大模型蒸馏与大模型微调技术有啥差别?
大模型蒸馏与大模型微调是当前人工智能领域中两种重要的技术手段,它们在模型优化、性能提升和资源利用方面各有特点。以下将从定义、技术原理、应用场景及优缺点等方面对这两种技术进行深入对比。
一、定义与基本概念
-
大模型蒸馏(Knowledge Distillation)
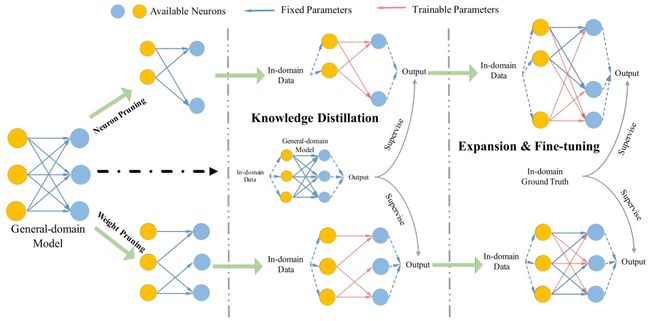
蒸馏是一种将大型复杂模型(教师模型)的知识迁移到小型模型(学生模型)的技术。通过训练学生模型模仿教师模型的行为,实现模型压缩和性能保留的目标。蒸馏过程通常包括两个阶段:预训练阶段(教师模型训练)和知识传递阶段(学生模型训练)。 -
大模型微调(Fine-tuning)
微调是指在预训练的大模型基础上,通过少量标注数据的再训练,使模型适应特定任务的需求。微调可以分为全量微调和参数高效微调(如PEFT)。全量微调适用于需要高精度输出的任务,而参数高效微调则通过优化超参数和调整策略,减少计算资源消耗。
二、技术原理与实现方式
-
大模型蒸馏的技术原理
- 知识传递:通过教师模型生成高质量的软标签(概率分布),学生模型通过学习这些标签来模仿教师的行为。
- 逐步蒸馏法:逐步蒸馏是一种分步方法,通过逐步增加蒸馏过程中的复杂性,提升学生模型的性能。
- 剪枝与量化:蒸馏过程中常结合模型剪枝和量化技术,进一步压缩模型大小并降低计算成本。
-
大模型微调的技术原理
- 增量学习:在预训练模型的基础上,通过少量标注数据进行再训练,使模型更好地适应特定任务。
- 参数高效微调(PEFT) :包括Prefix Tuning、Prompt Tuning等方法,通过少量参数调整实现高效的微调效果。
- 自适应微调:根据任务需求动态调整学习率、正则化策略等超参数,以提高模型的泛化能力。
三、应用场景与适用性
-
大模型蒸馏的应用场景
-
资源受限环境:蒸馏技术可以显著减少模型的存储和计算需求,适用于边缘设备或移动设备。
-
跨领域迁移:通过蒸馏技术,可以将大型模型的知识迁移到不同领域的任务中,提高迁移学习的效果。
-
多模态任务:蒸馏可用于处理多模态输入(如图像+文本)的复杂任务,提升模型的泛化能力。
-
-
大模型微调的应用场景
- 特定任务优化:微调技术特别适用于需要高精度输出的领域,如医疗影像分析、金融风险预测等。
- 少样本学习:在标注数据稀缺的情况下,微调可以通过少量标注数据快速调整模型,提升性能。
- 跨语言任务:微调技术能够帮助模型在不同语言间迁移知识,提升跨语言任务的表现。
四、优缺点对比
-
大模型蒸馏的优点
- 模型压缩:显著减少模型大小和计算成本。
- 通用性强:适用于多种任务和场景,尤其适合资源受限环境。
- 知识迁移效率高:通过软标签传递复杂知识,提升学生模型的性能。
-
大模型蒸馏的缺点
- 训练复杂度高:需要额外的训练过程和超参数调整。
- 效果依赖于教师模型质量:如果教师模型性能不足,蒸馏效果也会受到影响。
-
大模型微调的优点
- 灵活性强:可以根据任务需求灵活调整超参数和训练策略。
- 高效性:相比全量训练,微调仅需少量标注数据即可完成任务优化。
- 适应性强:适用于多种特定任务,尤其是少样本学习场景。
-
大模型微调的缺点
- 标注数据需求高:对于某些任务,标注数据不足可能导致微调效果不佳。
- 过拟合风险:在小数据集上微调时容易发生过拟合。
五、总结与未来展望
大模型蒸馏与微调各有优势,适用于不同的应用场景。蒸馏技术更适合资源受限或需要跨领域迁移的场景,而微调技术则更适合需要高精度输出的特定任务。未来的研究方向可能包括:
- 提升蒸馏过程中的效率和效果,减少对教师模型的依赖。
- 开发更高效的微调策略,降低标注数据需求并提升泛化能力。
- 结合蒸馏与微调技术,探索更全面的优化方案。
通过深入理解这两种技术的特点和适用场景,研究人员和开发者可以更好地选择合适的策略,以满足不同任务的需求。
大模型蒸馏和微调在实际应用中的具体案例有哪些?
大模型蒸馏和微调在实际应用中展现了广泛的应用案例,这些技术不仅降低了模型的计算成本,还提升了模型在特定任务上的性能。以下是一些具体的应用案例:
1. 大模型蒸馏的实际应用
- OpenAI的API蒸馏:OpenAI通过蒸馏技术将大型模型(如GPT-3)的知识迁移到更小的模型中,从而降低了部署成本。这些小模型可以在特定任务上表现接近大模型,同时大幅减少资源消耗。例如,通过蒸馏技术,OpenAI能够为垂直领域客户提供专用的小模型服务,这被称为“MaaS”(模型即服务),是未来大模型落地的重要形式。
- 阿里云PAI平台的蒸馏应用:阿里云利用蒸馏技术开发了电商领域的虚拟试衣系统,并构建了物流行业的咨询智能问答系统。这些应用通过蒸馏技术将大模型的知识迁移到更轻量化的模型中,从而实现了高效且低成本的解决方案。
- Meta的蒸馏与微调结合:Meta AI通过蒸馏技术将大型语言模型(如LLaMA 3.1)的知识迁移到更小的模型中,并结合微调技术完成特定任务的优化。例如,通过蒸馏和微调结合的方式,可以实现高效的角色扮演和文化适配。
2. 大模型微调的实际应用
- 科学与工业领域的微调:DPA-2是一个面向分子和材料模拟的大模型,通过微调和蒸馏技术,该模型在微尺度工业设计中取得了显著进展。微调使得模型能够适应特定任务需求,而蒸馏则进一步压缩了模型规模,同时保持了高精度和效率。
- 物流行业咨询系统:通过微调技术,结合蒸馏后的轻量化模型,构建了物流行业的咨询智能问答系统。这种系统能够快速响应用户需求,并提供精准的物流解决方案。
- 文生图小程序:利用SD多模态大模型进行微调开发,构建了文生图小程序。该小程序通过微调技术优化了图像生成的质量和效率,为用户提供更丰富的交互体验。
3. 结合蒸馏与微调的综合应用
- Mistral Large的蒸馏与微调:Mistral Large通过两阶段知识蒸馏技术,在MMLU基准测试中将准确率从85%提高到了92%。这一过程包括冻结教师模型的知识状态并使用学生模型进行微调,最终实现了更高的性能。
- LLaMA Factory微调框架:该框架支持零代码微调,结合蒸馏技术,使用户能够轻松地对LLaMA 3.1模型进行定制化调整。这种结合方式不仅降低了技术门槛,还提高了模型在特定任务上的表现。
4. 其他相关案例
- ChatGPT的垂直场景化开发:基于ChatGPT的大模型,通过蒸馏和微调技术开发了多个垂直场景化的应用,如客服机器人、教育辅导助手等。这些应用通过蒸馏和微调技术实现了高效的成本控制和性能优化。
- 科学与社会领域的应用:Mistral Large在科学、社会科学和文化类别中的表现尤为突出,这表明蒸馏和微调技术在处理复杂任务时具有显著优势。
总结
大模型蒸馏和微调技术在实际应用中展现了强大的灵活性和高效性。无论是降低计算成本、提升特定任务性能,还是支持垂直领域的定制化需求,这些技术都为人工智能的发展提供了新的可能性。
逐步蒸馏法与自适应微调的具体实现方式有何不同?
逐步蒸馏法(Distillation Step-by-Step)与自适应微调(Adaptive Fine-tuning)在实现方式上有显著不同,主要体现在目标、方法和训练过程中的关键步骤上。以下是两者的具体对比:
1. 目标与核心思想
-
逐步蒸馏法:
- 目标是通过减少训练数据量和模型规模,同时保持甚至超越大型语言模型(LLM)的性能。
- 核心思想是利用大型语言模型生成的“合理性”(Rationales),即支持其预测的解释性语言表述,作为多任务学习框架中的训练信号。这些合理性被用作额外信息,帮助小型模型学习并提升性能。
- 逐步蒸馏法通过生成小型微调数据集(包含输入、输出标签和选择理由),指导小型模型预测输出并生成合理性的标签。
-
自适应微调:
- 目标是通过动态调整学习率和参数更新策略,优化模型在特定任务上的表现。
- 核心思想是结合迁移学习和微调技术,通过逐步调整模型的超参数(如学习率和激活函数),使模型更好地适应特定任务。
2. 训练过程的关键步骤
-
逐步蒸馏法:
- 第一步:利用大型语言模型生成小型微调数据集,该数据集包含输入、输出标签以及支持预测的合理性标签。
- 第二步:在多任务学习框架下,训练小型模型以预测输出并生成合理性标签。这种方法不仅提高了数据效率,还降低了部署成本。
- 此外,逐步蒸馏法强调使用少量数据即可实现接近甚至超越大型模型的性能,例如在NLP基准测试中,仅需80%的微调数据即可达到540B参数模型的效果。
-
自适应微调:
- 自适应微调阶段通常在预训练监督管道之后进行,未标记的数据会被删除。
- 在微调阶段,通过动态调整学习率和参数更新策略(如引入新参数θT),优化模型对特定任务的适应性。
3. 数据需求与效率
-
逐步蒸馏法:
- 需要较少的数据:逐步蒸馏法通过生成小型微调数据集,减少了对大量未标记数据的依赖,从而降低了数据收集成本。
- 效率更高:相比传统微调方法,逐步蒸馏法在使用更少数据的情况下仍能实现更好的性能,例如在e-SNLI数据集上仅需12.5%的数据即可达到最佳效果。
-
自适应微调:
- 数据需求较高:自适应微调通常需要大量标记数据来调整模型参数,以适应特定任务。
- 效率较低:由于依赖于大量标记数据和复杂的超参数调整,自适应微调的效率可能不如逐步蒸馏法。
4. 性能与应用
-
逐步蒸馏法:
- 在多个NLP基准测试中表现出色:例如,在NLP基准测试中,逐步蒸馏法的小型模型性能优于540B参数的PaLM模型,并且仅需80%的微调数据。
- 应用广泛:逐步蒸馏法不仅适用于NLP任务,还可以扩展到其他领域,如计算机视觉等。
-
自适应微调:
- 主要应用于需要动态调整模型参数的任务,如软件需求建模中的多分类任务。
- 性能依赖于标记数据的质量和数量,因此在数据不足的情况下可能表现不佳。
总结
逐步蒸馏法与自适应微调在实现方式上有显著差异。逐步蒸馏法通过利用大型语言模型生成的合理性信息,以少量数据高效地训练小型模型,从而在性能和效率上均优于传统微调方法。
如何提升蒸馏过程中的效率和效果,减少对教师模型的依赖?
提升蒸馏过程中的效率和效果,减少对教师模型的依赖,可以从以下几个方面入手:
1. 采用渐进式蒸馏(Progressive Distillation)
渐进式蒸馏是一种通过逐步减少采样步骤来加速模型训练的方法。这种方法的核心思想是将慢速教师模型逐步转换为快速学生模型,从而减少计算开销。具体来说:
- 迭代优化:Salimans和Ho(2021)提出的渐进式蒸馏方法,通过迭代地调整学生模型的参数,使其逐步匹配教师模型的输出分布。这种方法可以显著减少采样所需的网络评估次数,从而降低计算成本。
- 训练策略:在训练过程中,学生模型的初始参数可以设置为教师模型的参数,然后通过迭代调整学生模型的参数,使其逐步适应教师模型的输出分布。这不仅提高了训练效率,还减少了对教师模型的依赖。
2. 使用自我蒸馏技术
自我蒸馏是一种直接从零开始训练学生模型的方法,而不依赖于外部教师模型。这种方法的优势在于:
- 减少训练时间:自我蒸馏通常比传统蒸馏更快,因为学生模型从零开始训练,不需要额外的教师模型指导。例如,在图像分类任务中,自我蒸馏的学生模型训练时间仅为5.87小时,而传统蒸馏需要12.31小时。
- 提高泛化能力:自我蒸馏通过让学生模型学习自身的中间表示,可以增强其泛化能力。这种方法在某些情况下甚至能够超越传统蒸馏。
3. 优化蒸馏目标和损失函数
蒸馏的目标是让学生模型尽可能接近教师模型的性能。然而,传统的蒸馏目标可能过于依赖教师模型,导致学生模型无法完全超越教师模型。因此,可以尝试以下策略:
- 多阶段蒸馏:通过分阶段调整蒸馏目标,使学生模型逐步接近教师模型的性能。这种方法虽然可能使学生模型过于专注于特定任务,但可以通过引入额外的数据增强策略(如Stable Diffusion)来弥补。
- 结合知识蒸馏与校正工作:未来的研究方向之一是结合知识蒸馏和校正工作,以进一步提升学生模型的性能。
4. 利用参数化技巧
参数化技巧可以帮助学生模型更有效地学习教师模型的知识。例如:
- 参数映射:通过增加额外的参数来映射学生中间层到教师预测的隐藏层,从而提高学生模型的学习效率。
- 优化训练过程:通过调整参数化模型中的参数分布,可以减少采样所需的步骤数,从而提高训练效率。
5. 减少对特定教师模型的依赖
在某些情况下,选择合适的教师模型对于蒸馏效果至关重要。然而,过于依赖特定教师模型可能会限制学生模型的潜力。因此:
- 多样化教师模型:尝试使用不同的教师模型进行蒸馏,以找到最适合特定任务的学生模型。
- 动态调整教师模型:根据学生模型的性能动态调整教师模型的输出分布,从而提高蒸馏效果。
6. 结合其他技术
除了传统的蒸馏方法外,还可以结合其他技术来提升效率和效果:
- 数据增强:通过数据增强策略(如Stable Diffusion)扩展训练数据集,从而提高学生模型的鲁棒性和泛化能力。
- 轻量化技术:利用轻量化技术(如压缩和剪枝)进一步减少学生模型的复杂度,同时保持较高的性能。
总结
提升蒸馏过程中的效率和效果,减少对教师模型的依赖,需要综合考虑渐进式蒸馏、自我蒸馏、优化蒸馏目标、参数化技巧以及多样化教师模型等多种方法。
开发更高效的微调策略,降低标注数据需求并提升泛化能力的方法有哪些?
开发更高效的微调策略,降低标注数据需求并提升泛化能力的方法可以从以下几个方面进行探讨:
1. 利用高质量标注数据
- 微调需要高质量的标注数据,但标注成本较高。为了降低标注成本,可以采用实验设计框架来选择最具信息量的样本进行标注。例如,通过随机选择、基于不确定性的选择(如k-Center选择和Submodular选择)等方法,可以最大化标注样本的多样性和信息量,从而减少标注成本。
- 在标注样本稀缺的情况下,还可以通过自监督数据增强方法来扩展训练数据集。例如,使用一组微调后的模型对大量未标记文本进行标注,并利用这些标注信息预测原始测试集上的结果,从而提高模型的泛化能力。
2. 分层对比学习与蒸馏技术
- 在3D场景解析等复杂任务中,可以通过分层对比学习策略实现更准确的视觉语言对齐,并通过蒸馏技术将点-语言对齐的2D表示转化为3D点云网络,从而赋予模型更强的开放词汇识别能力。
- 此外,弱监督方法也可以在微调阶段发挥作用,例如利用区域边界的敏感性来指导模型学习更精确的特征表示。
3. 参数高效微调(Parameter-Efficient Fine-Tuning)
- 参数高效微调是一种减少模型参数调整数量的方法,仅更新少量参数以适应特定任务。这种方法不仅降低了计算资源的需求,还能有效提升模型在特定任务上的性能。
- 指令调整(Instruction Tuning)也是一种有效策略,通过调整模型输出以更好地适应未见过的任务。
4. 利用预训练数据
- 利用预训练数据进行微调可以显著提升模型的泛化能力。例如,基于不平衡最优传输(UOT)选择适当的子集进行微调,可以减少领域差距并提升模型性能。
- 预训练阶段的无监督学习依赖大量未标注数据,这有助于模型专注于学习语言规律而非记忆训练数据,从而增强泛化能力。
5. 减少过拟合
- 微调过程中,过拟合是一个常见问题。可以通过针对性调整(即使用与目标任务相关的小规模高质量标注数据)来减少过拟合风险,使模型更好地适应特定任务。
- 在微调阶段,还可以结合上下文学习方法,例如冻结预训练的特征映射层,并通过少量示例和查询任务进一步优化模型输出。
6. 实验设计与优化
- 实验设计框架在微调策略中也具有重要作用。例如,通过优化微调模型在特定任务上的表现,可以显著降低标注成本。具体方法包括随机选择、基于不确定性的选择、k-Center选择和Submodular选择。
- 在推荐系统中,使用微调泛化模型(TMM-S)结合网格搜索等策略,可以有效提升召回率和查询时间性能。
7. 结合多任务学习
- 多任务学习可以通过共享底层特征来提升模型的泛化能力。例如,在微调阶段结合多个相关任务的数据,可以进一步优化模型性能。
总结
开发更高效的微调策略需要综合考虑标注数据的质量与数量、模型的泛化能力以及计算资源的效率。通过实验设计框架、分层对比学习、参数高效微调、预训练数据利用以及减少过拟合等方法,可以在降低标注成本的同时提升模型的泛化能力。
结合蒸馏与微调技术,探索更全面的优化方案的研究方向有哪些?
结合蒸馏与微调技术,探索更全面的优化方案的研究方向可以从以下几个方面展开:
-
混合微调与压缩技术(Hybrid Fine-Tuning and Compression)
研究如何将微调与模型压缩技术(如知识蒸馏)深度融合,以实现模型性能和资源消耗之间的平衡。例如,通过在微调过程中动态调整模型大小,既能降低计算成本,又能保持模型性能。此外,还可以探索如何利用蒸馏技术将大模型的知识迁移到小模型中,从而提升小模型的泛化能力和推理效率。 -
自动化微调与蒸馏工具的开发
随着大模型的广泛应用,未来的研究可以集中在开发自动化微调和蒸馏工具上,降低技术门槛,使非专业人士也能高效地优化模型。例如,通过自动化平台实现参数共享、任务适配等功能,进一步简化模型优化流程。 -
多任务微调与蒸馏结合
在多任务学习场景中,研究如何通过蒸馏技术将多个任务的知识整合到一个较小的模型中,同时利用微调技术提升每个任务的性能。这种方法可以显著提高模型的泛化能力,并减少资源消耗。 -
高效参数化微调与蒸馏策略
针对不同任务需求,研究更加高效的微调与蒸馏策略。例如,通过Adapter Tuning、Prompt Tuning等方法,可以在不显著增加计算量的情况下,实现更灵活的模型优化。此外,还可以探索如何结合自监督学习和强化学习等先进技术,进一步提升微调与蒸馏的效果。 -
跨领域应用与创新性方法
将微调与蒸馏技术应用于更多领域,如自然语言处理、图像识别等。例如,在情感分析任务中,结合微调与知识蒸馏技术,可以生成轻量级但性能接近的模型。此外,还可以探索如何将这些技术应用于生成式多模态模型,以实现更高效的内容生成。 -
理论与实践结合的深入研究
深入研究蒸馏与微调技术的理论基础,探索其在不同场景下的适用性和局限性。例如,研究蒸馏对测试误差的影响以及如何优化蒸馏策略以适应连续动作空间。同时,通过实际案例验证这些技术的有效性,为未来的研究提供实践指导。 -
面向未来的大规模模型优化
随着大模型规模的不断扩大,研究如何在保持性能的同时进一步压缩模型大小,使其更适合在资源受限的环境中部署。例如,通过结合剪枝、量化和蒸馏技术,实现更高效的模型优化。
结合蒸馏与微调技术的研究方向不仅包括技术本身的优化和融合,还涉及自动化工具的开发、多任务学习的应用以及跨领域的创新实践。