【升级!解锁 27 种文件格式,处理效率狂飙】
升级!解锁 27 种文件格式,处理效率狂飙
-
- 前言
- 新增与优化功能详解
- 代码深度解析
- GUI 界面构建与交互逻辑
- 多线程处理与消息队列机制
- 文件处理核心逻辑
- 如图所示
- 注意事项
前言
这一版本的升级力度堪称全面且深入,在文件格式支持上,从原先有限的几种格式拓展到了涵盖图片、文档、视频在内的 27 种常见格式,无论是日常办公文档,还是珍藏的高清视频,都能精准识别处理。大文件处理方面,通过增大读取缓冲区和添加哈希计算进度日志,大幅提升处理速度与透明度,让等待不再煎熬。界面也焕然一新,不仅清晰展示支持的文件类型,进度显示也更加直观,用户体验直线上升。同时还新增了自动跳过损坏文件的智能功能,处理大量文件时建议搭配 SSD 硬盘,日志记录也更加详尽,全方位提升文件管理效率。
新增与优化功能详解
(一)支持丰富的文件格式
新版本支持多达 27 种文件格式,涵盖图片、文档和视频三大类:
图片格式(7 种):.jpg、.jpeg、.png、.gif、.bmp、.webp、.tiff。无论是日常拍摄的照片,还是精心制作的图片素材,都能被准确识别和处理。
文档格式(8 种):.pdf、.doc、.docx、.xls、.xlsx、.ppt、.pptx、.txt。从工作中的各类文档,到学习资料,都在清理器的处理范围内。
视频格式(12 种):.mp4、.avi、.mov、.mkv、.flv、.wmv、.mpeg、.mpg、.m4v、.3gp、.webm、.vob。不管是热门的 MP4 视频,还是其他格式的视频文件,都能轻松应对,甚至支持 4K/8K 超高清视频文件的处理 ,满足用户对高质量视频文件管理的需求。
(二)大文件处理优化
为了提升大文件的处理效率,我们做了两项关键优化:
增大读取缓冲区:在计算文件哈希值时,将文件读取缓冲区大小从原来的 4096 字节增加到 65536 字节(64KB)。这使得程序在读取大文件时,减少了读取次数,大大提高了哈希计算速度,尤其是在处理 4K/8K 视频这类大文件时效果显著。
添加哈希计算进度日志:在计算文件哈希值过程中,每处理 10MB 数据,就会在日志中记录进度。例如,当处理一个大视频文件时,日志会显示正在计算哈希:[文件名] - 已处理 [X]MB,让用户随时了解哈希计算的进展情况,增强了程序的可监控性。
三)界面改进
显示支持的文件类型:在实时信息面板中新增了文件类型提示标签,显示 “支持的文件类型:图片、文档、视频等 27 种格式”,让用户一目了然,清楚知道程序能够处理的文件范围。
优化进度显示:不仅在进度条上实时展示文件处理进度,还在状态标签中以更直观的方式显示处理进度,如 “处理进度:[当前处理文件数]/[总文件数] ([当前进度百分比])” ,让用户对处理进程的了解更加精准
(四)智能文件处理
自动跳过损坏的文件:在处理文件过程中,如果遇到损坏无法读取的文件,程序会自动跳过,并在日志中记录错误信息,避免因个别损坏文件导致整个处理流程中断,大大提高了程序的稳定性和容错性。
处理大量文件时建议使用 SSD 硬盘:由于处理大量文件时 I/O 操作频繁,使用传统机械硬盘可能会导致处理速度较慢。因此,建议在处理大量文件时使用 SSD 硬盘,利用其高速读写特性,大幅提升文件处理效率。
(五)全面的日志记录
日志文件file_cleaner.log会详细记录所有操作细节,包括文件处理的开始和结束时间、每个文件的处理结果、发现的重复文件信息、哈希计算进度以及遇到的任何错误等。这为用户在后续检查和分析文件处理过程提供了详尽的数据支持,方便用户排查问题和了解程序运行情况。
代码深度解析
# ==================== 全局配置 ====================
# 支持的文件扩展名(图片、文档、视频)
VALID_EXTENSIONS = [
# 图片格式
'.jpg', '.jpeg', '.png', '.gif', '.bmp', '.webp', '.tiff',
# 文档格式
'.pdf', '.doc', '.docx', '.xls', '.xlsx', '.ppt', '.pptx', '.txt',
# 视频格式
'.mp4', '.avi', '.mov', '.mkv', '.flv', '.wmv',
'.mpeg', '.mpg', '.m4v', '.3gp', '.webm', '.vob'
]
LOG_FORMAT = '%(asctime)s - %(levelname)s - %(message)s'
PROGRESS_INTERVAL = 100
# ==================== 日志配置 ====================
logging.basicConfig(
filename='file_cleaner.log',
level=logging.INFO,
format=LOG_FORMAT,
encoding='utf-8'
)
-
文件类型过滤:VALID_EXTENSIONS 详细定义了程序能够处理的 27 种文件扩展名,使程序能有针对性地对这些特定类型的文件进行重复检测,避免在无关文件上浪费计算资源。
-
日志格式设定:LOG_FORMAT 精心设计了日志记录格式,精确到时间、日志级别和具体消息内容,为后续程序调试和运行追踪提供清晰线索。
-
进度更新频率:PROGRESS_INTERVAL 决定了进度更新节奏,每处理 PROGRESS_INTERVAL 个文件,进度条就会更新一次,让用户实时了解处理进度。
-
日志记录配置:logging.basicConfig 完成日志系统初始化,将日志信息写入 file_cleaner.log 文件,并设置日志级别为 INFO,确保重要运行信息都能被记录下来。
GUI 界面构建与交互逻辑
class FileCleanerApp:
def __init__(self, root):
self.root = root
self.root.title("智能重复文件清理器")
self.root.geometry("800x600")
# 多线程控制
self.stop_event = threading.Event()
self.message_queue = queue.Queue()
# 初始化界面
self.create_widgets()
self.running = False
# 启动消息处理循环
self.root.after(100, self.process_messages)
def create_widgets(self):
"""创建界面组件"""
# 顶部控制栏
control_frame = ttk.Frame(self.root, padding=10)
control_frame.pack(fill=tk.X)
self.btn_select = ttk.Button(
control_frame,
text="选择文件夹",
command=self.select_folder,
state=tk.NORMAL
)
self.btn_select.pack(side=tk.LEFT, padx=5)
self.btn_stop = ttk.Button(
control_frame,
text="停止处理",
command=self.stop_processing,
state=tk.DISABLED
)
self.btn_stop.pack(side=tk.LEFT, padx=5)
# 进度条
self.progress = ttk.Progressbar(
self.root,
orient=tk.HORIZONTAL,
mode='determinate'
)
self.progress.pack(fill=tk.X, padx=10, pady=5)
# 实时信息面板
info_frame = ttk.LabelFrame(self.root, text="处理状态", padding=10)
info_frame.pack(fill=tk.BOTH, expand=True, padx=10, pady=5)
self.lbl_status = ttk.Label(info_frame, text="就绪")
self.lbl_status.pack(anchor=tk.W)
self.lbl_current_file = ttk.Label(info_frame, text="当前文件:无")
self.lbl_current_file.pack(anchor=tk.W)
self.lbl_stats = ttk.Label(info_frame, text="")
self.lbl_stats.pack(anchor=tk.W)
# 文件类型提示
self.lbl_file_types = ttk.Label(info_frame, text="支持的文件类型:图片、文档、视频等27种格式")
self.lbl_file_types.pack(anchor=tk.W)
# 日志显示
log_frame = ttk.LabelFrame(self.root, text="日志", padding=10)
log_frame.pack(fill=tk.BOTH, expand=True, padx=10, pady=5)
self.log_text = tk.Text(log_frame, wrap=tk.WORD, state=tk.DISABLED)
scrollbar = ttk.Scrollbar(log_frame, command=self.log_text.yview)
self.log_text.configure(yscrollcommand=scrollbar.set)
self.log_text.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
scrollbar.pack(side=tk.RIGHT, fill=tk.Y)
窗口初始化:在 FileCleanerApp 类的初始化方法 init 中,为窗口设置 “智能重复文件清理器” 的标题,并调整窗口大小为 800x600,为用户提供舒适的操作界面。同时,初始化多线程控制所需的 stop_event 和 message_queue,为后续多线程处理奠定基础。
界面组件创建:create_widgets 方法创建一系列实用的界面组件。顶部控制栏的 “选择文件夹” 按钮用于触发文件选择操作,初始状态可用;“停止处理” 按钮用于中断文件处理过程,初始状态禁用。进度条实时展示文件处理进度。实时信息面板的 lbl_status 标签显示处理整体状态,lbl_current_file 标签展示当前处理文件,lbl_stats 标签显示处理完成后的统计信息,新增的 lbl_file_types 标签明确告知用户支持的文件类型。日志显示区域通过 log_text 文本框和滚动条组合,方便用户查看详细处理日志。
多线程处理与消息队列机制
def process_messages(self):
"""处理线程消息队列"""
try:
while True:
msg_type, msg_data = self.message_queue.get_nowait()
if msg_type == 'progress':
self.update_progress(*msg_data)
elif msg_type == 'log':
self.append_log(msg_data)
elif msg_type =='stats':
self.show_stats(msg_data)
elif msg_type == 'error':
self.show_error(msg_data)
except Empty:
pass
finally:
self.root.after(100, self.process_messages)
多线程协作:为防止文件处理过程阻塞主线程,导致界面响应迟缓,程序采用多线程技术。process_messages 方法从消息队列 message_queue 中获取消息,并根据消息类型进行相应处理。接收到 ‘progress’ 类型消息时,调用 update_progress 方法更新进度条和状态标签;接收到 ‘log’ 类型消息时,调用 append_log 方法添加日志信息;对于 ‘stats’ 类型消息,调用 show_stats 方法展示统计信息;遇到 ‘error’ 类型消息时,调用 show_error 方法展示错误信息。
文件处理核心逻辑
def process_folder(self, folder_path):
"""后台处理线程"""
try:
start_time = datetime.now()
self.message_queue.put(('log', f"开始处理文件夹:{folder_path}"))
# 初始化目录结构
duplicate_folder = os.path.abspath(os.path.join(folder_path, "重复文件"))
os.makedirs(duplicate_folder, exist_ok=True)
# 统计文件总数(排除重复文件夹)
total_files = 0
for root, dirs, files in os.walk(folder_path):
# 排除重复文件夹
dirs[:] = [d for d in dirs if os.path.abspath(os.path.join(root, d))!= duplicate_folder]
total_files += len([f for f in files if os.path.splitext(f)[1].lower() in VALID_EXTENSIONS])
if total_files == 0:
self.message_queue.put(('error', "未找到符合条件的文件"))
return
# 初始化处理参数
processed_files = 0
hash_dict = {}
file_info = []
# 主处理循环
for root, dirs, files in os.walk(folder_path):
if self.stop_event.is_set():
break
# 排除重复文件夹
dirs[:] = [d for d in dirs if os.path.abspath(os.path.join(root, d))!= duplicate_folder]
for file in files:
if self.stop_event.is_set():
break
ext = os.path.splitext(file)[1].lower()
if ext not in VALID_EXTENSIONS:
continue
file_path = os.path.join(root, file)
try:
# 更新进度
processed_files += 1
if processed_files % PROGRESS_INTERVAL == 0 or processed_files == total_files:
self.message_queue.put((
'progress',
(processed_files, total_files, file_path)
))
# 计算哈希值
file_hash = calculate_file_hash(file_path)
if not file_hash:
continue
file_size = os.path.getsize(file_path)
file_info.append({
'序号': len(file_info) + 1,
'文件名': file,
'文件大小': file_size,
'哈希值': file_hash,
'路径': file_path
})
# 处理重复文件
if file_hash in hash_dict:
original_file = hash_dict[file_hash]
self.message_queue.put(('log',
f"发现重复文件:{file} -> 原始文件:{os.path.basename(original_file)}"
))
safe_move_file(file_path, duplicate_folder)
else:
hash_dict[file_hash] = file_path
except Exception as e:
logging.error(f"处理文件失败:{file_path} - {str(e)}")
self.message_queue.put(('log', f"错误:{str(e)}"))
# 生成报告
if not self.stop_event.is_set():
self.generate_report(duplicate_folder, file_info, start_time, hash_dict)
except Exception as e:
self.message_queue.put(('error', str(e)))
logging.exception("处理过程中发生未捕获异常")
finally:
self.message_queue.put(('log', "处理完成"))
self.running = False
文件遍历与统计:process_folder 方法是文件处理流程的核心。它记录处理开始时间,向消息队列发送日志消息,告知用户开始处理指定文件夹。接着,创建 “重复文件” 文件夹,精确统计指定文件夹及其子文件夹中符合条件的文件总数,并排除 “重复文件” 文件夹本身,避免重复处理。
文件处理循环:在主处理循环中,程序通过 os.walk 函数遍历文件系统。对于每个文件,先检查文件扩展名是否在允许范围内,不符合则跳过。
如图所示
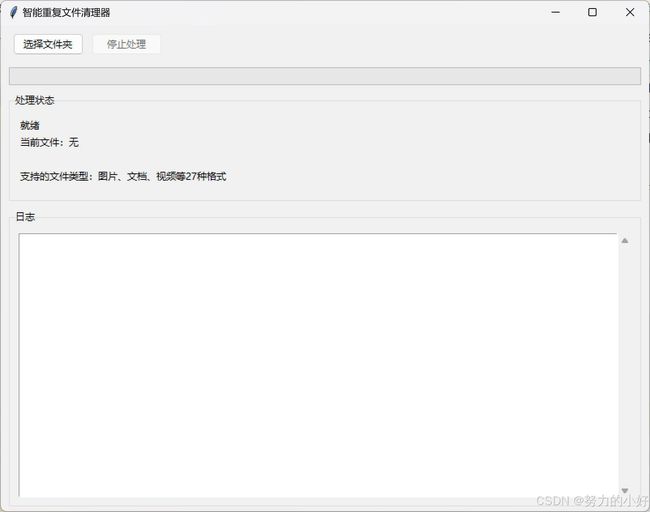
注意事项
-
支持4K/8K视频文件处理
-
自动跳过损坏的文件
-
处理大量文件时建议使用SSD硬盘
-
日志文件file_cleaner.log会记录所有操作细节