小程序,它有着分治原则的最糟实现的称号。add128方法须要128个參数而且调用了两次add64方法——前后两半各一次。add64也类似,只是它是调用了两次add32。你猜的没错,最后会由add2方法来结束这一切,它是干苦力活的。有些数字我给省略了,免得亮瞎了你的眼睛:
public class ConcreteAdder {
public int add128(int x1, int x2, int x3, int x4, ... more ..., int x127, int x128) {
return add64(x1, x2, x3, x4, ... more ..., x63, x64) +
add64(x65, x66, x67, x68, ... more ..., x127, x128);
}
private int add64(int x1, int x2, int x3, int x4, ... more ..., int x63, int x64) {
return add32(x1, x2, x3, x4, ... more ..., x31, x32) +
add32(x33, x34, x35, x36, ... more ..., x63, x64);
}
private int add32(int x1, int x2, int x3, int x4, ... more ..., int x31, int x32) {
return add16(x1, x2, x3, x4, ... more ..., x15, x16) +
add16(x17, x18, x19, x20, ... more ..., x31, x32);
}
private int add16(int x1, int x2, int x3, int x4, ... more ..., int x15, int x16) {
return add8(x1, x2, x3, x4, x5, x6, x7, x8) + add8(x9, x10, x11, x12, x13, x14, x15, x16);
}
private int add8(int x1, int x2, int x3, int x4, int x5, int x6, int x7, int x8) {
return add4(x1, x2, x3, x4) + add4(x5, x6, x7, x8);
}
private int add4(int x1, int x2, int x3, int x4) {
return add2(x1, x2) + add2(x3, x4);
}
private int add2(int x1, int x2) {
return x1 + x2;
}
}
不难发现,调用add128方法最后一共产生了127个方法调用。太多了。作为參考,以下这有个简单直接的实现版本号:
public class InlineAdder {
public int add128n(int x1, int x2, int x3, int x4, ... more ..., int x127, int x128) {
return x1 + x2 + x3 + x4 + ... more ... + x127 + x128;
}
}
最后再来一个使用了抽象类和继承的实现版本号。127个虚方法调用开销是很大的。这些方法须要动态分发,因此要求更高,所以无法进行内联。
public abstract class Adder {
public abstract int add128(int x1, int x2, int x3, int x4, ... more ..., int x127, int x128);
public abstract int add64(int x1, int x2, int x3, int x4, ... more ..., int x63, int x64);
public abstract int add32(int x1, int x2, int x3, int x4, ... more ..., int x31, int x32);
public abstract int add16(int x1, int x2, int x3, int x4, ... more ..., int x15, int x16);
public abstract int add8(int x1, int x2, int x3, int x4, int x5, int x6, int x7, int x8);
public abstract int add4(int x1, int x2, int x3, int x4);
public abstract int add2(int x1, int x2);
}
另一个实现:
public class VirtualAdder extends Adder {
@Override
public int add128(int x1, int x2, int x3, int x4, ... more ..., int x128) {
return add64(x1, x2, x3, x4, ... more ..., x63, x64) +
add64(x65, x66, x67, x68, ... more ..., x127, x128);
}
@Override
public int add64(int x1, int x2, int x3, int x4, ... more ..., int x63, int x64) {
return add32(x1, x2, x3, x4, ... more ..., x31, x32) +
add32(x33, x34, x35, x36, ... more ..., x63, x64);
}
@Override
public int add32(int x1, int x2, int x3, int x4, ... more ..., int x32) {
return add16(x1, x2, x3, x4, ... more ..., x15, x16) +
add16(x17, x18, x19, x20, ... more ..., x31, x32);
}
@Override
public int add16(int x1, int x2, int x3, int x4, ... more ..., int x16) {
return add8(x1, x2, x3, x4, x5, x6, x7, x8) + add8(x9, x10, x11, x12, x13, x14, x15, x16);
}
@Override
public int add8(int x1, int x2, int x3, int x4, int x5, int x6, int x7, int x8) {
return add4(x1, x2, x3, x4) + add4(x5, x6, x7, x8);
}
@Override
public int add4(int x1, int x2, int x3, int x4) {
return add2(x1, x2) + add2(x3, x4);
}
@Override
public int add2(int x1, int x2) {
return x1 + x2;
}
}
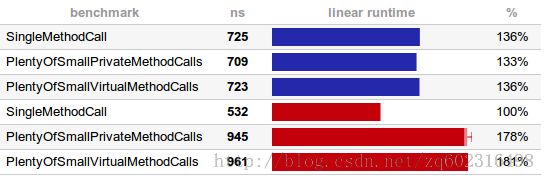
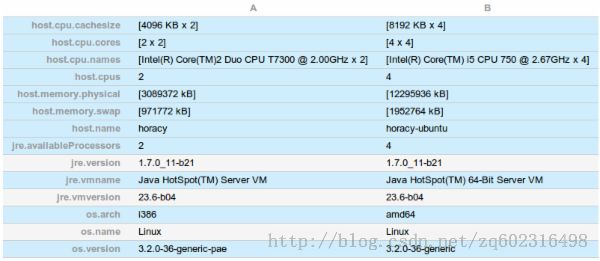
受到我的还有一篇关于@Cacheable 负载的文章的一些热心读者的鼓励,我写了个简单的基准測试来比較这两个过度分拆的ConcreteAdder和VirtualAdder的负载。结果出人意外,还有点让人摸不着头脑。我在两台机器上做了測试(红色和蓝色的),相同的程序不同的是第二台机器CPU核数很多其它并且是64位的:
详细的环境信息:
看起来慢的机器上JVM更倾向于进行方法内联。不仅是简单的私有方法调用的版本号,虚方法的版本号也一样。为什么会这样?由于JVM发现Adder仅仅有一个子类,也就是说每一个抽象方法都仅仅有一个版本号。假设你在执行时载入了还有一个子类(或者很多其它),你会看到性能会直线下降,由于无能再进行内联了。先无论这个了,从測试中来看,
这些方法的调用并非开销非常低,是根本就没有开销!
方法调用(还有为了可读性而加的文档)仅仅存在于你的源码和编译后的字节码里,执行时它们全然被清除掉了(内联了)。
我对第二个结果也不太理解。看起来性能高的机器B执行单个方法调用的时候要快点,另两个就要慢些。或许它倾向于延迟进行内联?结果是有些不同,只是差距也不是那么的大。就像 优化栈跟踪信息生成 那样——假设你为了优化代码性能,手动进行内联,把方法越搞越庞大,越弄越复杂,那你就真的错了。
ps:64bit 机器之所以执行慢有可能是由于 JVM 内联的要求的方法长度较长。
文章原文来源于:
http://www.javacodegeeks.com/2013/02/how-aggressive-is-method-inlining-in-jvm.html
http://it.deepinmind.com/java/2014/03/01/JVM的方法内联.html