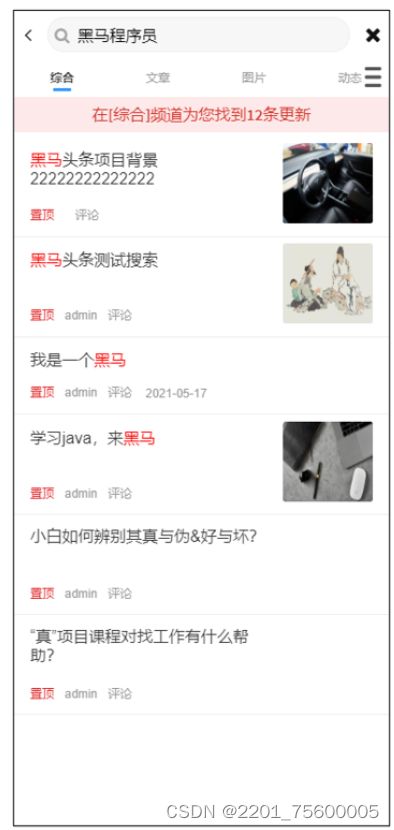
微服务es搜索关键词,实现关键词高亮,来自黑马头条的总结
为了加快搜索效率从es数据库中查询
实现的效果,要求从标题和内容中搜索关键词,然后让关键词高亮
步骤
-
ElasticSearch环境搭建
-
索引库创建
-
文章搜索多条件复合查询
-
索引数据同步
ElasticSearch环境搭建
这些都是死步骤,直接cv
ik分词器下载地址: https://github.com/medcl/elasticsearch-analysis-ik
下载完后,解压安装包到 ElasticSearch 所在文件夹中的plugins目录中
注意:IK分词器插件的版本要和ElasticSearch的版本一致
拉取镜像
docker pull elasticsearch:7.4.0创建容器
docker run -id --name elasticsearch -d --restart=always -p 9200:9200 -p 9300:9300 -v /usr/share/elasticsearch/plugins:/usr/share/elasticsearch/plugins -e "discovery.type=single-node" elasticsearch:7.4.0使用ik分词器
#切换目录
cd /usr/share/elasticsearch/plugins
#新建目录
mkdir analysis-ik
cd analysis-ik
#root根目录中拷贝文件
mv elasticsearch-analysis-ik-7.4.0.zip /usr/share/elasticsearch/plugins/analysis-ik
#解压文件
cd /usr/share/elasticsearch/plugins/analysis-ik
unzip elasticsearch-analysis-ik-7.4.0.zip
测试是否正确配置
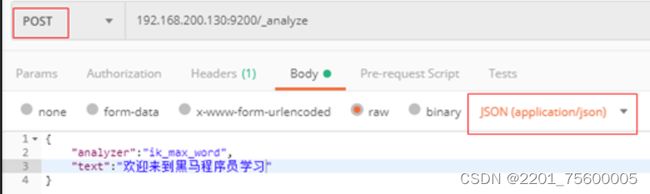
环境搭建完成
索引库创建
使用postman添加映射,使用put请求
put请求 : http://192.168.200.130:9200/app_info_article
// 没写"index": false的就是默认参与索引,然后对title和content使用ik_smart分词器
{
"mappings":{
"properties":{
"id":{
"type":"long"
},
"publishTime":{
"type":"date"
},
"layout":{
"type":"integer"
},
"images":{
"type":"keyword",
"index": false
},
"staticUrl":{
"type":"keyword",
"index": false
},
"authorId": {
"type": "long"
},
"authorName": {
"type": "text"
},
"title":{
"type":"text",
"analyzer":"ik_smart"
},
"content":{
"type":"text",
"analyzer":"ik_smart"
}
}
}
}GET请求查询映射:http://192.168.200.130:9200/app_info_article
DELETE请求,删除索引及映射:http://192.168.200.130:9200/app_info_article
GET请求,查询所有文档:http://192.168.200.130:9200/app_info_article/_search
添加数据
这一步主要是为了把数据库中符合要求的数据批量导入到es中,后续就是从es中查询数据
@SpringBootTest
@RunWith(SpringRunner.class)
public class ApArticleTest {
@Autowired
private ApArticleMapper apArticleMapper;
@Autowired
private RestHighLevelClient restHighLevelClient;
/**
* 注意:数据量的导入,如果数据量过大,需要分页导入
* @throws Exception
*/
@Test
public void init() throws Exception {
//1.查询所有符合条件的文章数据
List searchArticleVos = apArticleMapper.loadArticleList();
//2.批量导入到es索引库
BulkRequest bulkRequest = new BulkRequest("app_info_article");
for (SearchArticleVo searchArticleVo : searchArticleVos) {
IndexRequest indexRequest = new IndexRequest().id(searchArticleVo.getId().toString())
.source(JSON.toJSONString(searchArticleVo), XContentType.JSON);
//批量添加数据
bulkRequest.add(indexRequest);
}
restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
}
} 测试一下导入是否成功
postman查询所有的es中数据 GET请求: http://192.168.200.130:9200/app_info_article/_search
文章搜索多条件复合查询
搭建搜索微服务
导入依赖
org.elasticsearch.client
elasticsearch-rest-high-level-client
7.4.0
org.elasticsearch.client
elasticsearch-rest-client
7.4.0
org.elasticsearch
elasticsearch
7.4.0
nacos配置中心leadnews-search
指定es的地址,nacos的地址
spring:
autoconfigure: # 这个是搜索连接数据库暂时不用
exclude: org.springframework.boot.autoconfigure.jdbc.DataSourceAutoConfiguration
elasticsearch:
host: 192.168.200.130
port: 9200
定义搜索接口等
@RestController
@RequestMapping("/api/v1/article/search")
public class ArticleSearchController {
@PostMapping("/search")
public ResponseResult search(@RequestBody UserSearchDto dto) throws IOException {
return null;
}
}关键代码
@Service
@Slf4j
public class ArticleSearchServiceImpl implements ArticleSearchService {
@Autowired
private RestHighLevelClient restHighLevelClient;
/**
* es文章分页检索
*
* @param dto
* @return
*/
@Override
public ResponseResult search(UserSearchDto dto) throws IOException {
//1.检查参数
if(dto == null || StringUtils.isBlank(dto.getSearchWords())){
return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);
}
//2.设置查询条件
SearchRequest searchRequest = new SearchRequest("app_info_article");// 这只是一个请求对象
// searchRequest.source() 里面放条件,source里面是SearchSourceBuilder
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//布尔查询
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 必须根据关键词查询,所有boolQueryBuilder的must,然后使用filter过滤
//关键字的分词之后查询
QueryStringQueryBuilder queryStringQueryBuilder = QueryBuilders.queryStringQuery(dto.getSearchWords()).field("title").field("content").defaultOperator(Operator.OR);
boolQueryBuilder.must(queryStringQueryBuilder);
//查询小于mindate的数据
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("publishTime").lt(dto.getMinBehotTime().getTime());
boolQueryBuilder.filter(rangeQueryBuilder);
//分页查询 因为我们是滚屏查询,
searchSourceBuilder.from(0);
searchSourceBuilder.size(dto.getPageSize());
//按照发布时间倒序查询
searchSourceBuilder.sort("publishTime", SortOrder.DESC);
//设置高亮 title
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.preTags("");
highlightBuilder.postTags("");
searchSourceBuilder.highlighter(highlightBuilder);
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//3.结果封装返回
List总结:
1.SearchRequest searchRequest = new SearchRequest("app_info_article");
2.searchRequest.source() 里面放条件,source里面是SearchSourceBuilder,所以先把SearchSourceBuilder创建出来
3.BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery(); 布尔查询是用must、must_not、filter等方式组合其它查询
4.QueryStringQueryBuilder queryStringQueryBuilder = QueryBuilders.queryStringQuery(dto.getSearchWords()).field("title").field("content").defaultOperator(Operator.OR);
5.处理高亮部分为固定代码,高亮和普通是分开的
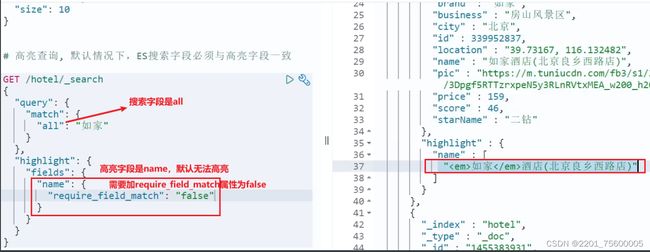
高亮:
GET /hotel/_search
{
"query": {
"match": {
"FIELD": "TEXT" // 查询条件,高亮一定要使用全文检索查询
}
},
"highlight": {
"fields": { // 指定要高亮的字段
"FIELD": {
"pre_tags": "", // 用来标记高亮字段的前置标签
"post_tags": "" // 用来标记高亮字段的后置标签
}
}
}
}注意:
-
高亮是对关键字高亮,因此搜索条件必须带有关键字,而不能是范围这样的查询。
-
默认情况下,高亮的字段,必须与搜索指定的字段一致,否则无法高亮
-
如果要对非搜索字段高亮,则需要添加一个属性:required_field_match=false

最后在APP网关中添加路由
#搜索微服务
- id: leadnews-search
uri: lb://leadnews-search
predicates:
- Path=/search/**
filters:
- StripPrefix= 1