MTCNN 人脸检测技术揭秘:原理、实现与实战(附代码)
第一章:计算机视觉中图像的基础认知
第二章:计算机视觉:卷积神经网络(CNN)基本概念(一)
第三章:计算机视觉:卷积神经网络(CNN)基本概念(二)
第四章:搭建一个经典的LeNet5神经网络(附代码)
第五章:计算机视觉:神经网络实战之手势识别(附代码)
第六章:计算机视觉:目标检测从简单到容易(附代码)
第七章:MTCNN 人脸检测技术揭秘:原理、实现与实战(附代码)
第八章:探索YOLO技术:目标检测的高效解决方案
第九章:计算机视觉:主流数据集整理
第十章:生成对抗网络(GAN):从概念到代码实践(附代码)
一、MTCNN概述
MTCNN,即多任务级联卷积神经网络(Multi-task Cascaded Convolutional Networks),是一种用于人脸检测和对齐的深度学习方法。在2016年提出,旨在同时进行人脸检测和面部特征点定位(如眼睛、鼻子、嘴巴的位置)。该方法通过一个多阶段的级联卷积神经网络架构来实现高效且准确的人脸检测。
二、MTCNN示例
以下是一个简单的示例,展示如何使用MTCNN模型进行人脸检测,并在图像上绘制检测到的边界框及特征点,输入图片如下:
from mtcnn import MTCNN
import cv2
from matplotlib import pyplot as plt
# 加载图像
img = cv2.imread('abc.jpg')
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 初始化MTCNN
detector = MTCNN()
# 进行人脸检测
results = detector.detect_faces(img_rgb)
# 绘制边界框和特征点
for result in results:
# 获取边界框坐标
x, y, w, h = result['box']
# 绘制矩形框
cv2.rectangle(img_rgb, (x, y), (x + w, y + h), (255, 0, 0), 2)
# 获取关键点位置
keypoints = result['keypoints']
for point in keypoints.values():
# 绘制关键点
cv2.circle(img_rgb, point, 2, (0, 255, 0), 2)
# 显示结果
plt.figure(figsize=(10, 10))
plt.imshow(img_rgb)
plt.axis('off')
plt.show()
输出:
示例解释
- 加载图像:使用 OpenCV (
cv2) 加载图像,并将其从 BGR 格式转换为 RGB 格式,因为大多数深度学习框架默认使用 RGB 格式。 - 初始化 MTCNN:创建一个 MTCNN 对象,用于执行人脸检测。
- 人脸检测:调用
detect_faces方法对图像进行人脸检测,返回包含边界框和特征点信息的字典列表。 - 绘制边界框和特征点:
- 使用 OpenCV 的
rectangle函数绘制边界框。 - 使用
circle函数在检测到的面部特征点位置绘制小圆圈。
- 使用 OpenCV 的
- 显示结果:使用 Matplotlib 显示带有标注的图像。
三、MTCNN的特点
- 多任务学习:MTCNN不仅能够检测图像中的人脸位置,还能同时定位面部的关键特征点。
- 级联结构:采用三级级联的架构,每个阶段都有特定的任务和精度要求,逐步细化检测结果。
- 高效率与准确性:由于其设计上的优化,MTCNN能够在保证高准确性的同时保持较高的处理速度,适用于实时应用。
四、网络架构
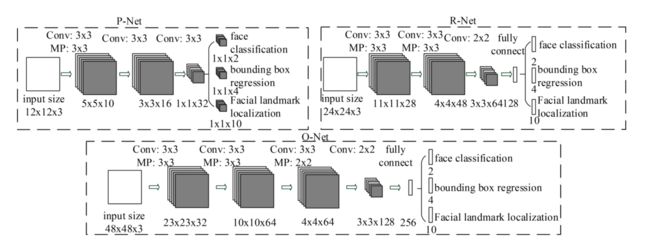
MTCNN的网络架构主要由三个阶段组成:
-
P-Net (Proposal Network):
- 目标:初步筛选出可能的人脸区域,并进行边界框回归和非极大值抑制(NMS)。
- 特点:轻量级网络,快速过滤大量非人脸区域。
-
R-Net (Refine Network):
- 目标:进一步过滤P-Net输出的结果,去除大量的假阳性样本,并再次进行边界框回归和NMS。
- 特点:比P-Net更复杂,能够提供更精确的边界框估计。
-
O-Net (Output Network):
- 目标:最终确定人脸位置,并同时预测五个面部特征点(两只眼睛、鼻尖、两个嘴角)的位置。
- 特点:最复杂的网络,提供最高精度的人脸检测和特征点定位。
五、工作流程
- 输入图像预处理:首先将原始图像缩放到不同尺度,以便能够检测到不同大小的人脸。
- P-Net阶段:对每个尺度的图像应用P-Net,生成一系列候选人脸区域。
- R-Net阶段:将P-Net生成的候选区域输入到R-Net,进一步筛选并精化边界框。
- O-Net阶段:最后一步,使用O-Net对剩余的候选区域进行最终的筛选,并输出精确的边界框和面部特征点位置。
- 后处理:包括边界框调整、特征点位置修正等步骤,以提高最终结果的质量。
5.1 图像预处理
在人脸检测任务中,图像可能包含不同大小的人脸。为了准确地检测出所有的人脸,无论其大小如何,我们通常需要将原始图像缩放到不同的尺度(即构建图像金字塔),然后在每个尺度上应用人脸检测算法。这样做可以使算法对不同距离拍摄的照片中的人脸都保持敏感,从而提高检测的准确性。
如何实现图像缩放
下面是一个简单的Python代码示例,演示如何使用OpenCV库将图像缩放到不同尺度:
import cv2
from matplotlib import pyplot as plt
def create_image_pyramid(image, scale_factor=0.79, min_size=(30, 30)):
"""
创建图像金字塔
:param image: 输入图像
:param scale_factor: 缩放因子,决定每次缩小图像的比例,默认为0.79
:param min_size: 最小尺寸,达到此尺寸后停止缩放,默认为(30, 30)
:return: 图像金字塔生成器
"""
yield image # 先返回原始图像
while True:
w = int(image.shape[1] * scale_factor)
h = int(image.shape[0] * scale_factor)
# 如果缩放后的尺寸小于设定的最小尺寸,则停止
if w < min_size[0] or h < min_size[1]:
break
# 使用双线性插值法缩放图像
image = cv2.resize(image, (w, h), interpolation=cv2.INTER_LINEAR)
yield image
# 示例使用
if __name__ == "__main__":
img_path = 'biye.jpeg' # 替换为你的图像路径
img = cv2.imread(img_path)
print("原始图像的尺寸:",img.shape)
# 创建图像金字塔并显示每一层图像
pyramid_images = list(create_image_pyramid(img, scale_factor=0.5,min_size=(500, 500)))
# 使用matplotlib显示图像
fig, axs = plt.subplots(nrows=len(pyramid_images), figsize=(8, len(pyramid_images)*4))
if len(pyramid_images) == 1:
axs.imshow(cv2.cvtColor(pyramid_images[0], cv2.COLOR_BGR2RGB))
else:
for ax, resized_img in zip(axs, pyramid_images):
ax.imshow(cv2.cvtColor(resized_img, cv2.COLOR_BGR2RGB))
ax.axis('on') # 不显示坐标轴
plt.tight_layout() # 自动调整子图参数,使之填充整个图像区域
plt.show()
在这个示例中,create_image_pyramid 函数接受一个图像、一个缩放因子和一个最小尺寸作为参数,并生成一系列缩放后的图像。scale_factor 控制每次缩放的比例,而 min_size 确保当缩放后的图像过小时停止进一步缩放。这样,你可以遍历这些不同尺度的图像并应用于人脸检测算法。
对于MTCNN而言,它已经内置了处理多尺度人脸的能力,所以通常不需要手动执行上述步骤。这里只是使用一个简单的例子,来理解这一过程有助于更深入地了解多尺度检测的基本原理。
5.2 P-Net阶段
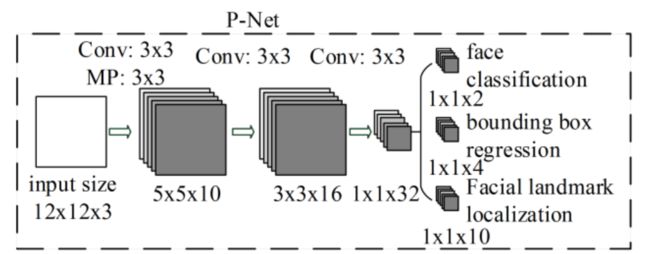
根据MTCNN论文中的描述,P-Net(Proposal Network)是用于初步人脸检测的网络。它是一个轻量级的卷积神经网络,旨在快速筛选出可能的人脸区域。以下是基于论文中提到的P-Net结构的一个实现示例,
#搭建模型
import torch
from torch import nn
# PNet 继承自 nn.Module,这是所有神经网络模块的基类。
class PNet(nn.Module):
"""
PNet 网络结构
- 全卷积网络
"""
def __init__(self):
super().__init__()
# conv1:第一层卷积层,输入通道数为3(对应RGB图像),输出通道数为10,使用3x3的卷积核,步长为1,不填充边缘。
self.conv1 = nn.Conv2d(in_channels=3,
out_channels=10,
kernel_size=3,
stride=1,
padding=0)
# mp1:最大池化层,使用3x3的池化窗口,步长为2,填充边缘以保持尺寸一致性。
self.mp1 = nn.MaxPool2d(kernel_size=3,
stride=2,
padding=1)
# conv2:第二层卷积层,输入通道数为10(上一层的输出通道数),输出通道数为16,使用3x3的卷积核,步长为1,不填充边缘。
self.conv2 = nn.Conv2d(in_channels=10,
out_channels=16,
kernel_size=3,
stride=1,
padding=0)
# conv3:第三层卷积层,输入通道数为16,输出通道数为32,使用3x3的卷积核,步长为1,不填充边缘。
self.conv3 = nn.Conv2d(in_channels=16,
out_channels=32,
kernel_size=3,
stride=1,
padding=0)
# classifier:分类分支,使用1x1的卷积核将特征图转换为2个输出通道,分别代表背景和人脸的概率。
self.classifier = nn.Conv2d(in_channels=32,
out_channels=2,
kernel_size=1,
stride=1,
padding=0)
# regressor:回归分支,同样使用1x1的卷积核,但输出4个值,用于预测边界框的位置调整。
self.regressor = nn.Conv2d(in_channels=32,
out_channels=4,
kernel_size=1,
stride=1,
padding=0)
# 函数定义了数据通过网络时的前向传播过程。
def forward(self, x):
# 输入张量 x 首先经过 conv1 卷积层,然后通过 mp1 最大池化层缩小特征图尺寸。
x = self.conv1(x)
x = self.mp1(x)
# 接着,特征图依次通过 conv2 和 conv3 进行进一步的特征提取。
x = self.conv2(x)
x = self.conv3(x)
# 最后,特征图被传递给两个分支:classifier 分支用于分类(判断是否为人脸),regressor 分支用于回归(调整边界框的位置)。
cls = self.classifier(x)
reg = self.regressor(x)
# 返回值 cls 和 reg 分别表示分类结果和回归结果。
return cls, reg
这段代码实现一个全卷积版本的P-Net,专门设计用于人脸检测任务。它包括以下几个关键步骤:
- 卷积层:用于从输入图像中提取特征。
- 最大池化层:减少特征图的空间维度,同时保留重要的特征信息。
- 分类与回归:最终通过两个1x1的卷积层分别得到分类和回归的结果。
这个模型的设计目的是为了高效地处理大量候选窗口,过滤掉大部分非人脸区域,为后续更精确的人脸检测和对齐提供高质量的候选人脸区域。
5.3 R-Net阶段
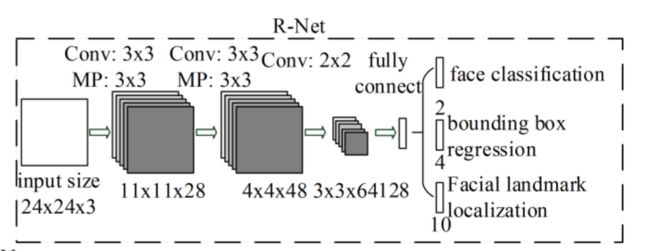
下面定义一个基于 PyTorch 的 R-Net 模型,它是 MTCNN中的第二阶段网络。R-Net 的主要任务是对 P-Net 生成的候选人脸区域进行进一步筛选,并提供更精确的边界框位置和人脸/非人脸分类。
# RNet 继承自 nn.Module,这是所有神经网络模块的基类。
class RNet(nn.Module):
"""
RNet网络
"""
def __init__(self):
super().__init__()
# conv1:第一层卷积层,输入通道数为3(RGB图像),输出通道数为28,使用3x3的卷积核,步长为1,不填充边缘。
self.conv1 = nn.Conv2d(in_channels=3,
out_channels=28,
kernel_size=3,
stride=1,
padding=0)
# mp1:第一个最大池化层,使用3x3的池化窗口,步长为2,填充边缘以保持尺寸一致性。
self.mp1 = nn.MaxPool2d(kernel_size=3,
stride=2,
padding=1)
# conv2:第二层卷积层,输入通道数为28(上一层的输出通道数),输出通道数为48,使用3x3的卷积核,步长为1,不填充边缘。
self.conv2 = nn.Conv2d(in_channels=28,
out_channels=48,
kernel_size=3,
stride=1,
padding=0)
# mp2:第二个最大池化层,使用3x3的池化窗口,步长为2,不填充边缘。
self.mp2 = nn.MaxPool2d(kernel_size=3,
stride=2,
padding=0)
# conv3:第三层卷积层,输入通道数为48,输出通道数为64,使用2x2的卷积核,步长为1,不填充边缘。
self.conv3 = nn.Conv2d(in_channels=48,
out_channels=64,
kernel_size=2,
stride=1,
padding=0)
# flatten:将多维的特征图展平成一维向量,以便输入到全连接层中。
self.flatten = nn.Flatten()
# linear:第一个全连接层,输入特征数为576(根据前几层的输出计算得出),输出特征数为128。
self.linear = nn.Linear(in_features=576, out_features=128)
# classifier:用于分类的全连接层,输入特征数为128,输出特征数为2(表示背景和人脸的概率)。
self.classifier = nn.Linear(in_features=128, out_features=2)
# regressor:用于回归的全连接层,输入特征数为128,输出特征数为4(表示边界框的位置调整参数)。
self.regressor = nn.Linear(in_features=128, out_features=4)
# forward 函数定义了数据通过网络时的前向传播过程。
def forward(self, x):
# 输入张量 x 首先经过一系列卷积层 (conv1, conv2, conv3)
# 和最大池化层 (mp1, mp2) 进行特征提取和空间维度的缩减。
x = self.conv1(x)
x = self.mp1(x)
x = self.conv2(x)
x = self.mp2(x)
x = self.conv3(x)
# 特征图随后被展平成一维向量 (flatten) 并传递给全连接层 (linear)。
x = self.flatten(x)
x = self.linear(x)
# 最终,特征向量被送入两个分支:classifier 分支用于分类(判断是否为人脸),
# regressor 分支用于回归(调整边界框的位置)。
cls = self.classifier(x)
reg = self.regressor(x)
# 返回值 cls 和 reg 分别表示分类结果和回归结果。
return cls, reg
这段代码实现一个用于人脸检测的 R-Net 模型,其设计目的是对 P-Net 提供的候选人脸区域进行进一步筛选并精化边界框。它包括以下几个关键步骤:
- 卷积层与池化层:用于从输入图像中提取特征,并通过池化操作减少特征图的空间维度。
- 全连接层:将特征图展平后输入到全连接层,进行更高层次的特征抽象。
- 分类与回归:最终通过两个独立的全连接层分别得到分类和回归的结果。
这个模型的设计是为了在保持较高精度的同时提高处理速度。
5.4 O-Net阶段
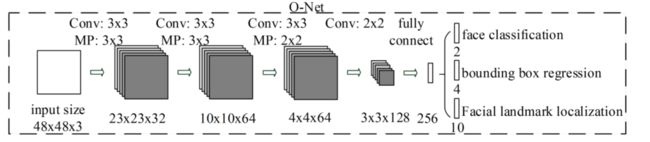
O-Net 是一个多任务网络,它在 R-Net 的基础上进一步细化人脸检测和边界框回归,并且还增加了面部关键点定位的功能。
import torch
from torch import nn
class ONet(nn.Module):
"""
O-Net 网络结构
- 用于精细的人脸检测、边界框回归以及面部关键点定位
"""
def __init__(self):
super().__init__()
# 卷积层
self.conv1 = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=3, stride=1, padding=0)
self.mp1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=0)
self.mp2 = nn.MaxPool2d(kernel_size=3, stride=2, padding=0)
self.conv3 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=0)
self.mp3 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
self.conv4 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=2, stride=1, padding=0)
# 全连接层
self.flatten = nn.Flatten()
self.linear = nn.Linear(in_features=1152, out_features=256) # 根据输入尺寸计算得出
# 分类器:判断是否为人脸
self.classifier = nn.Linear(in_features=256, out_features=2)
# 回归器:调整边界框位置
self.regressor = nn.Linear(in_features=256, out_features=4)
# 关键点定位:预测5个关键点的位置(每个关键点有x,y两个坐标)
self.landmark_predictor = nn.Linear(in_features=256, out_features=10)
def forward(self, x):
# 卷积层和池化层
# 数据首先经过一系列卷积层和最大池化层 (conv1, mp1, conv2, mp2, conv3, mp3, conv4) 提取特征。
x = self.conv1(x)
x = self.mp1(x)
x = self.conv2(x)
x = self.mp2(x)
x = self.conv3(x)
x = self.mp3(x)
x = self.conv4(x)
# 展平特征图
# 特征图被展平成一维向量 (flatten) 并传递给全连接层 (linear) 进行特征抽象。
x = self.flatten(x)
# 全连接层
x = self.linear(x)
# 分支输出
cls = self.classifier(x) # 分类结果
reg = self.regressor(x) # 边界框回归结果
landmark = self.landmark_predictor(x) # 面部关键点定位结果
return cls, reg, landmark
代码解释:
- 卷积层和池化层:与 P-Net 和 R-Net 类似,通过一系列卷积层和最大池化层提取图像特征。
- 全连接层:将展平后的特征图输入到一个全连接层中进行更高层次的特征抽象。
- 分类器、回归器和关键点定位器:分别用于人脸分类、边界框回归以及面部关键点的预测。
最终,特征向量被送入三个独立的全连接层:
- classifier 分支用于分类(判断是否为人脸)。
- regressor 分支用于回归(调整边界框的位置)。
- landmark_predictor 分支用于预测面部关键点的位置(每个关键点有x,y两个坐标)。
六、总结
MTCNN 是一种高效且准确的人脸检测和对齐方法,特别适合需要同时进行人脸检测和特征点定位的应用场景。通过其独特的多任务学习和级联结构设计,MTCNN 能够在保持高准确性的同时显著提升处理速度,使其成为许多计算机视觉任务中的首选方法之一。上述示例展示了如何使用 MTCNN 进行人脸检测,并在图像上可视化检测结果,有助于理解和应用这一强大的工具。
下面是一个简化版的对比表格,比较了MTCNN和YOLOv11在检测速度、模型大小、适用场景等方面的特性。实际性能可能会根据具体实现细节、硬件配置及优化程度有所不同。
| 特性/指标 | MTCNN | YOLOv11 |
|---|---|---|
| 主要用途 | 主要用于人脸检测与对齐 | 通用物体检测 |
| 检测速度 | 较慢,尤其是在高分辨率图像上处理时间较长 | 高速,实时处理能力强,尤其适合视频流分析 |
| 模型大小 | 相对较小 | 提供多种版本,从轻量级到重量级,适应不同需求 |
| 精度 | 对于人脸检测具有较高精度 | 在多种物体检测中表现出色,支持多类别目标检测 |
| 适用场景 | 面部识别系统、安防监控中的特定需求(如面部特征点定位) | 广泛应用于交通监控、智能零售、工业视觉等多个领域 |
| 训练数据集 | 主要针对人脸数据集 | 支持广泛的公开数据集,如COCO |
| 部署灵活性 | 针对面部特征点定位等有特殊需求时较为灵活 | 更加通用,易于适应不同的物体检测任务 |
| 硬件要求 | 对硬件要求相对较低 | 根据版本不同,对计算资源的需求有所差异,高性能版本需要更强的GPU支持 |
| 易用性 | 模型结构较简单,但对于非人脸目标扩展性差 | 提供了丰富的预训练模型和易于使用的API,适合快速开发 |
解释
-
检测速度:MTCNN由于其多阶段的设计,在处理速度上相对较慢,特别是在处理高分辨率图像时。而YOLO作为单阶段检测器,以其高效的设计实现了快速的目标检测,非常适合实时应用。
-
模型大小:MTCNN模型相对较小,因为它专注于面部检测任务。相比之下,YOLO提供了多种尺寸的模型版本,可以根据实际需求选择合适的大小,但即使是轻量级版本也通常比MTCNN大一些。
-
精度:虽然MTCNN在人脸检测方面表现出色,但其设计限制了它在其他类型物体检测上的应用。YOLO则通过其先进的架构设计和训练方法,在广泛的物体检测任务中都表现出良好的准确性。
-
适用场景:MTCNN特别适用于需要精确面部特征点定位的应用,例如面部识别系统。而YOLO因其通用性和高效性,被广泛应用于各种物体检测任务中,包括但不限于交通监控、智能零售、工业视觉等领域。
以上对比旨在提供一个高层次的概览,实际情况可能会因具体的使用案例、优化技术以及部署环境等因素而异。在选择模型时,应根据项目需求综合考虑这些因素。
决策树:如何选择合适的模型
是否需要人脸关键点?
├── 是 → MTCNN
└── 否 → 是否需要检测多类别物体?
├── 是 → YOLO
└── 否 → 部署硬件性能如何?
├── 低端设备 → MTCNN
└── 高端GPU → YOLO
通过对比可见,MTCNN在人脸专用场景仍具独特价值,而YOLO在通用性和速度上优势显著。