深度学习入门篇--来瞻仰卷积神经网络的鼻祖LeNet

B站视频讲解: 深度学习入门篇:使用pytorch搭建LeNet网络并代码详解实战
前言
大家在学习神经网络的时候肯定会有这样的感受, 有很多的文章和视频,有的文章也很好,但是总是不成体系,总是学起来东一榔锤,西一棒槌的,在这种情况下,我会给大家更新深度学习系列的技术文章, 轮椅级持续更新技术干货,别问为什么是轮椅级,因为保姆级已经过时了!
前置基础知识储备: python/pytorch/神经网络基础知识概念
正文
LeNet神经网络的前世今生
话说在20 世纪 80-90 年代,有一位叫小春哥的计算机大神, 他的小弟在学成之后就参加工作去了,但是在工作中,这位小弟被虐的体无完肤,一串一串的数字是又长又难处理,但是他在项目经理那里已经立下军令状,3天之内必须用自动化的方式来处理这些一串串手写的数字,小弟看了看时间,今天就是截止日期,这可把小弟给急坏了,思来想去还是求教师父不能给师傅丢人啊,痛定思痛找到小春哥,扑通跪倒在地,一把鼻涕一把泪的说道:师父救我!
小春哥闭目养神说道:走之前不是说了嘛,你闯出祸来,不要把为师说出来就行了.
只见小弟大声哭道: 师父, 弟子遇到大麻烦了.
小春哥慢慢说到你且到来,弟子走道小春哥耳边说了一通
小春哥哈哈大笑道:这又有何难啊,容为师给你写个程序,你拿去用即可!
只见小春哥霹雳吧啦一顿操作猛如虎,灵光乍现,根据前人的BP算法直接创造性的提出了LeNet 神经网络结构
小春哥从此奠定了卷积神经网络的基础,后代弟子在此基础上把卷积神经网络发扬光大!(2012年的AlexNet, 2014年的VGG,2015年的ResNet,2016年YOLO系列) 从此走上神坛,被誉为卷积神经网络之父!
小春哥的大号叫做Yann LeCun, 提出了的卷积神经网络叫做LeNet-5,它是一种专注于图像数据的卷积神经网络模型,当时应用于银行和邮政机构需要自动处理手写数字识别(如支票和邮件地址),甚至到目前为止银行和邮政机构还在跑着当年小春哥的代码!
LeCun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11): 2278-2324.
网络结构详解
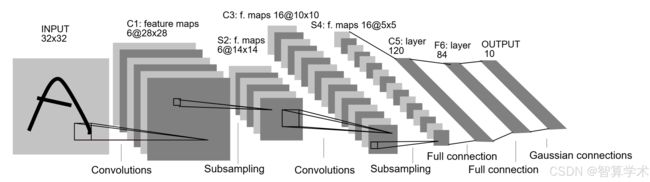
小春哥练的这套功法看起来很复杂,其实掰开了看,非常简单,大家不要被它复杂的外表所吓倒! 跟着我一起来从理论到代码来实践它吧!
卷积神经网络的开山之作LeNet的网络结构一共分为7层 : 卷积层 池化层 卷积层 池化层外加3个全连接层,我们先来一层一层的看
C1(卷积层)
在原论文中的图片32x32,并没有颜色,我们这里输入的图片改为3x32x32的图片
pytorch tensor的通道排序: [batch,channel,height,width]
C1层使用了6个大小为5×5的卷积核,步长为1,padding=0, 卷积后得到6张28×28的特征图,有的同学肯定会问,经过卷积后的特征图的张数我会计算就是几个卷积核得到的特征图就是几张,但是28x28怎么来的呢?
这里有个简便的计算公式给到大家:(在pytorch文档中的计算公式更复杂,这里我们把默认为1的值计算整理后,得到的公式,99.9%的情况下,用这个公式计算足以)
经过卷积的矩阵尺寸大小计算公式为: N = (W - F + 2P)/S +1
a: 输入图片的大小为 w x w
b: Filter 大小 F x F (卷积核的大小)
c: 步长s
p: padding 的像素数p
经过C1卷积层的变换如下: (3,32,32)—>(6,28,28)
计算过程如下:
卷积核是6个5x5,那么对应的输出通道数就是6
(32-5+0)/1 + 1 = 28
S2 池化层
在池化层只改变尺寸(高度和宽度), 不会改变通道数!!!
这一层使用了6个2×2 的平均池化,步长为2,池化后得到6张14×14的特征图, 变换结果为(6,28,28)----->(6,14,14)
计算结果如下:
通道数不变,为6
(28-2+0)/2 + 1 = 14
C3(卷积层)
这一层使用了16个大小为5×5的卷积核,步长为1,padding=0, 得到 (16,10,10)的特征图,也即(6,14,14)---->(16,10,10)
计算结果如下:
使用了16个卷积核,也就是输出通道数为16
(14-5+0)/1 + 1 = 10
S4(池化层)
这一层使用16个2×2的平均池化,步长为2,池化后得到(16x5x5) 的特征图 也即: (16,10,10)----->(16,5,5)
计算结果如下:
经过池化层,通道数不变,还是原来的16
(10-2+0)/2 + 1 = 5
F5/F6/F7(全连接层)
维度变化: 400–>120—>84---->10
代码实战
如果基础不太好的同学也没关系,我后面会出关于pytorch的写神经网络代码的基础套路的文章和对应的视频,直接往里面套用就可以,很简单哒! 敬请期待
有基础的同学可以直接看下面的代码!
model模块
from turtle import forward
from torch import relu
import torch
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super().__init__()
"""
分别对应的含义: (in_channels:输入通道数, out_channels:输出通道数,
kernel_size:卷积核的大小并不是数量,stride =1: 步长默认为1可以省略,padding = 0: 默认为0)
计算公式: 经过卷积后的矩阵尺寸大小计算公式为 N = (M - F + 2P)/S +1
其中 输入图片大小为MxM,Filter大小为FxF,步长s,padding 为p
"""
self.net = nn.Sequential(
nn.Conv2d(3, 6, 5, 1, 0),nn.ReLU(), # input(3,32,32) output(6,28,28)
nn.MaxPool2d(2, 2, 0), # output(6,14,14)
nn.Conv2d(6, 16, 5, 1, 0),nn.ReLU(), # output(16,10,10)
nn.MaxPool2d(2, 2, 0), # output(16,5,5)
nn.Flatten(),
nn.Linear(16*5*5, 120),nn.ReLU(),
nn.Linear(120, 84),nn.ReLU(),
nn.Linear(84, 10)
)
def forward(self,x):
return self.net(x)
train模块
from random import shuffle
import torch
from model import LeNet
import torchvision
import torch.nn as nn
import torchvision.transforms as transforms
import torch.optim as optim
import torch.utils
def main():
# 使用gpu进行计算
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))]
)
"""
数据结构
训练集:50,000 张图像,按照 10 个类别平均分配,每类包含 5,000 张。
测试集:10,000 张图像,每类包含 1,000 张。
数据格式:
每张图像存储为 3D 张量,形状为 (3, 32, 32),对应 3 个通道(RGB)和图像大小。
标签是 0 到 9 的整数,表示所属类别。
"""
train_set = torchvision.datasets.CIFAR10(root="./data",train=True,
download=True,transform=transform)
train_loader = torch.utils.data.DataLoader(train_set,batch_size=36,
shuffle=True,num_workers=0)
test_set = torchvision.datasets.CIFAR10(root="./data",train=True,
download=True,transform=transform)
test_loader = torch.utils.data.DataLoader(test_set,batch_size=5000,
shuffle=True,num_workers=0)
# 构建一个迭代器,用于迭代出测试数据,因为CIFAR10的测试数据只有10000张,并且batch_size设置了10000,
# 那么直接就可以迭代一次就可以了,准备测试数据,用于后面使用
dataiter = iter(test_loader)
test_images, test_labels = next(dataiter)
test_images = test_images.to(device)
test_labels = test_labels.to(device)
"""
测试代码:用于测试下载的数据
"""
# classes = ('plane', 'car', 'bird', 'cat',
# 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# import matplotlib.pyplot as plt
# import numpy as np
# def imshow(img):
# img = img / 2 + 0.5 # unnormalize
# npimg = img.numpy()
# plt.imshow(np.transpose(npimg, (1, 2, 0)))
# plt.show()
# # show images
# imshow(torchvision.utils.make_grid(images))
# # print labels
# print(' '.join(f'{classes[labels[j]]:5s}' for j in range(batch_size)))
"""
数据进行训练
"""
#实例化模型
net = LeNet()
net = net.to(device)
# 损失函数
loss_function = nn.CrossEntropyLoss()
loss_function = loss_function.to(device)
# 迭代器 optim 是pytorch的模块,其中Adam是一个优化算法
optimizer = optim.Adam(net.parameters(), lr=0.001)
#训练轮数
for epoch in range(5):
running_loss = 0.0
for step , data in enumerate(train_loader, start=0):
# get the inputs; data is a list of [inputs,labels]
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = loss_function(outputs,labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if step % 500 == 499:
with torch.no_grad():
outputs = net(test_images)
predict_y = torch.max(outputs, dim=1)[1]
accuracy = torch.eq(predict_y,test_labels).sum().item() / test_labels.size(0)
print('[%d, %5d] train_loss: %.3f test_accuracy:%.3f' %
(epoch+1,step+1,running_loss / 500, accuracy))
running_loss = 0.0
print("Finished Training")
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
if __name__ == '__main__':
main()
predict 模块
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import LeNet
def main():
# 准备做图片转换
transform =transforms.Compose([
# 这里只调整图片的宽度和长度,对于通道数并不进行改变
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
])
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
net.load_state_dict(torch.load("Lenet.pth"))
im = Image.open("dog.png").convert("RGB")
im = transform(im) # [c,h,w]
im = torch.unsqueeze(im,dim=0) # [N,c,h,w]
with torch.no_grad():
outputs = net(im)
predict = torch.argmax(outputs,dim=1).item()
print(classes[predict])
if __name__ == "__main__":
main()