大语言模型LLM基础扫盲速通版
文章目录
- 1. 什么是LLM?
- 2. LLM如何工作?
- 3. LLM开发的关键里程碑
- 4. 训练可用LLM模型的完整流程
- 5. LLM具备的能力
- 6. 领先的LLM模型包含哪些?
- 7. 建议从头开始训练LLM吗?
- 8. LLM的训练数据源包含哪些?
- 9. 其他关于LLM的常见问题
-
- 9.1 Transformer在LLM中有何意义?
- 9.2 在LLM中,微调 (fine-tuning) 是什么?
- 9.3 模型大小如何影响LLM的性能?
- 9.4 LLM 能生成编程语言的代码吗?
- 9.5 LLM的“上下文学习”是什么?
- 9.6 LLM中的“零样本”和“小样本”学习是什么?
1. 什么是LLM?
LLM 是“大型语言模型”(Large Language Model)的缩写。它指的是使用深度学习技术训练出来的,具有大规模参数量的语言处理模型。这些模型通常在互联网上的大量文本数据上进行训练,以学习自然语言的模式和结构。训练后的 LLM 能够执行各种自然语言处理任务,如文本生成、机器翻译、问答系统、摘要生成、情感分析等。
当我们说人类语言时,不仅仅指中文、英语或法语等,人类语言还延伸到:
- 摩尔斯电码
- 遗传密码
- 象形文字
- 加密
- 手语
- 肢体语言
- 乐谱
- 化学信号
- 表情符号和符号
- 动物交流
- 触觉通信
- 交通标志和信号
- 数学方程
- 编程语言
LLM 经过数百、数千亿、甚至数万亿个参数的训练,能够从广泛的数据源中学习到规律。
这种广泛的训练使他们能够根据收到的输入预测和生成文本,以便他们可以参与对话、回答查询甚至编写代码。
2. LLM如何工作?
大型语言模型使用神经网络和机器学习 (ML) 的混合。正是这种混合使得该技术能够首先处理然后生成原始文本和图像。神经网络是 LLM 的大脑。这些网络从大量数据中学习,随着接触更多数据而不断进步。
随着模型接受更多数据的训练,它会学习语言的模式、结构和细微差别。这就像同时教它语法规则、诗歌节奏和技术手册的术语一样。
然后,机器学习模型帮助模型根据句子前面的单词预测下一个单词。这个过程重复了无数次,提高了模型生成连贯且上下文相关的文本的能力。
LLM 现在采用 Transformer 架构,该架构允许模型查看并权衡句子中不同单词的重要性,这与我们阅读句子并寻找上下文线索来理解其含义时的情况相同。
虽然 LLM 可以生成原创内容,但其输出的质量、相关性和创新性可能会有所不同,需要人工监督和改进。
3. LLM开发的关键里程碑
大型语言模型并不总是像今天这样有用。随着时间的推移,它们得到了很大的发展和迭代。
让我们回顾一下 LLM 历史上的一些关键时刻。这样你就可以了解他们取得了多大的进步,以及与几十年的缓慢进步相比,过去几年的快速发展。

(1)2010 年之前:早期基础
1950 年代至 1970 年代:早期的人工智能研究为自然语言处理奠定了基础。最著名的是,名为“Eliza”的技术人员是世界上第一个聊天机器人。
1980 年代至 1990 年代:NLP 统计方法的发展,逐渐摆脱基于规则的系统。
(2)2010 年:初始模型
2013 年推出了 word2vec,这是一种计算词语向量表示的工具,通过捕捉词语的语义,显著提高了 NLP 任务的质量。
(3)2014-2017:RNN 和注意力机制
2014 年:序列到序列 (seq2seq) 模型和循环神经网络 (RNN) 在机器翻译等任务中变得流行。
2015年:引入注意力机制,提高神经机器翻译系统的性能。
2017年:《Attention is All You Need》论文中提出了Transformer模型,以对序列的高效处理为NLP任务树立了新的标准。
(4)2018 年:GPT 和 BERT 的出现
2018 年 6 月:OpenAI 推出 GPT(生成式预训练变压器),这是一种利用无监督学习生成连贯且多样化文本的模型。
2018 年 10 月:Google AI 推出 BERT(来自 Transformers 的双向编码器表示),它使用 Transformer 模型的双向训练来提高对语言上下文的理解。
(5)2019-2020:更大、更强大的类型
2019 年:推出 GPT-2,这是 GPT 的改进版本,具有 15 亿个参数,展示了该模型在扩展段落中生成连贯且上下文相关的文本的能力。
2020 年:OpenAI 发布 GPT-3,这是一个拥有 1750 亿个参数的更大模型,在生成类似人类的文本、翻译和回答问题方面表现出卓越的能力。
(6)2021-2023:LLM的专业化、多模态性和民主化
2021-2022:开发专门的模型,例如用于对话应用程序的 Google LaMDA 和用于开放预训练变压器的 Facebook OPT。
2021 年:引入多模态模型,例如 OpenAI 的 DALL·E,能够根据文本描述生成图像,以及 CLIP,可以在自然语言环境中理解图像。
2022 年:GPT-4 和其他先进模型(如 Midjourney)的出现,继续突破 LLM 在各个领域和任务(包括图像生成)中生成和理解自然语言方面的潜力。它也更容易被更多人接受。
下图是2023年之前的大模型发布的时间线:
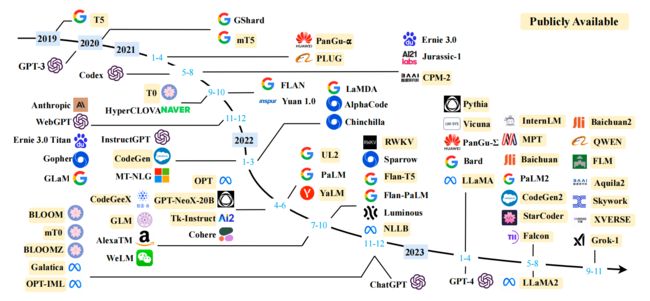
4. 训练可用LLM模型的完整流程
(1)模型定义与准备
- 选择或设计模型架构:根据任务需求选择适合的神经网络结构,例如Transformer架构。
- 初始化模型参数:设定初始权重和偏置值,这些通常是随机初始化或者从预训练模型加载。
(2) 数据收集与预处理
- 数据源采集:获取来自多种渠道的数据,如网页、书籍、新闻文章等。确保数据的质量和多样性。
- 数据清洗:去除噪声、重复内容和其他不需要的信息,以提高数据质量。
- 分词器训练:如果需要自定义分词规则,则需训练一个合适的分词器(Tokenizer),将文本转换成模型可以理解的形式。
- 数据格式化:将文本转化为适合输入给模型的形式,比如将句子分割成tokens,并添加特殊标记如[CLS]和[SEP]。
(3) 预训练(Pre-training)
- Next Token Prediction:通过预测下一个token的任务来学习语言模式。这是无监督学习的一部分,旨在让模型掌握广泛的语言规律。
- 掩码语言建模(Masked Language Modeling, MLM):随机遮蔽一部分词汇,然后让模型去预测被遮蔽的词汇。这有助于模型更好地理解和表示上下文信息。
- 使用大规模语料库:利用大量未标注的数据进行预训练,使模型能够获得丰富的语言知识。
(4)监督微调(Supervised Fine-Tuning, SFT)
- 引入带标签的数据集:针对特定下游任务,使用带有明确标签的数据集对模型进行微调。
- 指令跟随能力:通过提供具体的指令,使模型学会按照指示生成响应或执行任务。
- 减少错误输出:修正预训练期间可能学到的一些不正确的行为或输出。
(5) 可选,强化学习与人类反馈(Reinforcement Learning from Human Feedback, RLHF)
- 偏好对齐:通过人类评估者的反馈,调整模型的输出使其更符合人类的价值观和期望。
- 控制有害内容:防止模型生成任何可能引起伤害的内容,如仇恨言论、虚假信息等。
- 优化对话风格:改善模型的回答方式,使得其语气更加自然友好,更适合人机交互。
(6)模型评估与验证
- 内部测试:在开发过程中持续监控模型性能,确保其稳定性和准确性。
- 外部基准测试:使用公共可用的基准数据集来衡量模型相对于其他同类模型的表现。
- 用户反馈:收集真实用户的评价,了解实际应用场景下的用户体验。
(7) 部署与推理
- 模型压缩:为了降低计算成本和加速推理速度,可能会采用量化、剪枝等技术简化模型。
- 服务化部署:将训练好的模型部署到生产环境中,供API或其他应用程序调用。
- 在线更新机制:建立定期更新机制,以便随着新数据的到来不断改进模型。
5. LLM具备的能力
以下是 LLM 能力的列表:
- 文本生成
- 语言翻译
- 总结
- 问答
- 情绪分析
- 对话代理
- 代码生成与解释
- 命名实体识别
- 文本分类
- 内容推荐
- 语言建模
- 拼写检查和语法校正
- 释义和重写
- 关键字和短语提取
- 对话系统
6. 领先的LLM模型包含哪些?
- GPT系列:由 OpenAI 推出
- LLaMA:由 Meta 推出
- PaLM 2:由 Google DeepMind 推出
- Gemini:由 Google DeepMind 推出
- Claude:由 Anthropic 推出
- Qwen:由阿里巴巴推出
- …
7. 建议从头开始训练LLM吗?
从头开始训练 LLM 一般公司难以承担成本,需要大量的资源、时间和技术支持。
训练一个大型模型需要大量的计算资源。为了训练一个与 GPT-3、GPT-4 等规模相当的模型,通常需要数百到上千个 GPU 卡,可能花费数百到数千万美元。
训练时间因硬件资源和模型规模而异。使用高性能的硬件(如TPU集群),训练一个大规模的模型可能需要几周到几个月的时间。
所以目前很多公司的策略是采用开源模型,如 LLaMA、Qwen 等,把这些已经训练好的模型权重作为基础模型,在此基础上增加新的语料进行微调或增量训练,以此大大降低时间和机器成本。
8. LLM的训练数据源包含哪些?
- 网页内容
- 书籍和文献
- 社交媒体平台
- 新闻文章和期刊
- 百科全书和其他参考
- 开源项目和代码库
下面是一些开源的数据集:
| 数据集名称 | 使用者 | 类型 | 语言 | 大小 | 描述 ️ |
|---|---|---|---|---|---|
| proof-pile | proof-GPT | 预训练 (PT) | 英文 LaTeX |
13GB | 一个预训练数据集,类似于Pile但包含LaTeX语料库以增强模型在证明上的能力。 |
| peS2o | / | 预训练 (PT) | 英文 | 7.5GB | 用于预训练的高质量学术论文数据集。 |
| StackOverflow 帖子 |
/ | 预训练 (PT) | / | 35GB | 以Markdown格式的原始StackOverflow数据,用于预训练。 |
| SlimPajama | / | 预训练 (PT) | 主要为英文 | / | RedPajama的清理和去重版本 |
| NMBVC | / | 预训练 (PT) | 中文 | / | 大规模、持续更新的中文预训练数据集。 |
| falcon-refinedweb | tiiuae/falcon系列 | 预训练 (PT) | 英文 | / | CommonCrawl的精炼子集。 |
| CBook-150K | / | 预训练 (PT), 构建数据集 | 中文 | 150K+书籍 | 原始中文书籍数据集。需要一些预处理流程。 |
| Common Crawl | LLaMA(经过一些处理后) | 构建数据集, 预训练 (PT) |
/ | / | 最著名的原始数据集之一,很少直接使用。一种可能的预处理流程是CCNet |
| nlp_Chinese_Corpus | / | 预训练 (PT), TF |
中文 | / | 包括维基百科、百度百科、百度问答、一些论坛问答和新闻语料库的中文预训练语料库。 |
| The Pile (V1) | GLM(部分)、LLaMA(部分)、GPT-J, GPT-NeoX-20B, Cerebras-GPT 6.7B, OPT-175b | 预训练 (PT) | 多语言, 代码 |
825GB | 包含22个更小的高质量数据集的多样化开源语言模型数据集,涵盖许多领域和任务。 |
| C4 Huggingface数据集 TensorFlow数据集 |
Google T5系列, LLaMA | 预训练 (PT) | 英文 | 305GB | Common Crawl网页爬虫语料库的巨量清理版本。经常被使用。 |
| ROOTS | BLOOM | 预训练 (PT) | 多语言, 代码 |
1.6TB | 包括Wikipedia和StackExchange等子数据集的多样化开源数据集,用于语言模型。 |
| PushshPairs reddit 论文 |
OPT-175b | 预训练 (PT) | / | / | Reddit原始数据,一种可能的处理流程见此论文 |
| Gutenberg项目 | LLaMA | 预训练 (PT) | 多语言 | / | 书籍数据集,主要是小说。未经过预处理。 |
| CLUECorpus | / | 预训练 (PT), 微调, 评估 |
中文 | 100GB | 来源于Common Crawl的中文预训练语料库。 |
9. 其他关于LLM的常见问题
9.1 Transformer在LLM中有何意义?
Transformer 模型至关重要,因为它们使 LLM 能够通过自注意力机制处理文本中的长距离依赖关系。该机制允许模型衡量句子中不同单词的重要性,从而提高语言模型在理解和生成语言方面的表现。
9.2 在LLM中,微调 (fine-tuning) 是什么?
微调是在预训练之后的环节,针对特定任务进一步训练它。此过程会调整模型权重,使其在特定任务(如情绪分析、处理编程语言或其他专门应用程序)上表现更好。
9.3 模型大小如何影响LLM的性能?
模型大小通常以参数数量来衡量,它会影响 LLM 捕捉复杂语言模式的能力。根据多篇论文的实验表明,具有数千亿个参数的超大型模型通常表现更好,但在训练过程中需要更多的计算资源。
9.4 LLM 能生成编程语言的代码吗?
是的,LLM 可以生成各种编程语言的代码。它们通过提供代码片段、调试帮助和翻译代码来帮助开发人员,这要归功于它们在包含编程代码的各种数据集上进行的训练。
9.5 LLM的“上下文学习”是什么?
上下文学习是指 LLM 能够仅根据推理过程中提供的输入文本来学习和执行特定任务,而无需进行额外的微调。这使模型能够动态适应新任务或指令,从而增强其在广泛应用中的多功能性。
9.6 LLM中的“零样本”和“小样本”学习是什么?
零样本(zero shot)学习允许 LLM 利用其一般的语言理解能力来执行未经过明确训练的特定任务。
少样本(few shot)学习涉及在提示中为模型提供一些任务示例来指导其推理。
这两种方法都展示了模型在极少或没有额外训练数据的情况下进行泛化和适应新任务的能力。
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
欢迎关注知乎/CSDN:SmallerFL
也欢迎关注我的wx公众号(精选高质量文章):一个比特定乾坤
