【ChatBI】text2sql-不需要访问数据表-超轻量Python库Vanna快速上手,对接oneapi
oneapi 准备
首先确保你有oneapi ,然后申请 kimi的api
需要去Moonshot AI - 开放平台
然后添加一个api key
然后打开oneapi的渠道界面,添加kimi。
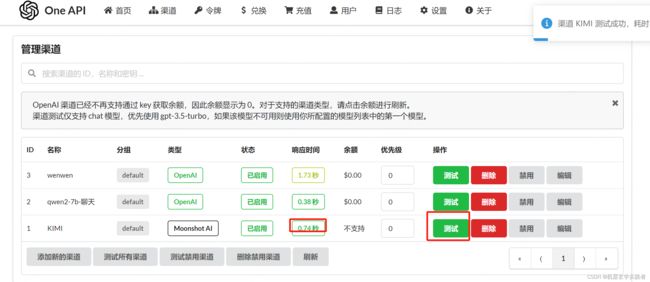
然后点击 测试, 如果能生成响应时间,就是配置正确。
然后创建令牌 http://xxx:3000/token , 模型名是moonshot-v1-8k
然后复制token , token是sk开头的一串密码。
其他平台接入也是类似操作, 不懂的读者可以留言评论。
Vanna安装使用
说明
Vanna是一个轻量的Python库, 用来做nl2sql 。 它可以根据用户的问题, 生成对应的sql 查询语句。一般来说。vanna需要建表sql和一些常见的查询sql。 然后vanna 会通过搜索你的sql 来模仿生成一个sql 。 (用prompt的形式)。
安装库
pip install vanna就可以了
然后执行以下代码。
from openai import OpenAI
from vanna.openai.openai_chat import OpenAI_Chat
from vanna.chromadb.chromadb_vector import ChromaDB_VectorStore
# zhipu
from zhipuai import ZhipuAI
# oneapi kimi
#url,API_KEY,model_name = "http://10.106.153.12:3002/v1",'sk-NykXx0lml5gnMy6gEe8bA114BbB644C398Ac0d8b5a123d48','moonshot-v1-8k'
url,API_KEY,model_name = "http://10.106.153.11:9002/v1",'EMPTY', 'qwen2-7b-instruct'
client = OpenAI(
api_key=API_KEY,
base_url=url,
)
def single_query(query):
return [{"role": "user", "content": query}]
def qwen_chat(client,model,history):
# create a chat completion temperature=0.9,
completion = client.chat.completions.create(
model=model, max_tokens=512,
messages=history
)
return completion.choices[0].message.content
# print the completion
# 用这一行测试是否能正常访问 oneapi的接口
# print(qwen_chat(client,model_name,single_query('你好')))
class MyVanna(ChromaDB_VectorStore, OpenAI_Chat):
def __init__(self, client=None, config=None):
ChromaDB_VectorStore.__init__(self, config=config)
OpenAI_Chat.__init__(self, client=client, config=config)
vn = MyVanna(client=client, config={"model": model_name})
#vn.max_tokens = 1000
vn.temperature = 1
vn.train(ddl="""
CREATE TABLE IF NOT EXISTS users (
id INT PRIMARY KEY COMMENT '用户ID',
username VARCHAR(50) COMMENT '用户名',
email VARCHAR(100) COMMENT '电子邮件',
age INT COMMENT '年龄',
gender VARCHAR(10) COMMENT '性别(男/女)',
city VARCHAR(50) COMMENT '城市'
) COMMENT='用户信息表' CHARACTER SET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
""")
vn.train(ddl="CREATE TABLE IF NOT EXISTS consumption_record ( id INT PRIMARY KEY COMMENT '消费记录ID',"
"user_id COMMENT '用户id' ,item_id INT COMMENT '商品id',amount INT COMMENT '数量' ,consumption INT COMMENT '总消费'"
") COMMENT='购买记录' CHARACTER SET=utf8mb4 COLLATE=utf8mb4_unicode_ci; ")
query = '男性用户的总消费是多少'
res = vn.generate_sql(query)
print("#"*10)
print(query,res)
print("#"*10)
query = '男性用户有多少个'
res = vn.generate_sql('男性用户有多少个')
print("#"*10)
print(query,res)
print("#"*10)
vanna的优势是可以直接生成sql,不需要访问你的数据表。 只需要sql 建表信息, 或者是一些已有的sql ,它可以从已有的sql中进行学习。