OLA音频变速算法的仿真与剖析
前段时间,在尝试音乐节拍数的提取时,终于有了突破性的进展,效果基本上比市面上的许多商业软件还要好,在作节拍数检测时,高频信息作用不大,
通过重采样减小运算量。重采样让我想起了在学校里面做的变速变调算法,在这里顺便回顾一下。
OLA(Overlap-and-Add, OLA)重叠叠加算法是音频变速算法中最简单的时域方法,它是后续时域算法(SOLA, SOLA-FS, TD-PSOLA, WSOLA)的基础。
OLA分为分解与合成两个部分,公式看起来很复杂,所以不贴出了,基本思路从图中更能清晰的表现出来。
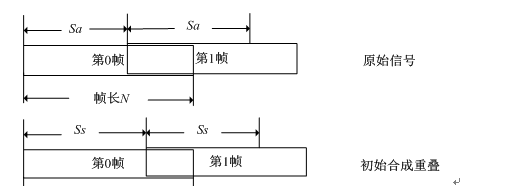
分解阶段:语音首先分帧,帧长为N,假设帧移为Sa。
合成阶段:分解出来的语音帧,以帧移为Ss的间隔重新合成起来,得到变速之后的音频。
Rate = Ss/ Sa,如果Sa=Ss,则原速;Ss<Sa时,加速;Ss>Sa时,减速。
功能性代码:
function [ RSound ] = OLA(Speech, Fs, Rate)
%OLA Summary of this function goes here
% Detailed explanation goes here
frame_ms = 25;
frame_len = frame_ms * Fs /1000;
window = hanning(frame_len);
Sa = 1/2 * frame_len;
AnalysisSplice = enframe(Speech, window, Sa);
AnalysisSplice = AnalysisSplice';%each column corresponding to each frame data
Ss = Rate*Sa;
RSound = Synthesis(AnalysisSplice, Ss);
end
function RSound = Synthesis(AnalysisSplice, Ss)
[frame_len, nframes] = size(AnalysisSplice);
N = Ss*(nframes - 1) + frame_len;
RSound = zeros(1, N);
for q = 1:nframes
RSound(1 + (q-1)* Ss : frame_len + (q-1)*Ss) = RSound(1 + (q-1)* Ss : frame_len + (q-1)*Ss) + AnalysisSplice(:,q)';
end
end
Script执行代码:
clc;
clear;
close all;
Path = 'D:\Experiment\OLA\';
file = [Path, 'test.wav'];
faster = [Path, 'faster.wav'];
[Speech, Fs] = wavread(file);
Rate = 0.7;
%wavread wavwrite enframe function comes from voicebox tools
RSound = OLA(Speech,Fs,Rate);
wavwrite(RSound,Fs,faster);
figure;
subplot(2,1,1);
plot(Speech);
title('original');
axis([1 length(Speech) -0.5 0.5]);
subplot(2,1,2);
plot(RSound);
title('0.7 faster');
axis([1 length(Speech) -0.5 0.5]);
变速前后的时域波形对比图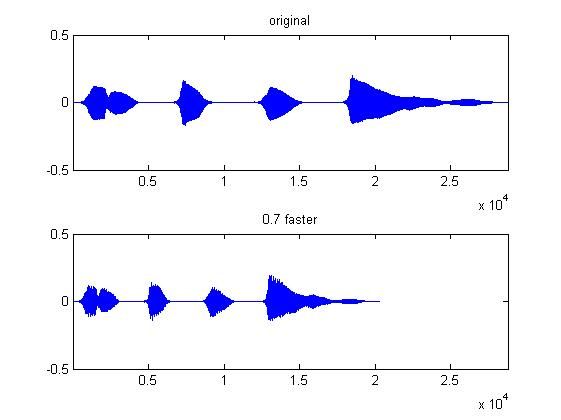
OLA算法在重叠部分会造成基频断裂,甚至语音失真。所以后期许多算法基于此缺点进行了相关的改进。
测试文件:
http://pan.baidu.com/s/1hq4540G
来自:http://www.cnblogs.com/welen
http://blog.csdn.net/weiqiwu1986