Taste 架构分析
Taste 是一个著名的开源框架,目前已经在Mahout项目下。Taste 实现了比较流行的个性化推荐算法: User-Based、Item-Based、Slope One
实现了 5 个著名的相似度计算算法:
*EuclideanDistance(欧氏距离)
*LogLikelihood(对数似然)
*PearsonCorrelation(皮尔逊相关系数)
*SpearmanCorrelation(和前一个类似,比较的不同而已)
*TanimotoCoefficient(有点类似于关联规则,当然也有很大的不同)
Taste在官方文档中自称: Taste is designed to be enterprise-ready; it's designed for performance, scalability and flexibility.
稍后的分析我们会看到,Taste现在还达不到 enterprise-ready。
Taste的体系结构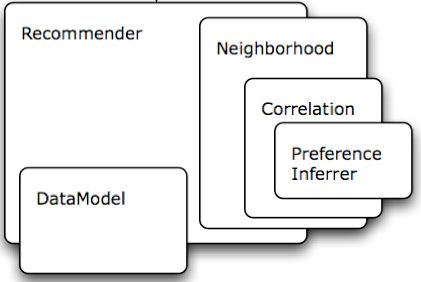
这是Taste'''官网'''上的内容,Taste目前支持两种DataModle:
*FileDataModel
*DatabaseDataModel
存储的格式是一样的:userid"itemid"ratio
Neighborhood是寻找user或者item的最近 N 个邻居,这中间会用到相似度计算的算法。
Recommender 就是输出推荐结果的,它会调用传入的参数:Neighborhood、dataModel,Recommender是可配置的(recommender.properties),我们可以实现自己的推荐类。
Taste的可扩展性
正如官方文档所说,Taste is scalability and flexibility。
下面来看一下Taste的主要类结构:
接口继承结构
顶层接口包括相似度、邻居、模型、推荐等接口。Refreshable是父接口,它只提供了一个方法:
void refresh(Collection<Refreshable> alreadyRefreshed);
其实这是一个观察者模式(Observer Pattern),当数据模型更新的时候,会按照依赖关系更新状态
相似度算法类结构
这里先解释一下,其实说"相似度"是不准确的,个性化推荐计算的不是相似,而是相关,user-user或者item-item的相关性,所以下面就不再说相似,统一用"相关"术语来解释。
Taste定义了一个抽象类 AbstractSimilarity,实现了UserSimilarity, ItemSimilarity 两个接口,Taste实现的五个相关度计算算法都从这个抽象类继承而来。

每一种相关性算法,是否好坏,并没有评价标准,一切都取决于数据,后续文章会介绍每一种算法。
Recommender的类结构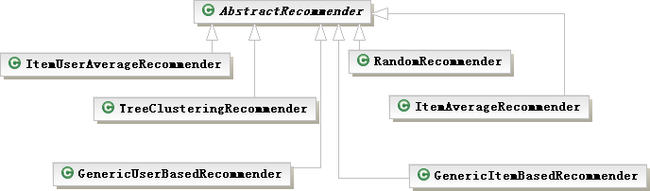
推荐类都是从AbstractRecommender继承而来,他们是在计算相关性之后,按照不同的方式从所有相关的item中选择前 N 个,即 Top-N 的推荐方式。
DataModel对我们意义不大,所以此处省略不写了。
在 Taste 中添加自己的算法
从前面的类结构中可以看出,Taste提供了原生态的接口,提供了抽象类的实现。所有,如果我们想添加自己的相似度计算算法、推荐类、数据模型表示、Infer算法,可以根据需要,实现原生的接口或者从抽象类直接继承即可。
Taste的Scalability, 说直白点,就是面向接口的编程。比Dunie Framework稍好一些,后者的Pluggable模块,完全借助于Spring实现的。
Taste的性能
先说结论吧,'''Taste不支持企业级的数据应用'''。
Taste提供了Slope One,Item-Based Or User-Based 三种推荐的"Hadoop实现",这里加了引号,意味着不支持Hadoop,下面看具体分析:
1. 对 DataModel 的处理
在 Mapper里:
FileSystem fs = FileSystem.get(dataModelPath.toUri(), jobConf);
File tempDataFile = File.createTempFile("mahout-taste-hadoop", "txt");
tempDataFile.deleteOnExit();
fs.copyToLocalFile(dataModelPath, new Path(tempDataFile.getAbsolutePath()));
fileDataModel = new FileDataModel(tempDataFile);
很显然先把数据 Copy 到本地,然后生成 FileDataModel对象,'''如果数据比较大,几个G的文件,即使下载到本地,恐怕内存也放不下。。。'''
2. Recommend 的过程
@Override
protected void map(LongWritable key, LongWritable value,
Context context) throws IOException, InterruptedException {
long userID = value.get();
List<RecommendedItem> recommendedItems;
try {
'''recommendedItems = recommender.recommend(userID, recommendationsPerUser);'''
} catch (TasteException te) {
throw new IllegalStateException(te);
}
注意黑体部分,Hadoop的map/reduce 在这里没发挥任何作用。如果说唯一发挥作用的地方,那就是如果想一次得到 N 个 User 的推荐结果,Hadoop会产生 N 个 Mapper,但是,
切记:每个 User 推荐结果的计算过程完全是在一个节点上完成的。
3. Slope One推荐算法实现的顶级软骨
关于 Slope One后续会专门开文介绍。
来看看Slope One在得到用户的打分矩阵之后,Reduce生成 Item 的 Diff 的矩阵的实现:
@Override
protected void reduce(Text key, Iterable<ItemPrefWritable> values, Context context)
throws IOException, InterruptedException {
'''List<ItemPrefWritable> prefs = new ArrayList<ItemPrefWritable>(); (1)'''
for (ItemPrefWritable value : values) {
prefs.add(new ItemPrefWritable(value));
}
'''Collections.sort(prefs, ByItemIDComparator.getInstance());(2)'''
int size = prefs.size();
'''for (int i = 0; i < size; i++) {'''
''' for (int j = i + 1; j < size; j++) {(3)'''
context.write(........);
}
}
}
黑体部分是需要特别注意的地方:
(1):先把 reduce 的 values保存到 List里。如果商品数量很大,List能存下吗?而且在接近JVM堆内存极限的过程中,List不断的扩充,导致的内存Copy,也够低效的:(
(2):Sort,虽然JDK的排序做了优化,可是对上百万的数据排序,还是很耗 CPU 的
(3):for 循环,计算 Item 的 diff 矩阵,是需要笛卡尔乘积计算的。这么大的计算量,双重 for loop,是无论如何也对付不了大数据的。
综上, Taste无法支持企业级规模数据的应用!