ASR技术与Whisper引擎
一、ASR技术简介
ASR英文全称是Automatic Speech Recognition,中文叫做自动语音识别,是利用机器对语音信号进行识别和理解并将其转换成相文本和命令的技术。
下面2张图是网上找到的语音识别结构图和流程图。
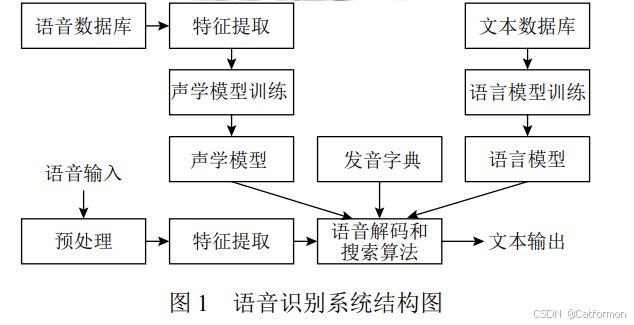

以下为ASR技术的核心技术。
特征提取:通过编码将声音转变为数字信号,提取有效的声学特征。梅尔频率倒谱系数MFCC是最经典的语音特征。
声学模型:声学模型通过处理编码得到的向量,将相邻的帧组合起来变成音素,再组合起来变成单个的单词或汉字。 GMM-HMM 是最为常见的一种声学模型。
语言模型:语言模型则用来调整声学模型所得到的不合逻辑的字词,使识别结果变得正确通顺。
二、Whisper技术
Whisper 自动语音识别系统是OpenAI公司开源的系统,聊天机器人ChatGPT也是OpenAI公司发布的!
Whisper 是一个自动语音识别(ASR,Automatic Speech Recognition)系统,OpenAI 通过从网络上收集了 68 万小时的多语言(98 种语言)和多任务(multitask)监督数据对 Whisper 进行了训练。
开源地址:https://github.com/openai/whisper
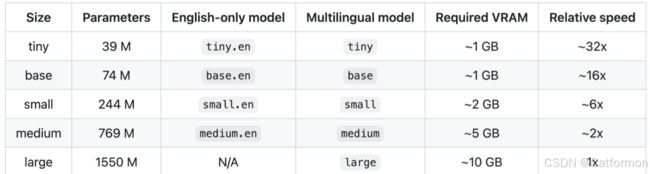
whisper有五种模型尺寸,提供速度和准确性的平衡,下面是可用模型的名称、大致内存需求和相对速度。
三、Whisper技术实现
1、安装whisper
pip3 install -U openai-whisper
需要重新安装torch,否则会报错ModuleNotFoundError: No module named ‘torch’
pip3 uninstall torch
pip3 install torch==2.2.2 torchvision
pip3 install setuptools-rust
2、安装ffmpeg
下载并解压“ffmpeg-6.0-essentials_build.zip”
将安装位置配置到环境变量
3、命令行使用whisper
whisper audio.flac audio.mp3 audio.wav --model medium
whisper japanese.wav --language Japanese
whisper japanese.wav --language Japanese --task translate
whisper --help
其中命令详解如下:
1)model
可选 tiny|base|small|medium|larg。
2)language
语音转录的语种,如果不指定会截取音频的前 30 秒来判断语种。
3)task
可选 transcribe|translate。默认是transcribe,将语音转录为对应的语言字幕。 translate 是所有语言翻译为英文。
其中model是whisper进行语音识别必备的模型,运行程序时默认会在以下路径(C:\user\xxxx\.cache\whisper)查找模型。
因此需要提前下载好模型放在该位置。
4、在Python中使用whisper
import whisper
model = whisper.load_model("base")
result = model.transcribe("source/test.mp3")
print(result['text'])这段代码指的是将source文件目录下的test.mp3使用whisper的base模型进行语音识别,并打印出语音识别的结果。
经过对中文音频和日文音频测试,效果都不错,感兴趣的朋友可以试试。