SQLServer2012 和 MariaDB 10.0.3 分页效率的对比
1. 实验环境
R910服务器, 16G内存
SqlServer 2012 64bit
MariaDB 10.0.3 64bit (InnoDB)
2. 实验表情况
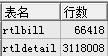
rtlBill.BillNo 为主键, rtlBill.BillDate 上有索引;
rtlDetail.BillNo 上有索引;
3. 实验步骤
(1)重启Sqlserver2012
(2)执行下面的分页语句
SELECT BillDate, SUM([QTY]) PosInQty
FROM RtlDetail A,RtlBill B
WHERE A.billno = B.billno AND BillDate>='2009-09-25 00:00:00' AND BillDate<='2012-09-25 23:59:59'
GROUP BY BillDate
ORDER BY BillDate
OFFSET 10ROW FETCH NEXT20Rows Only;
(3)重启MariaDB
(4)执行下面的分页语句
SELECT BillDate, sum(QTY) AS PosInQty
FROM RtlDetail A,RtlBill B
WHERE A.billno = B.billno AND BillDate>='2009-09-25 00:00:00' AND BillDate<='2012-09-25 23:59:59'
GROUP BY BillDate
Order by BillDate
LIMIT 10,20;
4. 实验结果
同样是获取第 11 ~ 30 条记录
Server2012耗时:18s
MariaDB耗时: 2s
这个差别还是挺震撼的,是什么导致了二者的巨大差距?
下面来看看执行前后二者的IO对比。
5. 分析
(1)从下图中可以看出,为了获取分页数据,MariaDB读取了 52M 数据

(2)为了获取相同的数据,SQLServer2012,读取了 848M 数据

(3)二者的差距,就在分页数据的读取策略上。Sqlerver2012为了读取分页子集,几乎把整个表都放入了内存。不得不说,这块儿优化的空间很大。。。
![]() 为什么SQLServer在获取分页数据源时,不能像MySQL哪样只取所需呢?
为什么SQLServer在获取分页数据源时,不能像MySQL哪样只取所需呢?
有没有办法优化?
请听下回分解《SQLServer2012 分页语句执行分析》
各位看官,欢迎大家拍砖啊,有批评才有进步,谢谢。![]()