使用匿名方法、迭代程序和局部类来创建优雅的代码
使用匿名方法、迭代程序和局部类来创建优雅的代码
迭代程序
在 C# 1.1 中,您可以使用 foreach 循环来遍历诸如数组、集合这样的数据结构:
string[] cities = {"New York","Paris","London"};
foreach(string city in cities)
{
Console.WriteLine(city);
}
实际上,您可以在 foreach 循环中使用任何自定义数据集合,只要该集合类型实现了返回 IEnumerator 接口的 GetEnumerator 方法即可。通常,您需要通过实现 IEnumerable 接口来完成这些工作:
public interface IEnumerable
{
IEnumerator GetEnumerator();
}
public interface IEnumerator
{
object Current{get;}
bool MoveNext();
void Reset();
}
在通常情况下,用于通过实现 IEnumerable 来遍历集合的类是作为要遍历的集合类型的嵌套类提供的。此迭代程序类型维持了迭代的状态。将嵌套类作为枚举器往往较好,因为它可以访问其包含类的所有私有 成员。当然,这是迭代程序设计模式,它对迭代客户端隐藏了底层数据结构的实际实现细节,使得能够在多种数据结构上使用相同的客户端迭代逻辑,如图 1 所示。
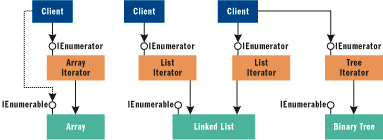
图 1 迭代程序设计模式
此 外,由于每个迭代程序都保持单独的迭代状态,所以多个客户端可以执行单独的并发迭代。通过实现 IEnumerable,诸如数组和队列这样的数据结构可以支持这种超常规的迭代。在 foreach 循环中生成的代码调用类的 GetEnumerator 方法简单地获得一个 IEnumerator 对象,然后将其用于 while 循环,从而通过连续调用它的 MoveNext 方法和当前属性遍历集合。如果您需要显式地遍历集合,您可以直接使用 IEnumerator(不用求助于 foreach 语句)。
但 是使用这种方法有一些问题。首先,如果集合包含值类型,则需要对它们进行装箱和拆箱才能获得项,因为 IEnumerator.Current 返回一个对象。这将导致潜在的性能退化和托管堆上的压力增大。即使集合包含引用类型,仍然会产生从对象向下强制类型转换的不利结果。虽然大多数开发人员不 熟悉这一特性,但是在 C# 1.0 中,实际上不必实现 IEnumerator 或 IEnumerable 就可以为每个循环实现迭代程序模式。编译器将选择调用强类型化版本,以避免强制类型转换和装箱。结果是,即使在 1.0 版本中,也可能没有导致性能损失。
为了更好地阐明这个解决方案并使其易于实现,Microsoft .NET 框架 2.0 在 System.Collections.Generics 命名空间中定义了一般的类型安全的 IEnumerable <ItemType> 和 IEnumerator <ItemType> 接口:
public interface IEnumerable<ItemType>
{
IEnumerator<ItemType> GetEnumerator();
}
public interface IEnumerator<ItemType> : IDisposable
{
ItemType Current{get;}
bool MoveNext();
}
除了利用泛型之外,新的接口与其前身还略有差别。与 IEnumerator 不同,IEnumerator <ItemType> 是从 IDisposable 派生而来的,并且没有 Reset 方法。图 2 中的代码显示了实现 IEnumerable <string> 的简单 city 集合,而图 3 显示了编译器在跨越 foreach 循环的代码时如何使用该接口。图 2 中的实现使用了名为 MyEnumerator 的嵌套类,它将一个引用作为构造参数返回给要枚举的集合。MyEnumerator 清楚地知道 city 集合(本例中的一个数组)的实现细节。MyEnumerator 类使用 m_Current 成员变量维持当前的迭代状态,此成员变量用作数组的索引。
第二个问题也是更难以解决的问题,就是迭代程序的实现。虽然对于简单的例子(如图 3所 示),实现是相当简单的,但是对于更高级的数据结构,实现将非常复杂,例如二叉树,它需要递归遍历,并需在递归时维持迭代状态。另外,如果需要各种迭代选 项,例如需要在一个链接表中从头到尾和从尾到头选项,则此链接表的代码就会因不同的迭代程序实现而变得臃肿。这正是设计 C# 2.0 迭代程序所要解决的问题。通过使用迭代程序,您可以让 C# 编译器为您生成 IEnumerator 的实现。C# 编译器能够自动生成一个嵌套类来维持迭代状态。您可以在一般集合或特定于类型的集合中使用迭代程序。您需要做的只是告诉编译器在每个迭代中产生的是什么。 如同手动提供迭代程序一样,您需要公开 GetEnumerator 方法,此方法通常是通过实现 IEnumerable 或 IEnumerable <ItemType> 来公开的。
您可以使用新的 C# 的 yield return 语句告诉编译器产生什么。例如,下面的代码显示了如何在 city 集合中使用 C# 迭代程序来代替图 2 中的手动实现:
public class CityCollection : IEnumerable<string>
{
string[] m_Cities = {"New York","Paris","London"};
public IEnumerator<string> GetEnumerator()
{
for(int i = 0; i<m_Cities.Length; i++)
yield return m_Cities[i];
}
}
您还可以在非一般集合中使用 C# 迭代程序:
public class CityCollection : IEnumerable
{
string[] m_Cities = {"New York","Paris","London"};
public IEnumerator GetEnumerator()
{
for(int i = 0; i<m_Cities.Length; i++)
yield return m_Cities[i];
}
}
此外,您还可以在完全一般的集合中使用 C# 迭代程序,如图 4 所示。当使用一般集合和迭代程序时,编译器从声明集合(本例中的 string)所用的类中型知道 foreach 循环内 IEnumerable <ItemType> 所用的特定类型:
LinkedList<int,string> list = new LinkedList<int,string>();
/* Some initialization of list, then */
foreach(string item in list)
{
Trace.WriteLine(item);
}
这与任何其他从一般接口进行的派生相似。如果出于某些原因想中途停止迭代,请使用 yield break 语句。例如,下面的迭代程序将仅仅产生数值 1、2 和 3:
public IEnumerator<int> GetEnumerator()
{
for(int i = 1;i< 5;i++)
{
yield return i;
if(i > 2)
yield break;
}
}
您的集合可以很容易地公开多个迭代程序,每个迭代程序都用于以不同的方式遍历集合。例如,要以倒序遍历 CityCollection 类,提供了名为 Reverse 的 IEnumerable <string> 类型的属性:
public class CityCollection
{
string[] m_Cities = {"New York","Paris","London"};
public IEnumerable<string> Reverse
{
get
{
for(int i=m_Cities.Length-1; i>= 0; i--)
yield return m_Cities[i];
}
}
}
这样就可以在 foreach 循环中使用 Reverse 属性:
CityCollection collection = new CityCollection();
foreach(string city in collection.Reverse)
{
Trace.WriteLine(city);
}
对于在何处以及如何使用 yield return 语句是有一些限制的。包含 yield return 语句的方法或属性不能再包含其他 return 语句,因为这样会错误地中断迭代。不能在匿名方法中使用 yield return 语句,也不能将 yield return 语句放到带有 catch 块的 try 语句中(也不能放在 catch 块或 finally 块中)。
迭代程序实现
编 译器生成的嵌套类维持迭代状态。当在 foreach 循环中(或在直接迭代代码中)首次调用迭代程序时,编译器为 GetEnumerator 生成的代码将创建一个带有 reset 状态的新的迭代程序对象(嵌套类的一个实例)。在 foreach 每次循环调用迭代程序的 MoveNext 方法时,它都从前一次 yield return 语句停止的地方开始执行。只要 foreach 循环执行,迭代程序就会维持它的状态。然而,迭代程序对象(以及它的状态)在多个 foreach 循环之间并不保持一致。因此,再次调用 foreach 是安全的,因为您将使新的迭代程序对象开始新的迭代。这就是为什么 IEnumerable <ItemType> 没有定义 Reset 方法的原因。
但是嵌套迭代程序类是如何实现的呢?并且如何管理它的状态呢?编译器将一个标准方法转换成一个可以被多 次调用的方法,此方法使用一个简单的状态机在前一个 yield return 语句之后恢复执行。您需要做的只是使用 yield return 语句指示编译器产生什么以及何时产生。编译器具有足够的智能,它甚至能够将多个 yield return 语句按照它们出现的顺序连接起来:
public class CityCollection : IEnumerable<string>
{
public IEnumerator<string> GetEnumerator()
{
yield return "New York";
yield return "Paris";
yield return "London";
}
}
让我们看一看在下面几行代码中显示的该类的 GetEnumerator 方法:
public class MyCollection : IEnumerable<string>
{
public IEnumerator<string> GetEnumerator()
{
//Some iteration code that uses yield return
}
}
当编译器遇到这种带有 yield return 语句的类成员时,它会插入一个名为 GetEnumerator$<random unique number>__IEnumeratorImpl 的嵌套类的定义,如图 5 中 C# 伪代码所示。(记住,本文所讨论的所有特征 — 编译器生成的类和字段的名称 — 是会改变的,在某些情况下甚至会发生彻底的变化。您不应该试图使用反射来获得这些实现细节并期望得到一致的结果。)嵌套类实现了从类成员返回的相同 IEnumerable 接口。编译器使用一个实例化的嵌套类型来代替类成员中的代码,将一个指向集合的引用赋给嵌套类的 <this> 成员变量,类似于图 2 中所示的手动实现。实际上,该嵌套类是一个提供了 IEnumerator 的实现的类。
递归迭代
当在像二叉树或其他任何包含相互连接的节点的复杂图形这样的数据结构上进行递归迭代时,迭代程序才真正显示出了它的优势。通过递归迭代手动实现一个迭代程序是相当困难的,但是如果使用 C# 迭代程序,这将变得很容易。请考虑图 6 中的二叉树。这个二叉树的完整实现是本文所提供的源代码的一部分。这个二叉树在节点中存储了一些项。每个节点均拥有一个一般类型 T(名为Item)的值。每个节点均含有指向左边节点的引用和指向右边节点的引用。比 Item 小的值存储在左边的子树中,比 Item 大的值存储在右边的子树中。这个树还提供了 Add 方法,通过使用参数限定符添加一组开放式的 T 类型的值:
public void Add(params T[] items);
这棵树提供了一个 IEnumerable <T> 类型的名为 InOrder 的公共属性。InOrder 调用递归的私有帮助器方法 ScanInOrder,把树的根节点传递给 ScanInOrder。ScanInOrder 定义如下:
IEnumerable<T> ScanInOrder(Node<T> root);
它返回 IEnumerable <T> 类型的迭代程序的实现,此实现按顺序遍历二叉树。对于 ScanInOrder 需要注意的一件事情是,它通过递归遍历这个二叉树的方式,即使用 foreach 循环来访问从递归调用返回的 IEnumerable <T>。在顺序 (in-order) 迭代中,每个节点都首先遍历它左边的子树,接着遍历该节点本身的值,然后遍历右边的子树。对于这种情况,需要三个 yield return 语句。为了遍历左边的子树,ScanInOrder 在递归调用(它以参数的形式传递左边的节点)返回的 IEnumerable <T>上使用 foreach 循环。一旦 foreach 循环返回,就已经遍历并产生了左边子树的所有节点。然后,ScanInOrder 产生作为迭代的根传递给其节点的值,并在 foreach 循环中执行另一个递归调用,这次是在右边的子树上。通过使用属性 InOrder,可以编写下面的 foreach 循环来遍历整个树:
BinaryTree<int> tree = new BinaryTree<int>();
tree.Add(4,6,2,7,5,3,1);
foreach(int num in tree.InOrder)
{
Trace.WriteLine(num);
}
// Traces 1,2,3,4,5,6,7
可以通过添加其他的属性用相似的方式实现前序 (pre-order) 和后序 (post-order) 迭代。虽然以递归方式使用迭代程序的能力显然是一个强大的功能,但是在使用时应该保持谨慎,因为可能会出现严重的性能问题。每次调用 ScanInOrder 都需要实例化编译器生成的迭代程序,因此,递归遍历一个很深的树可能会导致在幕后生成大量的对象。在对称二叉树中,大约有 n 个迭代程序实例,其中 n 为树中节点的数目。在任一特定的时刻,这些对象中大约有 log(n) 个是活的。在具有适当大小的树中,许多这样的对象会使树通过 0 代 (Generation 0) 垃圾回收。也就是说,通过使用栈或队列维护一列将要被检查的节点,迭代程序仍然能够方便地遍历递归数据结构(例如树)。
局部类型
C# 1.1 要求将类的全部代码放在一个文件中。而 C# 2.0 允许将类或结构的定义和实现分开放在多个文件中。通过使用 new partial 关键字来标注分割,可以将类的一部分放在一个文件中,而将另一个部分放在一个不同的文件中。例如,可以将下面的代码放到文件 MyClass1.cs 中:
public partial class MyClass
{
public void Method1()
{...}
}
在文件 MyClass2.cs 中,可以插入下面的代码:
public partial class MyClass
{
public void Method2()
{...}
public int Number;
}
实际上,可以将任一特定的类分割成任意多的部分。局部类型支持可以用于类、结构和接口,但是不能包含局部枚举定义。
局部 类型是一个非常有用的功能。有时,我们需要修改机器生成的文件,例如 Web 服务客户端包装类。然而,当重新生成此包装类时,对该文件的修改将会被丢弃。通过使用局部类,可以将这些改变分开放在单独的文件中。ASP.NET 2.0 将局部类用于 code-beside 类(从 code-behind 演变而来),单独存储页面中机器生成的部分。Windows 窗体使用局部类来存储 InitializeComponent 方法的可视化设计器输出以及成员控件。通过使用局部类型,两个或者更多的开发人员可以工作在同一个类型上,同时都可以从源控制中签出其文件而不互相影响。
您 可以问自己,如果多个不同的部分对同一个类做出了相互矛盾的定义会出现什么样的后果?答案很简单。一个类(或一个结构)可能具有两个不同的方面或性质:累 积性的 (accumulative) 和非累积性的 (non-accumulative)。累积性的方面是指类可以选择添加它的各个部分,比如接口派生、属性、索引器、方法和成员变量。
例如,下面的代码显示了一个部分是如何添加接口派生和实现的:
public partial class MyClass
{}
public partial class MyClass : IMyInterface
{
public void Method1()
{...}
public void Method2()
{...}
}
非累积性的方面是指一个类型的所有部分都必须一致。无论这个类型是一个类还是一个结构,类型可见性(公共或内部)和基类都是非累积性的方面。例如,下面的代码不能编译,因为并非 MyClass 的所有部分都出现在基类中:
public class MyBase
{}
public class SomeOtherClass
{}
public partial class MyClass : MyBase
{}
public partial class MyClass : MyBase
{}
//Does not compile
public partial class MyClass : SomeOtherClass
{}
除了所有的部分都必须定义相同的非累积性部分以外,只有一个部分能够重写虚方法或抽象方法,并且只有一个部分能够实现接口成员。
C# 2.0 是这样来支持局部类型的:当编译器构建程序集时,它将来自多个文件的同一类型的各个部分组合起来,并用 Microsoft 中间语言 (Microsoft intermediate language, MSIL) 将这些部分编译成单一类型。生成的 MSIL 中不含有哪一部分来自哪个文件的记录。正如在 C# 1.1 中一样,MSIL 不含有哪个文件用于定义哪个类型的记录。另外值得注意的是,局部类型不能跨越程序集,并且通过忽略其定义中的 partial 限定符,一个类型可以拒绝包含其他部分。
因为编译器所做的只是将各个部分累积,所以一个单独的文件可以包含多个部分,甚至是包含同一类型的多个部分(尽管这样做的意义值得怀疑)。
在 C# 中,开发人员通常根据文件所包含的类来为文件命名,这样可以避免将多个类放在同一个文件中。在使用局部类型时,我建议在文件名中指示此文件包含哪个类型的 哪些部分(例如 MyClassP1.cs、MyClassP2.cs),或者采用其他一致的方式从外形上指示源文件的内容。例如,Windows 窗体设计人员将用于该窗体的局部类的一部分存放在 Form1.cs 中,并将此文件命名为 Form1.Designer.cs。
局部类 的另一个不利之处是,当开始接触一个不熟悉的代码基时,您所维护类型的各个部分可能遍布在整个项目的文件中。在这种情况下,建议您使用 Visual Studio Class View,因为它可以将一个类型的所有部分积累起来展示给您,并允许您通过单击它的成员来导航各个不同的部分。导航栏也提供了这个功能。
匿名方法
C# 支持用于调用一个或多个方法的委托 (delegate)。委托提供运算符和方法来添加或删除目标方法,它也可以在整个 .NET 框架中广泛地用于事件、回调、异步调用、多线程等。然而,仅仅为了使用一个委托,有时您不得不创建一个类或方法。在这种情况下,不需要多个目标,并且调用 的代码通常相对较短而且简单。在 C# 2.0 中,匿名方法是一个新功能,它允许定义一个由委托调用的匿名(也就是没有名称的)方法。
例如,下面是一个常规 SomeMethod 方法的定义和委托调用:
class SomeClass
{
delegate void SomeDelegate();
public void InvokeMethod()
{
SomeDelegate del = new SomeDelegate(SomeMethod);
del();
}
void SomeMethod()
{
MessageBox.Show("Hello");
}
}
可以用一个匿名方法来定义和实现这个方法:
class SomeClass
{
delegate void SomeDelegate();
public void InvokeMethod()
{
SomeDelegate del = delegate()
{
MessageBox.Show("Hello");
};
del();
}
}
匿名方法被定义为内嵌 (in-line) 方法,而不是作为任何类的成员方法。此外,无法将方法属性应用到一个匿名方法,并且匿名方法也不能定义一般类型或添加一般约束。
您 应该注意关于匿名方法的两件值得关注的事情:委托保留关键字的重载使用和委托指派。稍后,您将看到编译器如何实现一个匿名方法,而通过查看代码,您就会相 当清楚地了解编译器必须推理所使用的委托的类型,实例化推理类型的新委托对象,将新的委托包装到匿名方法中,并将其指派给匿名方法定义中使用的委托(前面 的示例中的 del)。
匿名方法可以用在任何需要使用委托类型的地方。您可以将匿名方法传递给任何方法,只要该方法接受适当的委托类型作为参数即可:
class SomeClass
{
delegate void SomeDelegate();
public void SomeMethod()
{
InvokeDelegate(delegate(){MessageBox.Show("Hello");});
}
void InvokeDelegate(SomeDelegate del)
{
del();
}
}
如果需要将一个匿名方法传递给一个接受抽象 Delegate 参数的方法,例如:
void InvokeDelegate(Delegate del);
则首先需要将匿名方法强制转换为特定的委托类型。
下面是一个将匿名方法作为参数传递的具体而实用的示例,它在没有显式定义 ThreadStart 委托或线程方法的情况下启动一个新的线程:
public class MyClass
{
public void LauchThread()
{
Thread workerThread = new Thread(delegate()
{
MessageBox.Show("Hello");
});
workerThread.Start();
}
}
在前面的示例中,匿名方法被当作线程方法来使用,这会导致消息框从新线程中显示出来。
将参数传递到匿名方法
当定义带有参数的匿名方法时,应该在 delegate 关键字后面定义参数类型和名称,就好像它是一个常规方法一样。方法签名必须与它指派的委托的定义相匹配。当调用委托时,可以传递参数的值,与正常的委托调用完全一样:
class SomeClass
{
delegate void SomeDelegate(string str);
public void InvokeMethod()
{
SomeDelegate del = delegate(string str)
{
MessageBox.Show(str);
};
del("Hello");
}
}
如果匿名方法没有参数,则可以在 delegate 关键字后面使用一对空括号:
class SomeClass
{
delegate void SomeDelegate();
public void InvokeMethod()
{
SomeDelegate del = delegate()
{
MessageBox.Show("Hello");
};
del();
}
}
然而,如果您将 delegate 关键字与后面的空括号一起忽略,则您将定义一种特殊的匿名方法,它可以指派给具有任何签名的任何委托:
class SomeClass
{
delegate void SomeDelegate(string str);
public void InvokeMethod()
{
SomeDelegate del = delegate
{
MessageBox.Show("Hello");
};
del("Parameter is ignored");
}
}
明显地,如果匿名方法并不依赖于任何参数,而且您想要使用这种与委托签名无关的方法代码,则您只能使用这样的语法。注意,当调用委托时,您仍然需要提供参数,因为编译器为从委托签名中推理的匿名方法生成无名参数,就好像您曾经编写了下面的代码(在 C# 伪码中)一样:
SomeDelegate del = delegate(string)
{
MessageBox.Show("Hello");
};
此外,不带参数列表的匿名方法不能与指出参数的委托一起使用。
匿名方法可以使用任何类成员变量,并且它还可以使用定义在其包含方法范围之内的任何局部变量,就好像它是自己的局部变量一样。图 7 对此进行了展示。一旦知道如何为一个匿名方法传递参数,也就可以很容易地定义匿名事件处理,如图 8 所示。
因 为 += 运算符仅仅将一个委托的内部调用列表与另一个委托的内部调用列表连接起来,所以可以使用 += 来添加一个匿名方法。注意,在匿名事件处理的情况下,不能使用 -= 运算符来删除事件处理方法,除非将匿名方法作为处理程序加入,要这样做,可以首先将匿名方法存储为一个委托,然后通过事件注册该委托。在这种情况下,可以 将 -= 运算符与相同的委托一起使用,来取消将匿名方法作为处理程序进行注册。
匿名方法实现
编 译器为匿名方法生成的代码很大程度上依赖于匿名方法使用的参数或变量的类型。例如,匿名方法使用其包含方法的局部变量(也叫做外部变量)还是使用类成员变 量和方法参数?无论是哪一种情况,编译器都会生成不同的 MSIL。如果匿名方法不使用外部变量(也就是说,它只使用自己的参数或者类成员),则编译器会将一个私有方法添加到该类中,以便赋予方法一个唯一的名 称。该方法的名称具有以下格式:
<return type> __AnonymousMethod$<random unique number>(<params>)
和其他编译器生成的成员一样,这都是会改变的,并且最有可能在最终版本发布之前改变。方法签名将成为它指派的委托的签名。
编译器只是简单地将匿名方法定义和赋值转换成推理委托类型的标准实例,以包装机器生成的私有方法:
SomeDelegate del = new SomeDelegate(__AnonymousMethod$00000000);
非常有趣的是,机器产生的私有方法并不显示在 IntelliSense 中,也不能显式地调用它,因为其名称中的美元符号对于 C# 方法来说是一个非法标记(但它是一个有效的 MSIL 标记)。
当匿名方法使用外部变量时,情况会更加困难。如果这样,编译器将用下面的格式添加具有唯一名称的私有嵌套类:
__LocalsDisplayClass$<random unique number>
嵌套类有一个名为 <this> 的指向包含类的引用,它是一个有效的 MSIL 成员变量名。嵌套类包含与匿名方法使用的每个外部变量对应的公共成员变量。编译器向嵌套类定义中添加一个具有唯一名称的公共方法,格式如下:
<return type> __AnonymousMethod$<random unique number>(<params>)
方法签名将成为被指派的委托的签名。编译器用代码替代匿名方法定义,此代码创建一个嵌套类的实例,并进行必要的从外部变量到该实例的成员变量的赋值。最后,编译器创建一个新的委托对象,以便包装嵌套类实例的公共方法,然后调用该委托来调用此方法。图 9 用 C# 伪代码展示了编译器为图 7 中定义的匿名方法生成的代码。
一般匿名方法
匿名方法可以使用一般参数类型,就像其他方法一样。它可以使用在类范围内定义的一般类型,例如:
class SomeClass<T>
{
delegate void SomeDelegate(T t);
public void InvokeMethod(T t)
{
SomeDelegate del = delegate(T item){...}
del(t);
}
}
因为委托可以定义一般参数,所以匿名方法可以使用在委托层定义的一般类型。可以指定用于方法签名的类型,在这种情况下,方法签名必须与其所指派的委托的特定类型相匹配:
class SomeClass
{
delegate void SomeDelegate<T>(T t);
public void InvokeMethod()
{
SomeDelegate<int> del = delegate(int number)
{
MessageBox.Show(number.ToString());
};
del(3);
}
}
匿名方法示例
虽然乍一看匿名方法的使用可能像一种另类的编程技术,但是我发现它是相当有用的,因为在只要一个委托就足够的情况下,使用它就可以不必再创建一个简单方法。图 10 展示了一个有用的匿名方法的实际例子 — SafeLabel Windows 窗体控件。
Windows 窗体依赖于基本的 Win32 消息。因此,它继承了典型的 Windows 编程要求:只有创建窗口的线程可以处理它的消息。在 .NET 框架 2.0 中,调用错误的线程总会触发一个 Windows 窗体方面的异常。因此,当在另一个线程中调用窗体或控件时,必须将该调用封送到正确的所属线程中。Windows 窗体有内置的支持,可以用来摆脱这个困境,方法是用 Control 基类实现 ISynchronizeInvoke 接口,其定义如下:
public interface ISynchronizeInvoke
{
bool InvokeRequired {get;}
IAsyncResult BeginInvoke(Delegate method,object[] args);
object EndInvoke(IAsyncResult result);
object Invoke(Delegate method,object[] args);
}
Invoke 方法接受针对所属线程中的方法的委托,并且将调用从正在调用的线程封送到该线程。因为您可能并不总是知道自己是否真的在正确的线程中执行,所以通过使用 InvokeRequired 属性,您可以进行查询,从而弄清楚是否需要调用 Invoke 方法。问题是,使用 ISynchronizeInvoke 将会大大增加编程模型的复杂性,因此较好的方法常常是将带有 ISynchronizeInvoke 接口的交互封装在控件或窗体中,它们会自动地按需使用 ISynchronizeInvoke。
例如,为了替代公开 Text 属性的 Label 控件,您可以定义从 Label 派生的 SafeLabel 控件,如图 10 所示。SafeLabel 重写了其基类的 Text 属性。在其 get 和 set 中,它检查 Invoke 是否是必需的。如果是这样,则它需要使用一个委托来访问此属性。该实现仅仅调用了基类属性的实现,不过是在正确的线程上。因为 SafeLabel 只定义这些方法,所以它们可以通过委托进行调用,它们是匿名方法很好的候选者。SafeLabel 传递这样的委托,以便将匿名方法作为其 Text 属性的安全实现包装到 Invoke 方法中。
委托推理
C# 编译器从匿名方法指派推理哪个委托类型将要实例化的能力是一个非常重要的功能。实际上,它还提供了另一个叫做委托推理的 C# 2.0 功能。委托推理允许直接给委托变量指派方法名,而不需要先使用委托对象包装它。例如下面的 C# 1.1 代码:
class SomeClass
{
delegate void SomeDelegate();
public void InvokeMethod()
{
SomeDelegate del = new SomeDelegate(SomeMethod);
del();
}
void SomeMethod()
{...}
}
现在,您可以编写下面的代码来代替前面的代码片断:
class SomeClass
{
delegate void SomeDelegate();
public void InvokeMethod()
{
SomeDelegate del = SomeMethod;
del();
}
void SomeMethod()
{...}
}
当将一个方法名指派给委托时,编译器首先推理该委托的类型。然后,编译器根据此名称检验是否存在一个方法,并且它的签名是否与推理的委 托类型相匹配。最后,编译器创建一个推理委托类型的新对象,以便包装此方法,并将其指派给该委托。如果该类型是一个具体的委托类型(即除了抽象类型 Delegate 之外的其他类型),则编译器只能推理委托类型。委托推理的确是一个非常有用的功能,它可以使代码变得简练而优雅。
我相信,作为 C# 2.0 中的惯例,您会使用委托推理,而不是以前的委托实例化方法。例如,下面的代码说明了如何在不显式地创建一个 ThreadStart 委托的情况下启动一个新的线程:
public class MyClass
{
void ThreadMethod()
{...}
public void LauchThread()
{
Thread workerThread = new Thread(ThreadMethod);
workerThread.Start();
}
}
当启动一个异步调用并提供一个完整的回调方法时,可以使用一对委托推理,如图 11 所示。首先,指定异步调用的方法名来异步调用一个匹配的委托。然后调用 BeginInvoke,提供完整的回调方法名而不是 AsyncCallback 类型的委托。
属性和索引可见性
C# 2.0 允许为属性或索引器的 get 和 set 访问器指定不同的可见性。例如,在通常情况下,可能想将 get 访问器公开为 public,而把 set 访问器公开为 protected。为此,可以为 set 关键字添加 protected 可见性限定符。类似地,可以将索引器的 set 方法定义为 protected(请参见图 12)。
当 使用属性可见性时有几项规定。首先,应用在 set 或 get 上的可见性限定词只能是此属性本身可见性的严格子集。换句话说,如果此属性是 public,那么您就可以指定 internal、protected、protected internal、private。如果此属性可见性是 protected,就不能将 get 或 set 公开为 public。此外,只能分别为 get 或 set 指定可见性,而不能同时为它们指定可见性。
静态类
有 些类只有静态方法或静态成员(静态类),这是非常常见的。在这种情况下,实例化这些类的对象没有意义。例如,Monitor 类或类工厂(例如 .NET 框架 1.1 中的 Activator 类)都是静态类。在 C# 1.1 中,如果想要阻止开发人员实例化类的对象,您可以只提供一个私有的默认构造函数。如果没有任何公共的构造函数,就不可以实例化类的对象:
public class MyClassFactory
{
private MyClassFactory()
{}
static public object CreateObject()
{...}
}
然而,因为 C# 编译器仍然允许您添加实例成员(尽管可能从来都不使用它们),所以是否在类中只定义静态成员完全由您决定。C# 2.0 通过允许将类限定为 static 来支持静态类:
public static class MyClassFactory
{
static public T CreateObject<T>()
{...}
}
C# 2.0 编译器不允许您将一个非静态成员添加到一个静态类中,也不允许您创建此静态类的实例,就好像它是一个抽象类一样。此外,您不能从一个静态类派生子类。这就 如同编译器在静态类定义中加入了 abstract 和 sealed 一样。注意,可以定义静态类而不能定义静态结构,并且可以添加静态构造函数。
全局命名空间限定符
很可能有这样一个嵌套的命名空间,它的名称与一些其他的全局命名空间相匹配。在这种情况下,C# 1.1 编译器在解析命名空间引用时会出现问题。请考虑下例:
namespace MyApp
{
namespace System
{
class MyClass
{
public void MyMethod()
{
System.Diagnostics.Trace.WriteLine("It Works!");
}
}
}
}
在 C# 1.1 中,调用 Trace 类会产生编译错误(没有全局命名空间限定符 ::)。出现这种错误的原因在于,当编译器尝试解析对 System 命名空间的引用时,它使用直接包含范围,此范围包含 System 命名空间但不包含 Diagnostics 命名空间。C# 2.0 允许您使用全局命名空间限定符 :: 来表示编译器应该在全局范围内进行搜索。可以将 :: 限定符应用于命名空间和类型,如图 13 所示。
内联警告
C# 1.1 允许使用项目设置或者通过向编译器发布命令行参数来禁止特殊的编译器警告。其中的问题在于,这是一个全局取消,因此这样做会取消一些您仍然需要的警告。C# 2.0 允许使用 #pragma 警告指令显式地取消和恢复编译器警告:
// Disable 'field never used' warning
#pragma warning disable 169
public class MyClass
{
int m_Number;
}
#pragma warning restore 169
在生产代码中通常并不鼓励禁止警告。禁止警告只是为了进行某些分析,比如,当您尝试隔离一个问题时,或者当您设计代码并且想要得到代码 合适的初始结构而不必先行对其加以完善时。而在所有其他的情况下,都要避免取消编译器警告。注意,您不能通过编程的方式来重写项目设置,这意味着您不能使 用 pragma 警告指令来恢复全局取消的警告。
小结
本 文所提到的 C# 2.0 中的一些新功能是专门的解决方案,旨在处理特定的问题,同时可以简化整体编程模型。如果您关注工作效率和质量,您就需要让编译器生成尽可能多的实现,减少 重复性的编程任务,使最后得到的代码简洁易读。新的功能带给您的正是这些,并且我相信,它们象征着 C# 时代的到来,它会使自己成为服务于 .NET 专业开发人员的优秀工具。
Juval Lowy 是一名软件架构师,他提供 .NET 设计和移植方面的咨询和培训。他还是硅谷的 Microsoft 地区总裁 (Microsoft Regional Director)。他最新出版的一本书是 Programming .NET Components (O'Reilly, 2003)。可以在 http://www.idesign.net 上与 Juval 联系。
摘自 MSDN Magazine 的 2004 年 5 月刊。