03-2.python爬虫-Python爬虫基础(一)

HTTP 基本原理
HTTP(HyperText Transfer Protocol),即超文本传输协议,是互联网通信的关键所在。它作为应用层协议,构建于可靠的 TCP 协议之上,保障了数据传输的稳定与可靠,犹如网络世界的 “交通规则”,规范着客户端与服务器之间的数据往来。
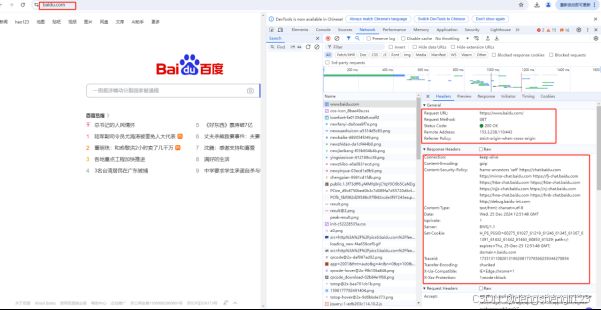
HTTP 的请求响应过程是其核心机制。当用户在浏览器中输入一个 URL 并按下回车键,浏览器就会作为客户端向服务器发送 HTTP 请求。请求由请求行、请求头和请求体组成。请求行包含请求方法(如 GET、POST 等)、URI(统一资源标识符,用于定位资源)和协议版本。请求头则传递着客户端的各种信息,如 Accept 告知服务器客户端能接收的文件类型,User-Agent 提供客户端的浏览器或应用程序信息等。请求体则在某些请求方法(如 POST)中携带需要提交给服务器的数据。服务器接收到请求后,会根据请求的内容进行相应的处理,并返回 HTTP 响应。响应包括状态行、响应头和响应体。状态行包含协议版本、状态码(如 200 表示成功,404 表示未找到资源等)和状态说明。响应头传递着服务器的信息以及对客户端的一些指示,如 Content-Type 告知客户端返回数据的类型。响应体则是服务器返回的实际数据,如 HTML 文档、图片、视频等资源,这些数据最终会在浏览器中呈现给用户,完成一次完整的网络数据交互过程。
理解 HTTP 的基本原理,对于学习爬虫技术至关重要。因为爬虫本质上就是模拟客户端向服务器发送请求,并解析服务器返回的响应数据,从而获取所需的信息。只有深入掌握 HTTP 的工作机制,才能更好地构建高效、稳定的爬虫程序,在浩瀚的网络数据海洋中精准地获取目标数据,为后续的数据分析和应用奠定坚实的基础。
Web 网页基础:爬虫的信息宝库
Web 网页是互联网信息的重要载体,也是爬虫获取数据的主要来源。了解网页的基本构成和相关技术,对于爬虫的学习至关重要。
网页的基本构成元素丰富多样,文字作为最主要的信息传递者,承载着网页的核心内容,无论是新闻资讯、学术文章还是产品描述,都离不开文字的呈现。图片则以直观的视觉效果增强网页的吸引力和表现力,使信息更加生动形象,例如电商网站上的商品图片、新闻网站中的配图等。视频元素能够为用户提供动态的视觉和听觉体验,如在线教育平台的课程视频、视频分享网站的各类视频内容等。音频元素在一些特定网页中也发挥着重要作用,比如音乐播放网站、有声读物网站等。此外,超链接是网页的灵魂之一,它将不同的网页连接在一起,形成了庞大的网络信息体系,用户通过点击超链接可以在不同页面之间跳转,获取更多相关信息。按钮用于实现各种交互功能,如提交表单、触发操作等。表单则为用户与网页之间的信息交互提供了途径,用户可以在表单中输入数据,实现登录、注册、搜索、评论等功能,例如电商网站的购买表单、社交媒体网站的注册表单等。
网页的类型主要分为静态网页和动态网页。静态网页的内容在服务器端预先设定好,用户请求时,服务器直接将其发送给客户端浏览器,页面内容不会随用户操作或时间变化而改变,其优点是加载速度快、结构简单、易于编写和维护,适用于内容相对固定的页面,如公司的宣传页面、个人简历页面等。动态网页则是在服务器端根据用户的请求动态生成的,页面内容可以根据用户的输入、操作或数据库中的数据进行实时更新和变化,常见的技术包括 PHP、ASP.NET、Python 的 Django 和 Flask 等,它能够提供更加丰富的交互体验,如电子商务网站的商品展示和购物车功能、社交媒体网站的动态更新等,但由于需要服务器进行动态处理,可能会导致加载速度相对较慢,并且对服务器资源的要求较高。
网页开发的基础技术主要包括 HTML、CSS 和 JavaScript。HTML(HyperText Markup Language)即超文本标记语言,它通过各种标签来定义网页的结构和内容,如标签表示整个网页,
标签包含网页的元信息,标签则容纳网页的主体内容,标签用于定义段落,标签用于插入图片等,是网页的基础架构,如同房屋的框架,决定了网页的基本布局和元素的组织方式。CSS(Cascading Style Sheets)即层叠样式表,用于控制网页的样式和布局,通过选择器来指定网页元素的样式属性,如字体、颜色、大小、间距、背景等,能够使网页更加美观和易于阅读,就像为房屋进行装修,赋予其独特的外观和风格。JavaScript 是一种脚本语言,为网页添加动态交互功能,例如实现页面元素的动态显示与隐藏、表单验证、数据请求与处理、动画效果等,让网页从静态变为动态,增强用户体验,如同为房屋配备了智能设备,使其更加智能和便捷。
对于爬虫而言,熟悉网页的这些基础构成和技术,有助于更好地理解如何从网页中提取有价值的信息。通过分析 HTML 结构,爬虫可以精准定位到所需的数据所在的标签位置,从而准确地抓取数据;了解 CSS 样式可以帮助爬虫识别和处理一些与样式相关的信息,例如通过样式类名或 ID 来定位特定元素;而 JavaScript 的存在则可能影响爬虫获取数据的方式,有些网页可能通过 JavaScript 动态加载数据,这就需要爬虫具备执行 JavaScript 代码或模拟 JavaScript 行为的能力,以确保能够完整地获取到网页中的所有数据,为后续的数据处理和分析提供坚实的基础,从而更好地实现从网页中挖掘有价值信息的目标,满足各种数据分析和应用的需求。
爬虫的基本原理
爬虫的定义
网络爬虫(Web Crawler)又称网页蜘蛛、网络机器人、网页追逐者,是一种按照一定的规则,自动地抓取互联网信息的程序或者脚本。它们被广泛用于互联网搜索引擎或其他类似网站,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容。只要是浏览器能做的事情,原则上,爬虫都能够做。
爬虫的工作流程
- 确定目标:
明确需要爬取的数据来自哪些网站或者什么样的网页,以及具体是何种类型的数据。比如要爬取电商网站上某类商品的价格、评论信息,或者是新闻网站中特定主题的新闻内容等,还可以设定抓取的深度限制,例如是否仅抓取特定层级的链接,还是全网爬取等。
- 发送请求:
使用 HTTP 客户端库(如 Python 的 Requests 库)向目标 URL 发送 GET 或 POST 等请求。根据需要配置请求头,模拟浏览器行为,包括 User-Agent、Cookies、Referer 等,以此降低被目标网站识别为爬虫的风险,有时候可能还需要使用代理 IP 或其他手段来绕过访问限制。
- 获取响应:
接收服务器返回的 HTTP 响应,获取网页内容。响应包含状态行(其中有协议版本、状态码以及状态说明,像 200 表示成功,404 表示未找到资源等)、响应头(传递着服务器的信息以及对客户端的一些指示,如 Content-Type 告知客户端返回数据的类型)和响应体(服务器返回的实际数据,如 HTML 文档、图片、视频等资源)。
- 解析数据:
使用 HTML 或 XML 解析器(如 BeautifulSoup、lxml、PyQuery 或基于 DOM 的解析方式)解析网页结构,对于非 HTML 内容,可能需要相应的内容解析方法,如 JSON、XML 等。然后根据预先设定好的规则,从网页内容中提取有用数据,例如文本、图片、链接或者其他特定元素,可能会用到 CSS 选择器、XPath 或其他模式匹配技术。
- 存储数据:
将爬取的数据储存到本地文件、数据库(如关系型数据库 mysql、oracle、sql server 等,非关系型数据库 MongoDB、Redis 等)或者云端存储服务。并且数据可能需要清洗、转换或结构化以便后续分析和使用。
会话和 Cookies
在深入探索网络爬虫的过程中,会话(Session)和 Cookies 是两个至关重要的概念,它们在处理需要用户登录、状态保持或个性化内容的网站时发挥着关键作用,能够帮助爬虫更好地模拟人类浏览器的行为,从而更有效地访问和收集网站数据。
HTTP 协议是一种无状态协议,这意味着服务器在处理客户端的请求时,不会记录之前的请求信息,每个请求都是独立的。然而,在许多实际的网络应用场景中,我们需要在多个请求之间保持某种状态信息,例如用户登录后的身份信息、购物车中的商品信息等。会话和 Cookies 就是为了解决这个问题而出现的。
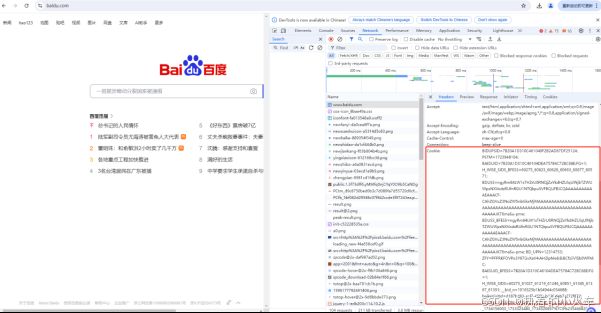
Cookies 是服务器发送到用户浏览器并保存在本地的一小块数据,它会在浏览器下次向同一服务器再发起请求时被携带并发送到服务器上。Cookies 主要用于识别用户身份、记录用户访问次数、存储用户偏好设置等。其工作原理如下:
- 创建 Cookies:服务器通过 HTTP 响应头中的 Set-Cookie 字段向客户端发送 Cookies。例如,当用户登录一个网站时,服务器可能会发送一个包含用户 ID 或登录令牌的 Cookie 给客户端浏览器。
- 发送 Cookies:浏览器在后续的 HTTP 请求中,通过请求头中的 Cookie 字段将 Cookies 发送给服务器。这样,服务器就能识别出是哪个用户在发送请求,并根据之前保存的状态信息做出相应的响应。
- 读取 Cookies:服务器解析请求头中的 Cookie 字段,读取 Cookies 数据,从而获取用户的相关信息,如登录状态、用户偏好等。
Cookies 可以分为会话 Cookie 和持久化 Cookie。会话 Cookie 在浏览器关闭后就会失效,它通常用于在一次会话期间保持用户的状态信息;而持久化 Cookie 则会在浏览器关闭后仍然保存在本地硬盘上,直到达到设定的过期时间为止,它可以用于长期保存用户的登录状态或其他重要信息,以便用户下次访问时无需重新登录。
Session 是一种服务器端的会话管理机制,它允许服务器为每个用户会话维护一个独立的存储空间。当用户访问服务器时,服务器会为该用户创建一个唯一的 Session ID,并通过 Cookies 或 URL 重写的方式将 Session ID 发送给客户端。客户端在后续的请求中携带 Session ID,服务器根据 Session ID 检索对应的会话信息,从而实现跨页面或跨请求的状态保持。例如,在一个电子商务网站中,用户将商品添加到购物车后,服务器会将购物车中的商品信息存储在与该用户对应的 Session 中,当用户在不同页面浏览商品或进行结算时,服务器可以通过 Session ID 获取购物车中的商品信息,确保购物流程的连续性。
在爬虫的应用场景中,会话和 Cookies 的作用也不容忽视。当爬虫需要模拟登录或保持登录状态时,就需要正确处理 Cookies 和 Session。例如,在爬取一些需要用户登录才能访问的数据时,爬虫首先需要发送登录请求,获取服务器返回的包含登录凭证(如 Session ID 或登录令牌)的 Cookies,然后在后续的请求中携带这些 Cookies,以维持登录状态,从而能够顺利地爬取到登录后才能看到的数据。此外,对于一些通过 Session 来检测和阻止爬虫访问的网站,爬虫需要更加智能地处理 Session,比如通过模拟真实的用户行为、使用代理 IP、调整请求频率等方式来绕过这些反爬虫机制,确保数据的持续抓取。
需要注意的是,在使用爬虫时,我们必须遵守相关的法律法规和网站的使用条款,尊重网站的规则和隐私政策,合理控制爬虫的请求频率,避免对网站服务器造成过大的压力或触发反爬虫机制,确保爬取活动的合法性和合规性。同时,我们也要注意保护用户的隐私和数据安全,避免因不当使用爬虫而导致的信息泄露等问题。