使用Intel(R) Visual Fortran Compiler自动向量化优化代码
一、引言
SIMD(Single Instruction Mutiple Data)可以在程序执行中能够复制多个操作数,并把它们直接打包在寄存器中。显而易见,SIMD在性能上有较高的优势,可以以同步方式,在同一时间内执行同一条指令。在指令集上,以AMD的3D Now!和Intel的SSE为突出代表。
而Intel出品的C/C++、Fortran编译器都可以对代码执行循环的自动向量化处理,来提高程序的运行期性能。
二、为什么要使用向量化
1、提高性能,比如向量化一个有浮点操作的并被频繁调用的循环将会极大提高程序的性能。
当函数包含大量循环时通过使用向量化编译器使用SIMD指令能够获取较大的性能上的提高,一段以向量化循环为特征的程序足以快过那些同样运行方式的一般的程序或类库。对比一个向量化的循环和一个同样方式的标量循环,向量化会提供等同于使用底层汇编实现这循环的性能(通常使用在使用Streaming SIMD Extensions时会有25%-40%的性能提高)。向量器也可能在你的循环中打开这些循环并插入一些预取代码,这也可能获得一些额外的性能上的提高。
2、编写单一版本的代码,减少对汇编程序的依赖。
减少使用汇编使编码工作简化,较少的汇编意味着会大大减少你为特定的系统编程的工作,你的程序将很容易升级并使用于最新的主流系统而不必重新编写那些汇编代码。这可以伴随着编译器的升级而升级,如从SSE、SSE2升级到现在的SSE4。
三、向量化的规则和问题
1、纯粹的赋值数组语句可以被向量化
比如
Real,Dimension(10) :: MyArray MyArray=1.2、对于一个循环,如果编译器认为循环内的每一个语句都没有依赖于另一个语句并且没有循环的依赖关系,那么这个循环就是可向量的。换句话说,每一个语句必须能独立执行,读写数据的操作必须中立于循环的每次迭代。
比如下列循环:
do i=0,100 a(i)=b(i)*m+d(i) b(i)=(a(i)+b(i))/2. c=c+b(i) enddo等价于
do i=0,100 a(i)=b(i)*m+d(i) enddo do i=0,100 b(i)=(a(i)+b(i))/2. enddo do i=0,100 c=c+b(i) enddo而像下面的循环
do i=0,100 a(i+1)=a(i)+b enddoa(i+1)在每次迭代中,都使用了前一次迭代a(i)的值。我们称之为数据依赖,这样的循环是不能被编译器向量化的。
3、向量器只能作用在最内层的循环
在一个嵌套的循环中,向量器只能尝试向量化最内层的循环,查看向量器的输出信息可以知道循环是否能被向量化以及原因,如果影响性能的关键循环没有向量化,你可能需要做一些更深层的打算, 添加额外的指令来帮助向量器做出正确的决定。(参考下文)
4、对于那些需要退出条件的循环,如果要向量化的话,必须保证只有一个入口和一个出口。循环退出条件必须是可以确定循环次数的表达式。
例如
do while(i<10) a(i)=t(i)*c(i+1) if (a(i)<0) a(i)=0 endif i=i+1 enddo而
do while(i<10) a(i)=t(i)*c(i+1) if (a(i)<0) exit endif i=i+1 enddo再者
do while(i<10-i) a(i)=t(i)*c(i+1) if (a(i)<0) a(i)=0 endif i=i+1 enddo5、循环中不能有任何的函数调用,但可以使用Fortran的标准内部函数。
四、其他常用的控制指令
1、IVDEP指令
通常情形下,编译器为了安全起见,把一些可能有向量数据依赖也可能没有的代码块全都识别为数据依赖,如果你确信没有数据依赖,那么可以通过IVDEP指令通告编译器执行向量化。
例如
do i = 1, 100 a(i) = a(i+j) enddo
编译器认为j是不定的,可能会j<0,那么就会假定该循环存在数据依赖而不进行向量化,如果你确信j>0,那么你可以加入IVDEP指令通告编译器进行向量化。
!DEC$ IVDEP do i = 1, 100 a(i) = a(i+j) enddo2、NOVECTOR指令
如果你认为编译器不应该对某个可以被向量化的循环进行向量化(进行测试或者你认为在性能上有损失),那么你可以加入NOVECTOR指令。
!DEC$ NOVECTOR do i = 1, 100 a(i) = b(i) + c(i) enddo
五、向量化开关
1、打开向量化,使用以下指令开关
/QaxSSE2
/QaxSSE3
/QaxSSSE3
/QaxSSE4.1
/QaxSSE4.2
/QaxAVX
选择哪个开关,请确定你的CPU支持哪些SSEx的指令集。
2、向量化报告
向量化编译器都可以生成自己的向量化报告,ivf通过/Qvec-report开关开启这一功能。
/Qvec-report[n]
n=0 不显示诊断信息。 n=1 只显示已向量化的循环(默认值)。 n=2 显示已向量化和未向量化的循环。 n=3 显示已向量化和未向量化的循环以及数据依赖信息。 n=4 只显示未向量化的循环。 n=5 显示未向量化的循环以及数据依赖信息。
六、向量化的例子
example.f90内容

用ifort example.f90 /Qvec_report3进行编译
屏幕上会输出
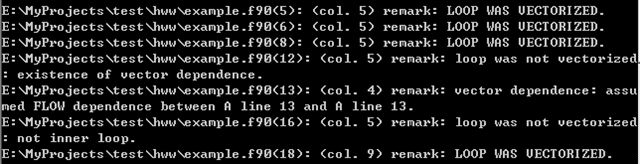
可以看出example.f90的第5、6、8、18行代码段可以被向量化,第12、13行不能向量化是因为数据依赖,第16行因为不是内层循环所以不能被向量化。
七、后记
IVF向量化就写这一些,还有很多复杂的指令请读者参看编译器的文档,以上的代码都是在Windows下IVF 11.1.065运行完成。
向量化虽然能使程序代码以较快的方式运行,但也不要为向量化报告中未向量化的代码打算写成向量化规范而绞尽脑汁,那样的工作量也会相当大。一般情形下,你可利用性能剖析器,比如Intel Vtune,来寻找程序中的热点,只把热点处的代码做适合向量化的改动,这是一个推荐的关键向量化途径。
注:本文参考了Intel官方的编译器文档。