【无监督特征选择方法综述】
无监督特征选择方法综述
- 前言
- 一、Filter方法
-
- 1.单变量
-
- Information based methods基于信息理论
- Spectral-similarity based methods基于光谱相似性的方法
- 2、多变量 Multivariate filter methods
-
- Statistical/information based methods
- Bio-inspired methods
- Spectral/sparse learning methods
- 二、Wrapper approach
-
- 1.Sequential methods
- 2.Bio-inspired methods
- 3.Iterative
- 三、Hybrids approach
- 参考文献
前言
无监督特征选择(UFS)方法可以根据用于选择特征的策略进行分类,如过滤器、包装器和混合方法。
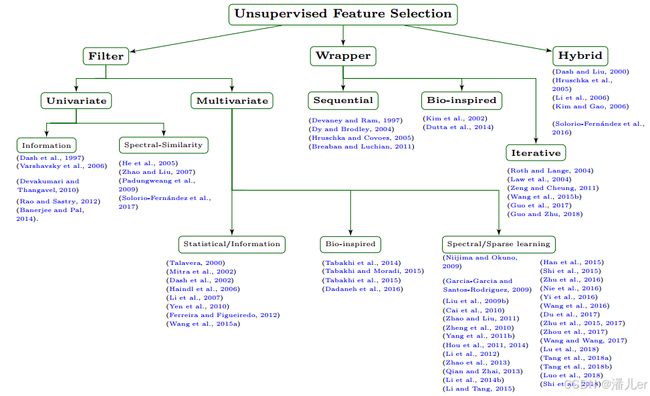
一、Filter方法
只根据数据内在属性评估特征,不使用聚类算法等辅助特征搜索的方法。
速度快、可扩展性强
分为单变量和多变量
1.单变量
Information based methods基于信息理论
遵循通过熵、散度、互信息等度量来评估数据的分散程度,以识别数据中的聚类结构
1.SUD (Sequential backward selection method for Unsupervised Data)
- 基于距离相似性的熵值作为度量,进行相关性排序,选择特征
2.SVD-Entropy
- 通过原始数据矩阵的奇异值来测量熵值,评估每个特征对熵值的共线,并通过各自的熵值对特征排序
- 有三种选择特征子集的方法:简单排序、正向选择和反向消除
3.information theory based,基于信息论的方法
- 使用表示熵对特征进行加权,对熵值进行相关性排序,选择特征
- 表示熵是数据集中信息压缩的度量,它是根据数据协方差矩阵的特征值熵计算的。表示熵的范围为0到1,其中1表示最大压缩,0表示最小压缩。
Spectral-similarity based methods基于光谱相似性的方法
基于谱特征选择的最具参考价值和相关性的单变量滤波器UFS方法之一是拉普拉斯评分。
在拉普拉斯评分中,特征的重要性是通过其方差和局部保持能力来评估的。
1.SPEC (SPECtrum decomposition)
2.USFSM (Unsupervised Spectral Feature Selection Method for mixed data)
2、多变量 Multivariate filter methods
可分为三大类
1.统计/信息:包括使用统计和/或信息理论度量(如方差协方差、线性相关、熵、互信息等)进行选择的UFS方法。
2.生物启发Bio-inspired:使用基于群体智能范式的随机搜索策略来寻找满足某些质量标准的良好特征子集。
3.基于光谱/稀疏学习:包括基于谱分析或基于谱分析和稀疏学习的组合,这些方法常被称为嵌入式方法,因为特征选择是作为一部分实现的
Statistical/information based methods
1.FSFS (Feature Selection using Feature Similarity)
- 将原始特征集划分为簇,使同一簇中的特征高度相似,而不同簇中的则不同。
- 基于kNN原理,计算每个特征的k个最近特征,选择具有k个最近特征的最紧凑子集的特征,并丢弃其k个最近的特征。
2.RRFS (Relevance Redundancy Feature Selection)
- 分两步选择特征,首先,根据相关性度量对特征进行排序。然后,在第二步中,按照前一步中生成的顺序,使用特征相似性度量来评估特征,以量化它们之间的冗余。然后,选择冗余度最低的前p个特征
3.MPMR (feature selection based on Maximum Projection and Minimum Redundancy)
- 引入了一种称为最大投影和最小冗余特征选择的新标准。其想法是选择一个特征子集,以便将所有原始特征投影到具有最小重建误差的特征子空间中。
Bio-inspired methods
1.UFSACO (Unsupervised Feature Selection based on Ant Colony Optimization)
- 基于蚁群优化的无监督特征选择,主要目标是选择特征之间相似度低(冗余度低)的特征子集。
- 在这项工作中,搜索空间被表示为一个完整的无向图;其中节点表示特征,边的权重表示特征之间的相似性。
- 这种相似性是使用余弦相似性函数计算的。作者认为,如果两个特征相似,那么这些特征就是多余的。
- 优先选择高信息素值和低相似性,直到达到预先指定的停止标准(迭代次数)。最后,选择信息素值最高的特征。
2.MGSACO (Microarray Gene Selection based on Ant Colony Optimization)基于蚁群优化的微阵列基因选择
3.RR-FSACO (Relevance-Redundancy Feature Selection based on ACO)根据蚁群优化的相关性冗余特征选择
4.UPFS (Unsupervised Probabilistic Feature Selection using ant colony optimization)使用蚁群优化的无监督概率特征选择
Spectral/sparse learning methods
1.mR-SP (minimum-Redundancy SPectral feature selection)
- 结合了SPEC排名和最小冗余最优性准则
- 基本思想是通过引入一个评估度量来量化每对特征的相似性,通过修改余弦相似性函数,增加一种控制SPEC中特征冗余的方法。
2.LLDA-RFE (Laplacian Linear Discriminant Analysis-based Recursive Feature Elimination)
- 该方法利用对象之间的相似性将线性判别分析(LDA)扩展到无监督的情况
- 递归地删除LLDA判别向量绝对值最小的特征,以识别可能揭示样本中聚类的特征。
3.MCFS (Multi-Cluster Feature Selection)
4.MRSF (Minimize the feature Redundancy for Spectral Feature selection)
5.UDFS (Unsupervised Discriminative Feature Selection algorithm)
- 同时利用散布矩阵和特征相关性中包含的判别信息来执行特征选择
6.JELSR (Joint Embedding Learning and Sparse Regression)
7.USFS(Unsupervised Spectral Feature Selection with l1-norm graph)
- 思想是使用光谱聚类和l1范数图来选择判别特征。
8.NDFS (Nonnegative Discriminative Feature Selection)
- NDFS与UDFS和MRFS一样,在统一的框架中利用判别信息和特征相关性进行特征选择。
9.FSLR (Feature subset with Sparsity and Low Redundancy)
- FSLR采用谱分析在较低维度上表示数据,并在具有非负约束的目标函数中引入了一个新的正则化项。
10.CDL-FS (Couple Dictionary Learning Feature Selection)
- 使用耦合分析/合成字典而不是谱分析来学习伪类标签。
11.SOGFS (Structured Optimal Graph Feature Selection)
- 同时执行特征选择和局部结构学习。
12.CGSSL (ClusteringGuided Sparse Structural Learning)
- 这项工作提出了一种通用的特征选择方法,该方法结合了非负谱分析和具有稀疏性的结构学习。
- 线性模型中使用聚类指标(通过非负谱聚类学习)为结构学习提供标签信息。
13.RUFS (Robust Unsupervised Feature Selection)
- 目标是实现鲁棒聚类和鲁棒特征选择。
- RUFS通过局部学习正则化鲁棒非负矩阵分解来学习伪聚类标签
14.SPNFSR (StructurePreserving Non-negative Feature Self-Representation)
15.DSRMR (Dual Self-Representation and Manifold Regularization)
二、Wrapper approach
使用特定聚类算法的结果来评估特征子集。在这种方法下开发的方法的特点是找到有助于提高用于选择的聚类算法结果质量的特征子集。具有较高的计算成本,并且它们仅限于与特定的聚类算法结合使用。
根据特征搜索策略分为三大类:sequential, bio-inspired, and iterative
sequential:按顺序添加或删除的。基于顺序搜索的方法易于实现且快速
inspired:将随机性纳入搜索过程,旨在摆脱局部最优。
iterative:通过将无监督特征选择问题转化为估计问题来解决,从而避免了组合搜索。
1.Sequential methods
1.SS-SFS (Simplified Silhouette Sequential Forward Selection)
- 根据简化的轮廓标准选择提供最佳质量的特征子集。
- 使用正向选择搜索来生成特征子集。每个特征子集都使用k-means聚类算法对数据进行聚类,并通过用简化轮廓标准测量的聚类质量来评估特征子集的质量。选择在正向选择中产生此标准最佳值的特征子集。
2.Bio-inspired methods
1.ELSA(evolutionary local selection algorithm )
- 基于k-means和高斯混合聚类算法搜索特征子集和聚类数量。
2.MOGA(multi-objective genetic algorithm)
3.Iterative
1.LLC-fs (Local Learningbased Clustering algorithm with feature selection)
2.EUFS (Embedded Unsupervised Feature Selection)
- 通过稀疏学习将特征选择直接嵌入到聚类算法中。
3.DGUFS (Dependence Guided Unsupervised Feature Selection)
- 使用基于迭代交替方向乘子法的改进算法进行优化
三、Hybrids approach
利用过滤器和包装器这两种方法的特性,试图在效率(计算工作量)和有效性(使用所选特征时相关目标任务的质量)之间取得良好的折中。
1.BFK( a hybrid UFS method non-based on ranking)
- 这种方法从包装器阶段开始,在用户指定的一系列聚类的数据集上运行kmeans聚类算法。使用简化的轮廓标准对聚类进行评估,并选择值最高的聚类。在过滤阶段,使用马尔可夫的概念,通过贝叶斯网络选择特征子集,其中每个簇表示一个类,节点表示特征,边表示特征之间的关系。
参考文献
A review of unsupervised feature selection methods