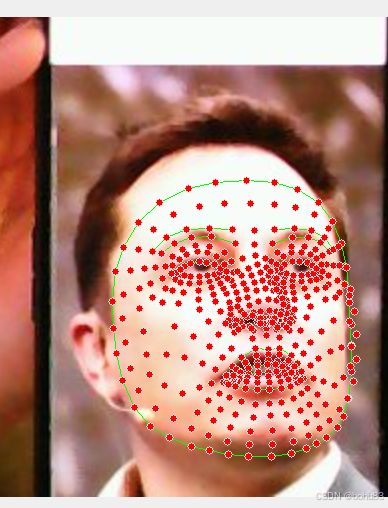
亚博microros小车-原生ubuntu支持系列:7-脸部检测
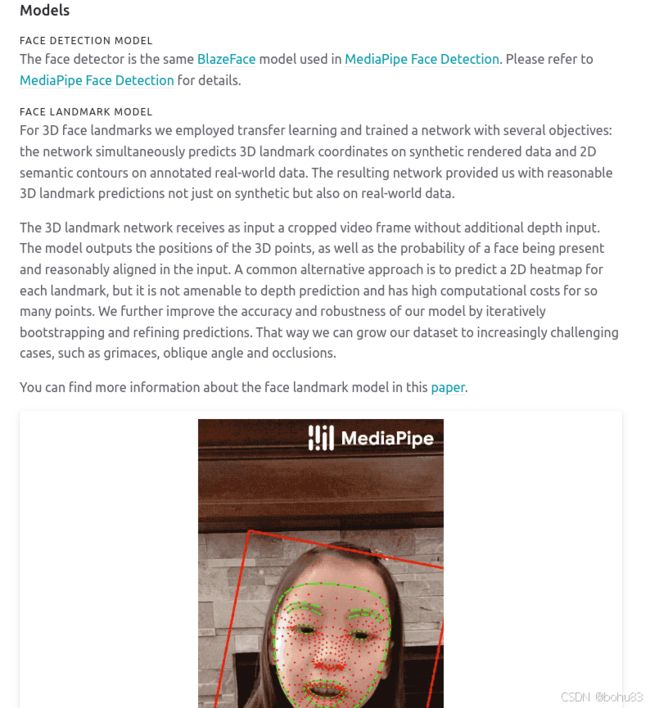
背景知识
官网介绍:
Face Mesh - mediapipe
mpFaceMesh.FaceMesh() 类的参数有:self.staticMode, self.maxFaces, self.minDetectionCon, self.minTrackCon
staticMode:是否将每帧图像作为静态图像处理。如果为 True,每帧都会进行人脸检测;如果为 False,在检测到人脸后进行跟踪,速度更快
maxFaces:要检测的最大人脸数量
minDetectionCon:检测的最小置信度阈值。低于此值的人脸将被忽略
minTrackCon:跟踪的最小置信度阈值。低于此值的跟踪将被忽略
import cv2
import mediapipe as mp
mp_drawing = mp.solutions.drawing_utils#绘图工具
mp_facemesh = mp.solutions.face_mesh
#手部模型
faceMesh = mp_facemesh.FaceMesh(
static_image_mode=False,
max_num_faces=2,
min_detection_confidence=0.75,
min_tracking_confidence=0.75)
cap = cv2.VideoCapture(0)#打开默认摄像头
while True:
ret,frame = cap.read()#读取一帧图像
#图像格式转换
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# 因为摄像头是镜像的,所以将摄像头水平翻转
# 不是镜像的可以不翻转
frame= cv2.flip(frame,1)
#输出结果
results = faceMesh.process(frame)
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
if results.multi_face_landmarks:
for face_landmarks in results.multi_face_landmarks:
# 关键点可视化
mp_drawing.draw_landmarks(
frame, face_landmarks, mp_facemesh.FACEMESH_CONTOURS)
cv2.imshow('MediaPipe face', frame)
if cv2.waitKey(1) & 0xFF == 27:
break
cap.release()这几个基本格式类似的,就是换个模型,输出结果不同
效果:
脸部检测
src/yahboom_esp32_mediapipe/yahboom_esp32_mediapipe/目录下新建文件04_FaceMesh.py
代码如下
#!/usr/bin/env python3
# encoding: utf-8
#import ros lib
import rclpy
from rclpy.node import Node
from geometry_msgs.msg import Point
import mediapipe as mp
#import define msg
from yahboomcar_msgs.msg import PointArray
#import commom lib
import cv2 as cv
import numpy as np
import time
from cv_bridge import CvBridge
from sensor_msgs.msg import Image, CompressedImage
from rclpy.time import Time
import datetime
print("import done")
class FaceMesh(Node):
def __init__(self, name,staticMode=False, maxFaces=2, minDetectionCon=0.5, minTrackingCon=0.5):
super().__init__(name)
self.mpDraw = mp.solutions.drawing_utils#画图
self.mpFaceMesh = mp.solutions.face_mesh
#模型初始化
self.faceMesh = self.mpFaceMesh.FaceMesh(
static_image_mode=staticMode,
max_num_faces=maxFaces,
min_detection_confidence=minDetectionCon,
min_tracking_confidence=minTrackingCon )
self.pub_point = self.create_publisher(PointArray,'/mediapipe/points',1000)
self.lmDrawSpec = mp.solutions.drawing_utils.DrawingSpec(color=(0, 0, 255), thickness=-1, circle_radius=3)
self.drawSpec = self.mpDraw.DrawingSpec(color=(0, 255, 0), thickness=1, circle_radius=1)
def pubFaceMeshPoint(self, frame, draw=True):
pointArray = PointArray()
img = np.zeros(frame.shape, np.uint8)
imgRGB = cv.cvtColor(frame, cv.COLOR_BGR2RGB)
self.results = self.faceMesh.process(imgRGB)#检测
if self.results.multi_face_landmarks:
for i in range(len(self.results.multi_face_landmarks)):#输出关键点
if draw: self.mpDraw.draw_landmarks(frame, self.results.multi_face_landmarks[i], self.mpFaceMesh.FACEMESH_CONTOURS, self.lmDrawSpec, self.drawSpec)
self.mpDraw.draw_landmarks(img, self.results.multi_face_landmarks[i], self.mpFaceMesh.FACEMESH_CONTOURS, self.lmDrawSpec, self.drawSpec)
for id, lm in enumerate(self.results.multi_face_landmarks[i].landmark):
point = Point()
point.x, point.y, point.z = lm.x, lm.y, lm.z
pointArray.points.append(point)
self.pub_point.publish(pointArray)
return frame, img
def frame_combine(slef,frame, src):
if len(frame.shape) == 3:
frameH, frameW = frame.shape[:2]
srcH, srcW = src.shape[:2]
dst = np.zeros((max(frameH, srcH), frameW + srcW, 3), np.uint8)
dst[:, :frameW] = frame[:, :]
dst[:, frameW:] = src[:, :]
else:
src = cv.cvtColor(src, cv.COLOR_BGR2GRAY)
frameH, frameW = frame.shape[:2]
imgH, imgW = src.shape[:2]
dst = np.zeros((frameH, frameW + imgW), np.uint8)
dst[:, :frameW] = frame[:, :]
dst[:, frameW:] = src[:, :]
return dst
class MY_Picture(Node):
def __init__(self, name):
super().__init__(name)
self.bridge = CvBridge()
self.sub_img = self.create_subscription(
CompressedImage, '/espRos/esp32camera', self.handleTopic, 1) #获取esp32传来的图像
self.last_stamp = None
self.new_seconds = 0
self.fps_seconds = 1
self.face_mesh = FaceMesh('face_mesh')
def handleTopic(self, msg):
self.last_stamp = msg.header.stamp
if self.last_stamp:
total_secs = Time(nanoseconds=self.last_stamp.nanosec, seconds=self.last_stamp.sec).nanoseconds
delta = datetime.timedelta(seconds=total_secs * 1e-9)
seconds = delta.total_seconds()*100
if self.new_seconds != 0:
self.fps_seconds = seconds - self.new_seconds
self.new_seconds = seconds#保留这次的值
start = time.time()
frame = self.bridge.compressed_imgmsg_to_cv2(msg)
frame = cv.resize(frame, (640, 480))
cv.waitKey(10)
frame, img = self.face_mesh.pubFaceMeshPoint(frame,draw=False)
end = time.time()
fps = 1 / ((end - start)+self.fps_seconds)
text = "FPS : " + str(int(fps))
cv.putText(frame, text, (20, 30), cv.FONT_HERSHEY_SIMPLEX, 0.9, (0, 0, 255), 1)
dist = self.face_mesh.frame_combine(frame, img)
cv.imshow('dist', dist)
# print(frame)
cv.waitKey(10)
def main():
print("start it")
rclpy.init()
esp_img = MY_Picture("My_Picture")
try:
rclpy.spin(esp_img)
except KeyboardInterrupt:
pass
finally:
esp_img.destroy_node()
rclpy.shutdown()
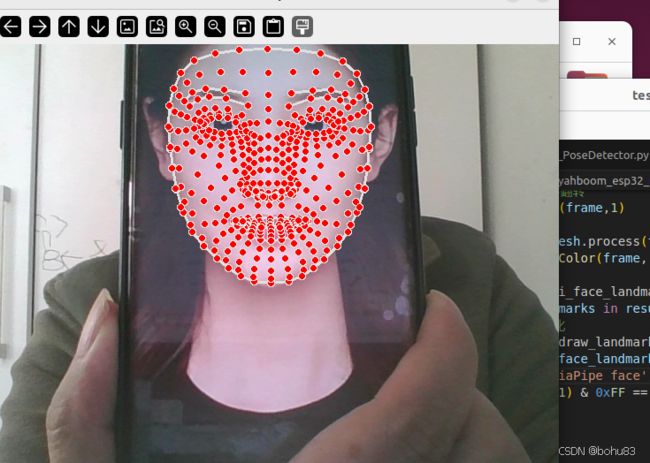
订阅esp32传出来的图像后,通过MediaPipe去做相关的识别后显示。主体流程跟之前一样,换了检测模型。
构建后运行:ros2 run yahboom_esp32_mediapipe FaceMesh
效果如下