LLM主要类别架构
LLM主要类别架构介绍
LLM主要类别
LLM本身基于transformer架构。自2017年,attention is all you need诞生起,transformer模型为不同领域的模型提供了灵感和启发。基于原始的Transformer框架,衍生出了一系列模型,一些模型仅仅使用encoder或decoder,有些模型同时使encoder+decoder。
LLM分类一般分为三种:自编码模型(encoder)、自回归模型(decoder)和序列到序列模型(encoder-decoder)。
2 自编码模型
自编码模型 (AutoEncoder model,AE) 模型,代表作BERT,其特点为:Encoder-Only, 基本原理:是在输入中随机MASK掉一部分单词,根据上下文预测这个词。AE模型通常用于内容理解任务,比如自然语言理NLU中的分类任务:情感分析、提取式问答。
2.1 代表模型 BERT
BERT是2018年10月由Google AI研究院提出的一种预训练模型.
- BERT的全称是Bidirectional Encoder Representation from Transformers.
- BERT在机器阅读理解顶级水平测试SQuAD1.1中表现出惊人的成绩: 全部两个衡量指标上全面超越人类, 并且在11种不同NLP测试中创出SOTA表现. 包括将GLUE基准推高至80.4% (绝对改进7.6%), MultiNLI准确度达到86.7% (绝对改进5.6%). 成为NLP发展史上的里程碑式的模型成就.
2.1.1 BERT的架构
总体架构: BERT采用了Transformer Encoder block进行连接, 因为是一个典型的双向编码模型。
宏观上BERT分三个主要模块:
- 最底层黄色标记的Embedding模块.
- 中间层蓝色标记的Transformer模块.
- 最上层绿色标记的预微调模块.
2.1.2 Embedding模块
BERT中的该模块是由三种Embedding共同组成而成
- Token Embeddings 是词嵌入张量, 第一个单词是CLS标志, 可以用于之后的分类任务.
- Segment Embeddings 是句子分段嵌入张量, 是为了服务后续的两个句子为输入的预训练任务.
- Position Embeddings 是位置编码张量, 此处注意和传统的Transformer不同, 不是三角函数计算的固定位置编码, 而是通过学习得出来的.
- 整个Embedding模块的输出张量就是这3个张量的直接加和结果.
2.1.3 双向Transformer模块
BERT中只使用了经典Transformer架构中的Encoder部分, 完全舍弃了Decoder部分. 而两大预训练任务也集中体现在训练Transformer模块中.
2.1.4 预微调模块
经过中间层Transformer的处理后, BERT的最后一层根据任务的不同需求而做不同的调整即可.
比如对于sequence-level的分类任务, BERT直接取第一个[CLS] token 的final hidden state, 再加一层全连接层后进行softmax来预测最终的标签.
- 对于不同的任务, 微调都集中在预微调模块
- 在面对特定任务时, 只需要对预微调层进行微调, 就可以利用Transformer强大的注意力机制来模拟很多下游任务, 并得到SOTA的结果. (句子对关系判断, 单文本主题分类, 问答任务(QA), 单句贴标签(NER))
- 若干可选的超参数建议如下:
代码语言:javascript
复制
Batch size: 16, 32
Learning rate (Adam): 5e-5, 3e-5, 2e-5
Epochs: 3, 4
2.1.5 BERT的预训练任务
BERT包含两个预训练任务:
- 任务一: Masked LM (带mask的语言模型训练)
- 任务二: Next Sentence Prediction (下一句话预测任务)
2.1.5.1 任务一: Masked LM
带mask的语言模型训练
- 关于传统的语言模型训练, 都是采用left-to-right, 或者left-to-right + right-to-left结合的方式, 但这种单向方式或者拼接的方式提取特征的能力有限. 为此BERT提出一个深度双向表达模型(deep bidirectional representation). 即采用MASK任务来训练模型.
- 1: 在原始训练文本中, 随机的抽取15%的token作为参与MASK任务的对象.
- 2: 在这些被选中的token中, 数据生成器并不是把它们全部变成[MASK], 而是有下列3种情况.
- 2.1: 在80%的概率下, 用[MASK]标记替换该token, 比如my dog is hairy -> my dog is [MASK]
- 2.2: 在10%的概率下, 用一个随机的单词替换token, 比如my dog is hairy -> my dog is apple
- 2.3: 在10%的概率下, 保持该token不变, 比如my dog is hairy -> my dog is hairy
- 3: 模型在训练的过程中, 并不知道它将要预测哪些单词? 哪些单词是原始的样子? 哪些单词被遮掩成了[MASK]? 哪些单词被替换成了其他单词? 正是在这样一种高度不确定的情况下, 反倒逼着模型快速学习该token的分布式上下文的语义, 尽最大努力学习原始语言说话的样子. 同时因为原始文本中只有15%的token参与了MASK操作, 并不会破坏原语言的表达能力和语言规则.
2.1.5.2 任务二: Next Sentence Prediction
下一句话预测任务
- 在NLP中有一类重要的问题比如QA(Quention-Answer), NLI(Natural Language Inference), 需要模型能够很好的理解两个句子之间的关系, 从而需要在模型的训练中引入对应的任务. 在BERT中引入的就是Next Sentence Prediction任务. 采用的方式是输入句子对(A, B), 模型来预测句子B是不是句子A的真实的下一句话.
- 1: 所有参与任务训练的语句都被选中作为句子A.
- 1.1: 其中50%的B是原始文本中真实跟随A的下一句话. (标记为IsNext, 代表正样本)
- 1.2: 其中50%的B是原始文本中随机抽取的一句话. (标记为NotNext, 代表负样本)
- 2: 在任务二中, BERT模型可以在测试集上取得97%-98%的准确率.
2. 1.6 数据集
BooksCorpus (800M words) + English Wikipedia (2,500M words)
2.1.7 BERT模型的特点
模型的一些关键参数为:
| 参数 | 取值 |
|---|---|
| transformer 层数 | 12 |
| 特征维度 | 768 |
| transformer head 数 | 12 |
| 总参数量 | 1.15 亿 |
2.2 AE模型总结
优点:
- BERT使用双向transformer,在语言理解相关的任务中表现很好。
缺点:
- 输入噪声:BERT在预训练过程中使用【mask】符号对输入进行处理,这些符号在下游的finetune任务中永远不会出现,这会导致预训练-微调差异。而AR模型不会依赖于任何被mask的输入,因此不会遇到这类问题。
- 更适合用于语言嵌入表达, 语言理解方面的任务, 不适合用于生成式的任务
3 自回归模型
自回归模型 (Autoregressive model,AR) ,代表作GPT,其特点为:Decoder-Only,基本原理:从左往右学习的模型,只能利用上文或者下文的信息,比如:AR模型从一系列time steps中学习,并将上一步的结果作为回归模型的输入,以预测下一个time step的值。AR模型通常用于生成式任务,在长文本的生成能力很强,比如自然语言生成NLG领域的任务:摘要、翻译或抽象问答。
3.1 代表模型 GPT
2018年6月, OpenAI公司发表了论文“Improving Language Understanding by Generative Pre-training”《用生成式预训练提高模型的语言理解力》, 推出了具有1.17亿个参数的GPT(Generative Pre-training , 生成式预训练)模型.
与BERT最大的区别在于GPT采用了传统的语言模型方法进行预训练, 即使用单词的上文来预测单词, 而BERT是采用了双向上下文的信息共同来预测单词.正是因为训练方法上的区别, 使得GPT更擅长处理自然语言生成任务(NLG), 而BERT更擅长处理自然语言理解任务(NLU).
3.1.1 GPT模型架构
- GPT采用的是单向Transformer模型, 例如给定一个句子[u1, u2, …, un], GPT在预测单词ui的时候只会利用[u1, u2, …, u(i-1)]的信息, 而BERT会同时利用上下文的信息[u1, u2, …, u(i-1), u(i+1), …, un]
- 作为两大模型的直接对比, BERT采用了Transformer的Encoder模块, 而GPT采用了Transformer的Decoder模块. 并且GPT的Decoder Block和经典Transformer Decoder Block还有所不同
- 经典的Transformer Decoder Block包含3个子层, 分别是Masked Multi-Head Attention层, encoder-decoder attention层, 以及Feed Forward层. 但是在GPT中取消了第二个encoder-decoder attention子层, 只保留Masked Multi-Head Attention层, 和Feed Forward层
- 注意: 对比于经典的Transformer架构, 解码器模块采用了6个Decoder Block; GPT的架构中采用了12个Decoder Block
3.1.2 GPT训练过程
GPT的训练包括两阶段过程: 预训练 + 微调
- 第一阶段: 无监督的预训练语言模型.
- 第二阶段: 有监督的下游任务fine-tunning.
3.1.2.1 无监督的预训练语言模型
- 给定句子U = [u1, u2, …, un], GPT训练语言模型时的目标是最大化下面的似然函数:
L1(U)=∑ilogP(ui|ui−k,⋯,ui−1;Θ)
- 上述公式具体来说是要预测每个词ui的概率,这个概率是基于它前面 ui-k 到 ui−1 个词,以及模型 Θ。这里的 k 表示上文的窗口大小,理论上来讲 k 取的越大,模型所能获取的上文信息越充足,模型的能力越强。
- GPT是一个单向语言模型,模型对输入U 进行特征嵌入得到 transformer 第一层的输h0,再经过多层 transformer 特征编码,使用最后一层的输出即可得到当前预测的概率分布,计算过程如下:
h0=UWe+Wp
其中Wp是单词的位置编码, We是单词本身的word embedding. Wp的形状是[max_seq_len, embedding_dim], We的形状是[vocab_size, embedding_dim].
- 得到输入张量h0后, 要将h0传入GPT的Decoder Block中, 依次得到ht:
ht=transformer_block(hl−1)l∈[1,t]
- 最后通过得到的ht来预测下一个单词:
P(u)=softmax(htWTe)
3.1.2.2 有监督的下游任务fine-tunning
- GPT经过预训练后, 会针对具体的下游任务对模型进行微调. 微调采用的是有监督学习, 训练样本包括单词序列[x1, x2, …, xn]和label y. GPT微调的目标任务是根据单词序列[x1, x2, …, xn]预测标签y.
P(y|x1,⋯,xm)=softmax(hmlWy)
其中
Wy
表示预测输出的矩阵参数, 微调任务的目标是最大化下面的函数:
L2=∑(x,y)logP(y|x1,⋯,xm)
- 综合两个阶段的目标任务函数, 可知GPT的最终优化函数为:
L3=L2+λL1
3.1.2.3 整体训练过程架构图
根据下游任务适配的过程分两步: 1、根据任务定义不同输入, 2、对不同任务增加不同的分类层.
- 分类任务(Classification): 将起始和终止token加入到原始序列两端, 输入transformer中得到特征向量, 最后经过一个全连接得到预测的概率分布;
- 文本蕴涵(Entailment): 将前提(premise)和假设(hypothesis)通过分隔符(Delimiter)隔开, 两端加上起始和终止token. 再依次通过transformer和全连接得到预测结果;
- 文本相似度(Similarity): 输入的两个句子, 正向和反向各拼接一次, 然后分别输入给transformer, 得到的特征向量拼接后再送给全连接得到预测结果;
- 问答和常识推理(Multiple-Choice): 将 N个选项的问题抽象化为N个二分类问题, 即每个选项分别和内容进行拼接, 然后各送入transformer和全连接中, 最后选择置信度最高的作为预测结果
总的来说,都是通过在序列前后添加 Start 和 Extract 特殊标识符来表示开始和结束,序列之间添加必要的 Delim 标识符来表示分隔,当然实际使用时不会直接用 “Start/Extract/Delim” 这几个词,而是使用某些特殊符号。基于不同下游任务构造的输入序列,使用预训练的 GPT 模型进行特征编码,然后使用序列最后一个 token 的特征向量进行预测。
不论下游任务的输入序列怎么变,最后的预测层怎么变,中间的特征抽取模块都是不变的,具有很好的迁移能力。
3.1.3 GPT数据集
GPT使用了BooksCorpus数据集, 文本大小约 5 GB,包含 7400w+ 的句子。这个数据集由 7000 本独立的、不同风格类型的书籍组成, 选择该部分数据集的原因:
- 书籍文本包含大量高质量长句,保证模型学习长距离信息依赖。
- 这些书籍因为没有发布, 所以很难在下游数据集上见到, 更能验证模型的泛化能力.
3.1.4 GPT模型的特点
模型的一些关键参数为:
| 参数 | 取值 |
|---|---|
| transformer 层数 | 12 |
| 特征维度 | 768 |
| transformer head 数 | 12 |
| 总参数量 | 1.17 亿 |
3.2 AR模型总结
优点:
- AR模型擅长生成式NLP任务。AR模型使用注意力机制,预测下一个token,因此自然适用于文本生成。此外,AR模型可以简单地将训练目标设置为预测语料库中的下一个token,因此生成数据相对容易。
缺点:
- AR模型只能用于前向或者后向建模,不能同时使用双向的上下文信息,不能完全捕捉token的内在联系。
4 序列到序列
序列到序列模型(Sequence to Sequence Model)同时使用编码器和解码器。它将每个task视作序列到序列的转换/生成(比如,文本到文本,文本到图像或者图像到文本的多模态任务)。对于文本分类任务来说,编码器将文本作为输入,解码器生成文本标签。Encoder-decoder模型通常用于需要内容理解和生成的任务,比如机器翻译。
4.1. 代表模型T5
T5 由谷歌的 Raffel 等人于 2020年7月提出,相关论文为“Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer”. 该模型的目的为构建任务统一框架:将所有NLP任务都视为文本转换任务。
比如英德翻译,只需将训练数据集的输入部分前加上“translate English to German(给我从英语翻译成德语)” 就行。假设需要翻译"That is good",那么先转换成 “translate English to German:That is good.” 输入模型,之后就可以直接输出德语翻译 “Das ist gut.”。 对于需要输出连续值的 STS-B(文本语义相似度任务), 也是直接输出文本。
通过这样的方式就能将 NLP 任务都转换成 Text-to-Text 形式,也就可以用同样的模型,同样的损失函数,同样的训练过程,同样的解码过程来完成所有 NLP 任务。
4.1.1 T5模型架构
T5模型结构与原始的Transformer基本一致,除了做了以下几点改动:
- 作者采用了一种简化版的Layer Normalization,去除了Layer Norm 的bias;将Layer Norm放在残差连接外面。
- 位置编码:T5使用了一种简化版的相对位置编码,即每个位置编码都是一个标量,被加到 logits 上用于计算注意力权重。各层共享位置编码,但是在同一层内,不同的注意力头的位置编码都是独立学习的。一定数量的位置Embedding,每一个对应一个可能的 key-query 位置差。作者学习了32个Embedding,至多适用于长度为128的位置差,超过位置差的位置编码都使用相同的Embedding。
4.1.2 T5 训练过程
自监督预训练:采用类似于BERT模型的MLM预训练任务。
多任务预训练:除了使用大规模数据进行无监督预训练,T5模型还可以利用不同任务的标注数据进行有监督的多任务预训练,例如SQuAD问答和机器翻译等任务。
4.1.3 T5数据集
作者对公开爬取的网页数据集Common Crawl进行了过滤,去掉一些重复的、低质量的,看着像代码的文本等,并且最后只保留英文文本,得到数据集C4: the Colossal Clean Crawled Corpus。
4.1.4 T5模型的特点
模型的一些关键参数为:
| 参数 | 取值 |
|---|---|
| transformer 层数 | 24 |
| 特征维度 | 768 |
| transformer head 数 | 12 |
| 总参数量 | 2.2 亿 |
4.2. encoder-decoder模型总结
优点:
- T5模型可以处理多种NLP任务,并且可以通过微调来适应不同的应用场景,具有良好的可扩展性;相比其他语言生成模型(如GPT-2、GPT3等),T5模型的参数数量相对较少,训练速度更快,且可以在相对较小的数据集上进行训练。
缺点:
- 由于T5模型使用了大量的Transformer结构,在训练时需要大量的计算资源和时间; 模型的可解释性不足。
5 目前大模型主流模型架构-Decoder-only
LLM之所以主要都用Decoder-only架构,除了训练效率和工程实现上的优势外,在理论上是因为Encoder的双向注意力会存在低秩问题,这可能会削弱模型表达能力,就生成任务而言,引入双向注意力并无实质好处。而Encoder-Decoder架构之所以能够在某些场景下表现更好,大概只是因为它多了一倍参数。所以,在同等参数量、同等推理成本下,Decoder-only架构就是最优选择了。
小结
- LLM的主要类别架构:自回归模型、自编码模型和序列到序列模型。
- 不同类型架构的代表模型:BERT、GPT、T5等相关模型。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
有需要的小伙伴,可以VX扫描下方二维码免费领取

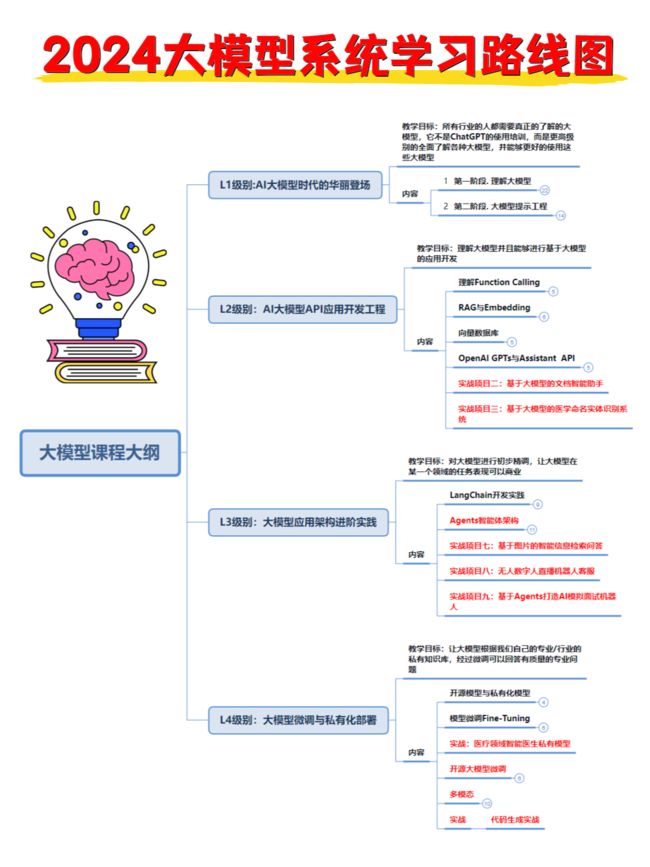
1.大模型入门学习思维导图
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)
2.AGI大模型配套视频
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。

3.大模型实际应用报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

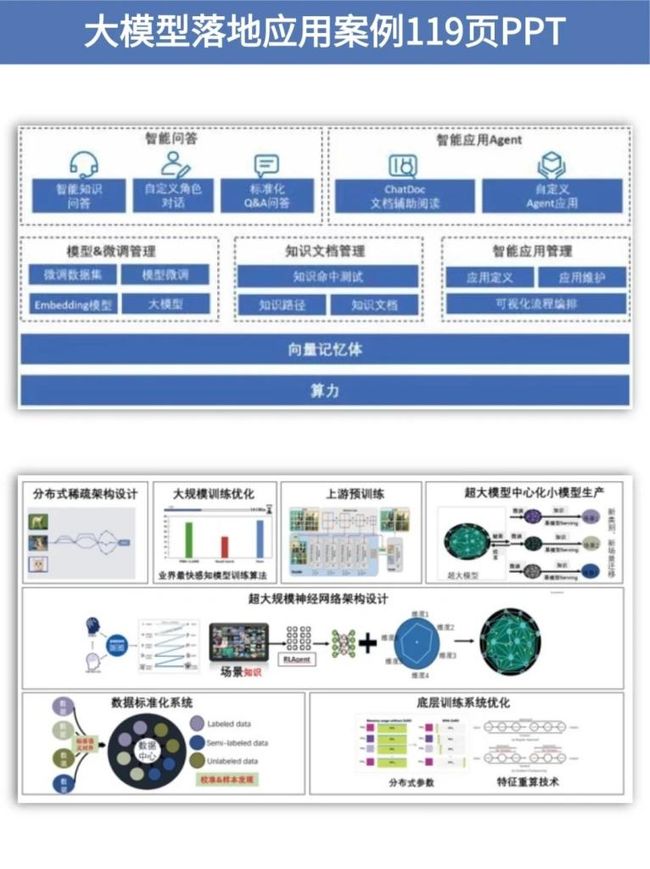
4.大模型落地应用案例PPT
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)
5.大模型经典学习电子书
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

6.大模型面试题&答案
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

学会后的收获:
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
有需要的小伙伴,可以Vx扫描下方二维码免费领取