【python】并发编程——多线程
文章目录
- 1 一些概念
-
- 1.1 线程概念
- 1.2 线程模型
-
- 1.2.1 多对一
- 1.2.2 一对一
- 1.2.3 多对多
- 1.2.4 双层模型
- 2 Thread in Python
-
- 2.1 threading
-
- 2.1.1 示例
- 2.1.2 关于线程返回值
-
- 设置保存运行结果的全局变量
- 重写Thread类
- 2.2 concurrent.future线程池
-
- 2.2.1 例程
- 2.2.2 死锁的情况
-
- 相互等待
- worker不够用
- 3 参考
1 一些概念
1.1 线程概念
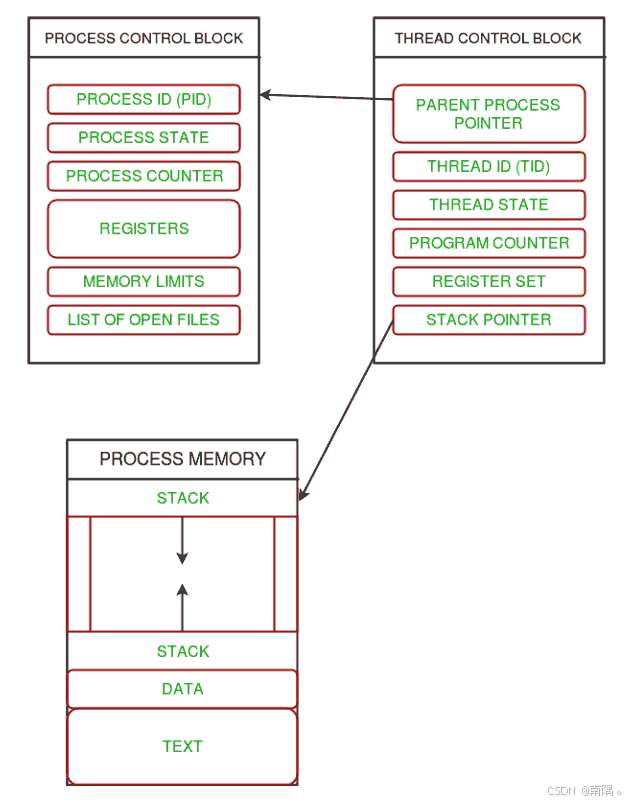
线程是程序的执行单元,CPU执行的是线程。它包含线程ID,程序计数器,寄存器组,堆栈,线程和同一进程内的其他线程共享代码段,数据段和其他操作系统资源(打开文件,信号)。
TCB包含的内容:线程ID(Thread Identifier),栈指针(Stack pointer),程序计数器(Program counter),线程状态(Thread State:running,ready,waiting,starting,done),线程寄存器(Thread’s register set),父进程指针(Parent process pointer,指向PCB)
1.2 线程模型
线程类型有内核线程和用户线程,内核线程和用户线程的对应关系构成线程模型。
1.2.1 多对一
多个用户线程对应一个内核线程,用户空间的线程库完成线程管理。一个线程执行阻塞的系统调用则整个进程阻塞。同一时间只能有一个线程访问内核,则多线程无法并行运行在多核系统上。Solaris
1.2.2 一对一
一个用户线程对应一个内核线程。可以并发执行在多核处理器上。创建一个用户线程就要创建一个内核线程,开销大。Linux,Windows
1.2.3 多对多
多个用户线程映射到相同数量或者更少的内核线程上。如果一个用户线程执行阻塞系统调用则内核可以切换另一个内核线程运行。同时,多个内核线程也可以发挥多核处理器优势。
1.2.4 双层模型
多对多加上一对一。Solaris第九版以前。
2 Thread in Python
标准CPython实现使用GIL,GIL限制一次只能执行一个Python线程,所以Python多线程是并发视角下的,多个线程交替执行,而非每时每刻运行。如果要并行执行任务,采用multiprocessing,使用其他支持并行的非标准Python实现,使用其他支持并行的编程语言。可以使用多线程执行I/O密集型任务,但不建议执行CPU密集型任务。
2.1 threading
2.1.1 示例
from threading import Thread
def thread_func(x):
return x * x
if __name__ == '__main__':
threads = list()
for ind in range(3):
t = Thread(target=thread_func, args=(ind,))
threads.append(t)
t.start()
for ind, thread in enumerate(threads):
thread.join() # 阻塞直到对应的线程执行完毕
print(thread)
2.1.2 关于线程返回值
设置保存运行结果的全局变量
from threading import Thread
def foo(bar, results, index):
print('hello {0}: {1}'.format(bar, index))
results[index] = index
THREAD_NUM = 10
threads = [None] * THREAD_NUM
results = [None] * THREAD_NUM
if __name__ == '__main__':
for i in range(THREAD_NUM):
threads[i] = Thread(target=foo, args=('world!', results, i))
threads[i].start()
for i in range(THREAD_NUM):
threads[i].join()
print(results)
重写Thread类
重写Thread类,新增私有成员变量self._result保存target执行完毕返回的结果,然后重写join(),使之返回私有成员变量self._result
from threading import Thread
class ThreadWithReturnValue(Thread):
def __init__(self, group=None, target=None, name=None,
args=(), kwargs={}, Verbose=None):
Thread.__init__(self, group, target, name, args, kwargs)
self._return = None
def run(self):
if self._target is not None:
self._return = self._target(*self._args,
**self._kwargs)
def join(self, *args):
Thread.join(self, *args)
return self._return
def func(x):
return x * x
if __name__ == '__main__':
threads = list()
for i in range(3):
t = ThreadWithReturnValue(target=func, args=(i,))
threads.append(t)
t.start()
for thread in threads:
print(thread.join())
2.2 concurrent.future线程池
2.2.1 例程
import concurrent.futures
import urllib.request
URLS = ['http://www.foxnews.com/',
'http://www.cnn.com/',
'http://europe.wsj.com/',
'http://www.bbc.co.uk/',
'http://nonexistent-subdomain.python.org/']
# Retrieve a single page and report the URL and contents
def load_url(url, timeout):
with urllib.request.urlopen(url, timeout=timeout) as conn:
return conn.read()
# We can use a with statement to ensure threads are cleaned up promptly
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# Start the load operations and mark each future with its URL
future_to_url = {executor.submit(load_url, url, 60): url for url in URLS}
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r page is %d bytes' % (url, len(data)))
说明:concurrent.futures.as_completed(fs, timeout=None)将返回一个关于Future对象的迭代器,哪个future最先完成,就先迭代它。如果fs中有重复的future,则只当其完成后只迭代它一次。如果在as_completed()调用结束前,某个future对象已经完成,则该future将排在首位被迭代。
2.2.2 死锁的情况
相互等待
import time
def wait_on_b():
time.sleep(5)
print(b.result()) # b will never complete because it is waiting on a.
return 5
def wait_on_a():
time.sleep(5)
print(a.result()) # a will never complete because it is waiting on b.
return 6
executor = ThreadPoolExecutor(max_workers=2)
a = executor.submit(wait_on_b)
b = executor.submit(wait_on_a)
worker不够用
def wait_on_future():
f = executor.submit(pow, 5, 2)
# This will never complete because there is only one worker thread and
# it is executing this function.
print(f.result())
executor = ThreadPoolExecutor(max_workers=1)
executor.submit(wait_on_future)
3 参考
https://realpython.com/intro-to-python-threading/
https://www.geeksforgeeks.org/multithreading-python-set-1/
https://www.geeksforgeeks.org/python-program-with-concurrency/