【进阶】redis篇
redis是什么
nosql not only sql(不仅仅是sql) 泛指非关系型数据库 一般把非关系型数据库称为nosql数据库.
redis mongodb
redis是一个nosql类型的数据库(非关系型数据库),数据在内存中以键值对形式存储.
读写速度快,也提供数据持久化方式.
一般最常用的场景就是把redis用来做缓存.
redis使用场景
1.缓存
2.计数器 点赞
3.排行榜 数据结构, zset 按照分数排序
4.数据排重 去除重复数据
5.消息队列 redis中有一个list结构
6.分布式锁
redis线程模型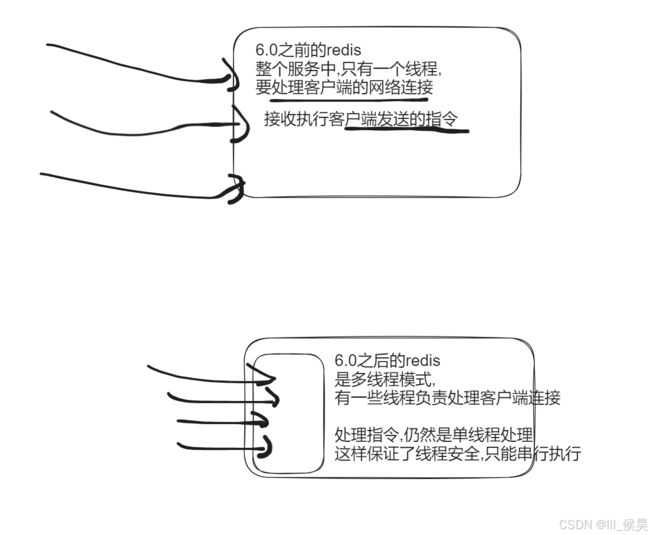
redis执行命令是单线程的为什么还这么快
1.数据都存储在内存中,读写速度都是内存级别的,所以快.
2.基于哈希结构存储, 通过key可以快速的在哈希表中找打对应的数据.
3.避免了上下文切换, 由于是单线程模式,所以不存在切换的开销.
redis持久化
为什么redis要提供持久化机制
我们现在除了缓存数据外,还将一些例如点赞等数据也是存储到redis的,这样服务万一断电,那么内存中的数据就丢失了.
所以redis提供了持久化功能
redis提供了两种持久化机制:
RDB:
是redis中默认的持久化机制(默认开启)
当满足条件时,会对内存中的数据进行拍照,以快照的方式把数据存储到.rdb文件中
快照(把key:value数据直接存储到rdb文件中)
触发持久化规则: 在redis.conf文件中
save 900 1 save 300 10 save 60 10000 也可以执行save命令
AOF:
也是redis中持久化的一种方式, 默认是没有启动的
需要在redis.conf文件中配置
appendonly no-->yes
aof方式,以执行日志的方式记录的,将所有写操作的命令按顺序追加记录到"appendonly.aof"文件中
还原数据时,逐行执行这些命令即可.
配置规则
appendfsync always 每次执行都会记录
appendfsync everysec 每秒执行一次
set k 1
set k 2
set c 2
set d 2
Redis 事务
redis中的事务相比于mysql事务,简单很多
redis中的事务,保证同一个事务在执行时, 事务中的多条命令执行时,不会有其他事务插入到中间执行,因为redis是单线程.
redis事务执行时,不保证多条指令执行的原子性, 多条指令执行时,中间如果有错误的命令,不会影响其他命令的执行.
mutil 命令开启事务
set key value 加入事务
set key value 加入事务
exec 执行事务中的命令
Key 过期策略
redisTemplate.opsForValue().set("k", "v",10,TimeUnit.SECONDS );
redis中为key维护一个状态,表示是否过期,
当定时时间到期后,将状态改为已过期,并没有立即删除key
在redis中有两种策略删除过期的key
1.惰性删除: 当key过期后,在下次使用此key时,发现key已经过期,然后再删除过期的key, 不足之处,浪费内存空间,优点,不需要有额外的线程定时定点的跟踪删除.
2.定期删除: 每隔指定的周期,对redis中过期的key进行清理.
Redis 和 mysql 如何保证数据一致
此问题讲的是如何尽可能的保证,redis中和mysql中的数据保持一致(主要是发生修改时)
采用延时双删策略,
在更新mysql之前先删除redis中的数据, 在mysql没有完全更新数据完成时,其他线程可以先读取旧的数据,
在mysql数据更新完成后,再次删除redis中的数据, 后来的线程确保读到就是最新的mysql中的数据.
缓存穿透
问题:
key对应的数据在数据库不存在,每次先查询缓存,缓存中没有,然后去查询数据库,数据库中也不存在,返回null,为null,没有往缓存中放,每次都还是直接查询的mysql.
解决方案
id10:值
id-1:null/-1
1.当mysql中查询不到时,可以向redis中存储一个key-value,value可以为null/-1,表名mysql中不存在
2.对参数进行校验不满足,就不查询.
3.使用布隆过滤器.
布隆过滤器
是一个二进制数组,用于判断元素是否存在.
使用k个哈希函数对某个值进行哈希计算,计算出来的哈希值存储到对应数组位置,把数组原来位置的0变为1.
查询是否存在时,同样用k个哈希函数计算哈希值,如果每个位置上都是1,表名数据可能存在,
只要有一个位置是0,那么数据肯定不存在的.
会有一定误判率
优点:
-
时间复杂度低,增加和查询元素的时间复杂为 O(N)
-
保密性强,布隆过滤器不存储元素本身
-
存储空间小,布隆过滤器是非常节省空间的
缺点:
-
误判
-
无法删除
缓存击穿
问题:
数据在数据库是存在的, 只是redis中的热点key过期了,这时有大量的请求到来,同时请求到mysql,导致mysql压力过大.
一般在秒杀这类场景中会发生的.
模拟秒杀: 1.写后台管理 管理秒杀商品 100
2.前端界面 卖商品
解决办法
1.热点数据设置较长过期时间,
2.跑定时任务,在缓存失效前刷进新的缓存
3.加锁,可以给查询mysql的代码进行加锁,一个线程查询完后,把数据放到redis中,对访问mysql进行控制.
缓存雪崩
问题:
大量的热点key过期,或者redis服务出现了问题,大量请求访问到mysql
解决办法
1.可以给热点key设置随机过期时间,避免同时过期
2.可以使用集群部署, 如果有一台redis服务出现问题,其他redis服务仍然可以使用,
还可以将热点的key,存储到不同的redis库中
3.跑定时任务,在缓存失效前刷进新的缓存