SeaJS与RequireJS最大的区别
SeaJS与RequireJS最大的区别
执行模块的机制大不一样
-----------------------------------
由于 RequireJS 是执行的 AMD 规范, 因此所有的依赖模块都是先执行.
使用 RequireJS 默认定义模块的方式, 在理解上会更清楚一些, 但个人还是偏爱 require('./mod1') 这样的方式
define(['dep1', 'dep2'], function (dep1, dep2) {
//Define the module value by returning a value.
return function () {};
});
希望文章没有误人子弟, 谢谢 @Jaward华仔 的意见, 请大家多看评论, 评论更有料...
---------------------------------------------------------------------------
SeaJS对模块的态度是懒执行, 而RequireJS对模块的态度是预执行
不明白? 让我们来举个例子
如下模块通过SeaJS/RequireJS来加载, 执行结果会是怎样?
define(function(require, exports, module) {
console.log('require module: main');
var mod1 = require('./mod1');
mod1.hello();
var mod2 = require('./mod2');
mod2.hello();
return {
hello: function() {
console.log('hello main');
}
};
});
猜猜看?
先试试SeaJS的执行结果
require module: main
require module: mod1
hello mod1
require module: mod2
hello mod2
hello main
再来是RequireJS的执行结果
require module: mod1
require module: mod2
require module: main
hello mod1
hello mod2
hello main
RequireJS你坑的我一滚啊, 这也就是为什么我不喜欢RequireJS的原因, 坑隐藏得太深了.
终于明白 玉伯说的那句: " RequireJS 是没有明显的 bug,SeaJS 是明显没有 bug"是什么意思了
因此我们得出结论(分别使用SeaJS 2.0.0和RequireJS 2.1.6进行测试)
-------------------------
SeaJS只会在真正需要使用(依赖)模块时才执行该模块
SeaJS是异步加载模块的没错, 但执行模块的顺序也是严格按照模块在代码中出现(require)的顺序, 这样才更符合逻辑吧! 你说呢, RequireJS?
而RequireJS会先尽早地执行(依赖)模块, 相当于所有的require都被提前了, 而且模块执行的顺序也不一定100%就是先mod1再mod2
因此你看到执行顺序和你预想的完全不一样! 颤抖吧~ RequireJS!
详细的代码请参考
-------------------------
SeaJS测试加载/执行模块
RequireJS测试加载/执行模块
后记
-------
注意我这里说的是执行(真正运行define中的代码)模块, 而非加载(load文件)模块.
模块的加载都是并行的, 没有区别, 区别在于执行模块的时机, 或者说是解析.
为了说明阻塞的问题, 翠花上图
注意图中巨大的pinyin-dict.js模块, 取自 pinyin.js, 复制了N次后以增加它的"重量", 增强演示效果, 大家有兴趣的话可以亲手试试.
可以很明显的看出RequireJS的做法是并行加载所有依赖的模块, 并完成解析后, 再开始执行其他代码, 因此执行结果只会"停顿"1次, 完成整个过程是会比SeaJS要快.
而SeaJS一样是并行加载所有依赖的模块, 但不会立即执行模块, 等到真正需要(require)的时候才开始解析, 这里耗费了时间, 因为这个特例中的模块巨大, 因此造成"停顿"2次的现象, 这就是我所说的SeaJS中的"懒执行".
最后感谢大家的各种意见建议, 我这里并没有说SeaJS与RequireJS哪个更好一些, 仅仅是为了说明下他们的区别, 各种取舍请大家根据实际情况来定, 希望能帮到大家.
-----------------------------------
由于 RequireJS 是执行的 AMD 规范, 因此所有的依赖模块都是先执行.
使用 RequireJS 默认定义模块的方式, 在理解上会更清楚一些, 但个人还是偏爱 require('./mod1') 这样的方式
define(['dep1', 'dep2'], function (dep1, dep2) {
//Define the module value by returning a value.
return function () {};
});
希望文章没有误人子弟, 谢谢 @Jaward华仔 的意见, 请大家多看评论, 评论更有料...
---------------------------------------------------------------------------
SeaJS对模块的态度是懒执行, 而RequireJS对模块的态度是预执行
不明白? 让我们来举个例子
 |
如下模块通过SeaJS/RequireJS来加载, 执行结果会是怎样?
define(function(require, exports, module) {
console.log('require module: main');
var mod1 = require('./mod1');
mod1.hello();
var mod2 = require('./mod2');
mod2.hello();
return {
hello: function() {
console.log('hello main');
}
};
});
猜猜看?
 |
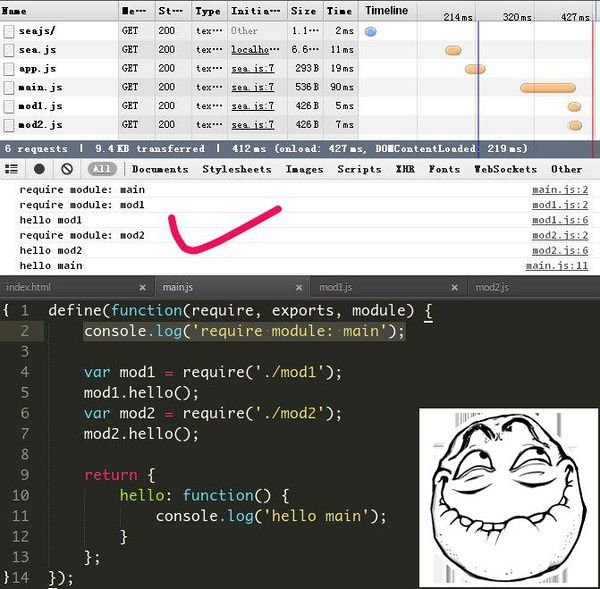
先试试SeaJS的执行结果
require module: main
require module: mod1
hello mod1
require module: mod2
hello mod2
hello main
 |
|
很正常嘛, 我也是这么想的...
|
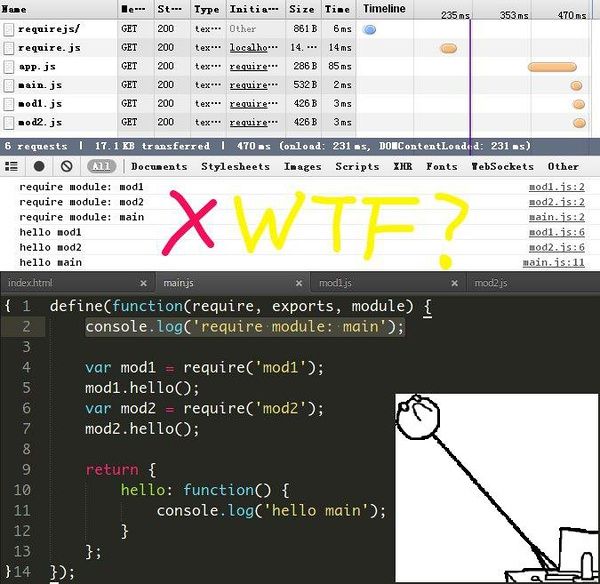
再来是RequireJS的执行结果
require module: mod1
require module: mod2
require module: main
hello mod1
hello mod2
hello main
 |
|
神马情况? 你他么是在逗我吗?
|
RequireJS你坑的我一滚啊, 这也就是为什么我不喜欢RequireJS的原因, 坑隐藏得太深了.
终于明白 玉伯说的那句: " RequireJS 是没有明显的 bug,SeaJS 是明显没有 bug"是什么意思了
因此我们得出结论(分别使用SeaJS 2.0.0和RequireJS 2.1.6进行测试)
-------------------------
SeaJS只会在真正需要使用(依赖)模块时才执行该模块
SeaJS是异步加载模块的没错, 但执行模块的顺序也是严格按照模块在代码中出现(require)的顺序, 这样才更符合逻辑吧! 你说呢, RequireJS?
而RequireJS会先尽早地执行(依赖)模块, 相当于所有的require都被提前了, 而且模块执行的顺序也不一定100%就是先mod1再mod2
因此你看到执行顺序和你预想的完全不一样! 颤抖吧~ RequireJS!
详细的代码请参考
-------------------------
SeaJS测试加载/执行模块
RequireJS测试加载/执行模块
后记
-------
注意我这里说的是执行(真正运行define中的代码)模块, 而非加载(load文件)模块.
模块的加载都是并行的, 没有区别, 区别在于执行模块的时机, 或者说是解析.
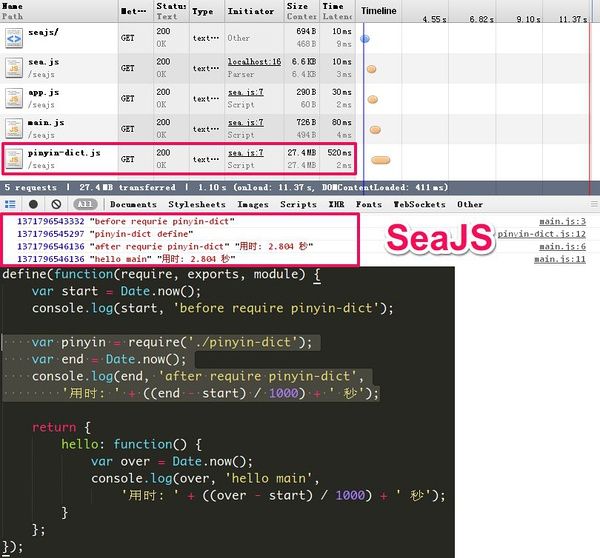
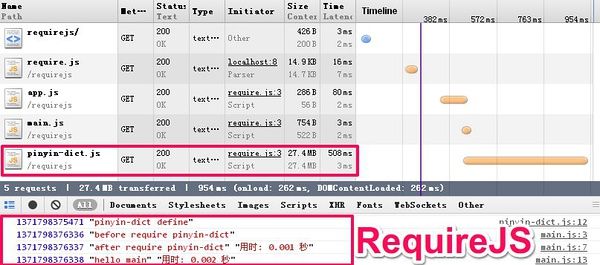
为了说明阻塞的问题, 翠花上图
 |
|
SeaJS的懒执行
|
 |
|
RequireJS的预执行
|
注意图中巨大的pinyin-dict.js模块, 取自 pinyin.js, 复制了N次后以增加它的"重量", 增强演示效果, 大家有兴趣的话可以亲手试试.
可以很明显的看出RequireJS的做法是并行加载所有依赖的模块, 并完成解析后, 再开始执行其他代码, 因此执行结果只会"停顿"1次, 完成整个过程是会比SeaJS要快.
而SeaJS一样是并行加载所有依赖的模块, 但不会立即执行模块, 等到真正需要(require)的时候才开始解析, 这里耗费了时间, 因为这个特例中的模块巨大, 因此造成"停顿"2次的现象, 这就是我所说的SeaJS中的"懒执行".
最后感谢大家的各种意见建议, 我这里并没有说SeaJS与RequireJS哪个更好一些, 仅仅是为了说明下他们的区别, 各种取舍请大家根据实际情况来定, 希望能帮到大家.
牛人观点:
1,
我个人感觉requirejs更科学,所有依赖的模块要先执行好。如果A模块依赖B。当执行A中的某个操doSomething()后,再去依赖执行B模块require('B');如果B模块出错了,doSomething的操作如何回滚?
很多语言中的import, include, useing都是先将导入的类或者模块执行好。如果被导入的模块都有问题,有错误,执行当前模块有何意义?
总之载入的所有模块,都是当前要使用的,为什么要动态的去执行?这个问题可以总结为模块的载入执行是静态还是动态。如果是动态执行的话,那页面的程序执行过程会受到当前模块执行的影响。而正如楼主所言,动态执行总体时间上是比静态一次执行要慢的。
楼主说requirejs是坑,是因为你还不太理解AMD“异步模块”的定义,被依赖的模块必须先于当前模块执行,而没有依赖关系的模块,可以没 有先后。在楼主的例子中,假设mod1和mod2某天发生了依赖的话,比如在某个版本,mod1依赖了mod2(这是完全有可能的),这个时候seajs 的懒执行会不会有问题?而requirejs是不会有问题,也不需要修改当前模块。
在javascript这个天生异步的语言中,却把模块懒执行,这让人很不理解。想像一下factory是个模块工厂吧,而依赖 dependencies是工厂的原材料,在工厂进行生产的时候,是先把原材料一次性都在它自己的工厂里加工好,还是把原材料的工厂搬到当前的 factory来什么时候需要,什么时候加工,哪个整体时间效率更高?显然是requirejs,requirejs是加载即可用的。为了响应用户的某个 操作,当前工厂正在进行生产,当发现需要某种原材料的时候,突然要停止生产,去启动原材料加工,这不是让当前工厂非常焦燥吗?
暂且不去理会这个吧,等ECMA规范中加入了模块化的定义后,再看谁更合理吧。
2,
AMD 运行时核心思想是「Early Executing」,也就是提前执行依赖。这个好理解:
//main.js
define(['a', 'b'], function(A, B) {
//运行至此,a.js 和 b.js 已下载完成(运行于浏览器的 Loader 必须如此);
//A、B 两个模块已经执行完,直接可用(这是 AMD 的特性);
return function () {};
});
个人觉得,AMD 的这个特性有好有坏:
首先,尽早执行依赖可以尽早发现错误。上面的代码中,假如 a 模块中抛异常,那么 main.js 在调用 factory 方法之前一定会收到错误,factory 不会执行;如果按需执行依赖,结果是:1)没有进入使用 a 模块的分支时,不会发生错误;2)出错时,main.js 的 factory 方法很可能执行了一半。
另外,尽早执行依赖通常可以带来更好的用户体验,也容易产生浪费。例如模块 a 依赖了另外一个需要异步加载数据的模块 b,尽早执行 b 可以让等待时间更短,同时如果 b 最后没被用到,带宽和内存开销就浪费了;这种场景下,按需执行依赖可以避免浪费,但是带来更长的等待时间。
我个人更倾向于 AMD 这种做法。举一个不太恰当的例子:Chrome 和 Firefox 为了更好的体验,对于某些类型的文件,点击下载地址后会询问是否保存,这时候实际上已经开始了下载。有时候等了很久才点确认,会开心地发现文件已经下好; 如果点取消,浏览器会取消下载,已下载的部分就浪费了。
https://www.imququ.com/post/amd-simplified-commonjs-wrapping.html
1,
我个人感觉requirejs更科学,所有依赖的模块要先执行好。如果A模块依赖B。当执行A中的某个操doSomething()后,再去依赖执行B模块require('B');如果B模块出错了,doSomething的操作如何回滚?
很多语言中的import, include, useing都是先将导入的类或者模块执行好。如果被导入的模块都有问题,有错误,执行当前模块有何意义?
总之载入的所有模块,都是当前要使用的,为什么要动态的去执行?这个问题可以总结为模块的载入执行是静态还是动态。如果是动态执行的话,那页面的程序执行过程会受到当前模块执行的影响。而正如楼主所言,动态执行总体时间上是比静态一次执行要慢的。
楼主说requirejs是坑,是因为你还不太理解AMD“异步模块”的定义,被依赖的模块必须先于当前模块执行,而没有依赖关系的模块,可以没 有先后。在楼主的例子中,假设mod1和mod2某天发生了依赖的话,比如在某个版本,mod1依赖了mod2(这是完全有可能的),这个时候seajs 的懒执行会不会有问题?而requirejs是不会有问题,也不需要修改当前模块。
在javascript这个天生异步的语言中,却把模块懒执行,这让人很不理解。想像一下factory是个模块工厂吧,而依赖 dependencies是工厂的原材料,在工厂进行生产的时候,是先把原材料一次性都在它自己的工厂里加工好,还是把原材料的工厂搬到当前的 factory来什么时候需要,什么时候加工,哪个整体时间效率更高?显然是requirejs,requirejs是加载即可用的。为了响应用户的某个 操作,当前工厂正在进行生产,当发现需要某种原材料的时候,突然要停止生产,去启动原材料加工,这不是让当前工厂非常焦燥吗?
暂且不去理会这个吧,等ECMA规范中加入了模块化的定义后,再看谁更合理吧。
2,
AMD 运行时核心思想是「Early Executing」,也就是提前执行依赖。这个好理解:
//main.js
define(['a', 'b'], function(A, B) {
//运行至此,a.js 和 b.js 已下载完成(运行于浏览器的 Loader 必须如此);
//A、B 两个模块已经执行完,直接可用(这是 AMD 的特性);
return function () {};
});
个人觉得,AMD 的这个特性有好有坏:
首先,尽早执行依赖可以尽早发现错误。上面的代码中,假如 a 模块中抛异常,那么 main.js 在调用 factory 方法之前一定会收到错误,factory 不会执行;如果按需执行依赖,结果是:1)没有进入使用 a 模块的分支时,不会发生错误;2)出错时,main.js 的 factory 方法很可能执行了一半。
另外,尽早执行依赖通常可以带来更好的用户体验,也容易产生浪费。例如模块 a 依赖了另外一个需要异步加载数据的模块 b,尽早执行 b 可以让等待时间更短,同时如果 b 最后没被用到,带宽和内存开销就浪费了;这种场景下,按需执行依赖可以避免浪费,但是带来更长的等待时间。
我个人更倾向于 AMD 这种做法。举一个不太恰当的例子:Chrome 和 Firefox 为了更好的体验,对于某些类型的文件,点击下载地址后会询问是否保存,这时候实际上已经开始了下载。有时候等了很久才点确认,会开心地发现文件已经下好; 如果点取消,浏览器会取消下载,已下载的部分就浪费了。
https://www.imququ.com/post/amd-simplified-commonjs-wrapping.html