【AI论文】SongGen:用于文本到歌曲生成的单阶段自回归Transformer模型
摘要:文本到歌曲生成任务,即根据文本输入创作歌词和伴奏,由于领域复杂性和数据稀缺性,面临着重大挑战。现有方法通常采用多阶段生成流程,导致训练和推理过程繁琐。在本文中,我们提出了SongGen,一个完全开源的单阶段自回归Transformer模型,专为可控歌曲生成而设计。该模型能够对多种音乐属性进行细粒度控制,包括歌词、乐器描述、流派、情绪和音色等文本信息,同时还提供可选的三秒参考片段用于声音克隆。在一个统一的自回归框架内,SongGen支持两种输出模式:混合模式,直接生成歌词和伴奏的混合内容;双轨模式,分别合成歌词和伴奏,以便在下游应用中提供更大的灵活性。我们为每种模式探索了多种令牌(token)模式策略,取得了显著的改进并获得了有价值的见解。此外,我们还设计了一条自动化的数据预处理流水线,并实施了有效的质量控制。为了促进社区参与和未来研究,我们将发布模型权重、训练代码、标注数据和预处理流水线。生成的样本展示在我们的项目页面github。Huggingface链接:Paper page,论文链接:2502.13128
1. 引言
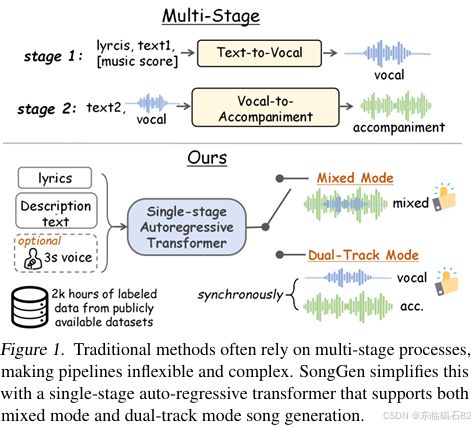
SongGen模型旨在解决文本到歌曲生成(Text-to-Song Generation)这一复杂任务,该任务要求从文本输入中创建歌词和伴奏。由于音乐领域的复杂性和数据稀缺性,这一任务面临着重大挑战。传统方法通常采用多阶段生成流程,导致训练和推理过程繁琐。SongGen模型提出了一种创新的单阶段自回归Transformer架构,旨在简化流程并提高生成效果。
2. 相关工作
2.1 文本到音乐生成
近年来,文本到音乐生成模型取得了显著进展,这些模型使用描述性文本作为条件来控制音乐生成。然而,尽管这些模型在生成高质量乐器音乐方面表现出色,但在生成逼真的歌词方面仍面临重大挑战。
2.2 歌曲生成
歌曲生成是一个涉及歌词创作、乐器编排和和谐生成的综合任务。现有的歌曲生成模型如Jukebox、Melodist和MelodyLM等,虽然在一定程度上解决了歌曲生成的问题,但往往采用多阶段生成流程,导致训练和推理过程复杂且耗时。此外,这些模型的语料库通常局限于某种特定风格或语言,缺乏多样性。
3. 方法论
3.1 概述
SongGen模型由一个自回归Transformer解码器和一个现成的神经音频编解码器组成。Transformer解码器预测一系列音频令牌,允许通过交叉注意力机制控制用户输入。最终的歌曲通过音频编解码器解码器从这些令牌中合成。
3.2 自回归编解码器语言建模
3.2.1 音频令牌化
音频令牌化的有效性对基于Transformer的歌曲生成至关重要。SongGen模型采用X-Codec音频编解码器,该编解码器基于残差向量量化器(RVQ),将音频信号编码和量化为一系列令牌向量。
3.2.2 混合模式
在混合模式下,SongGen模型直接使用由X-Codec从混合音频(即原始音频)编码的混合音频令牌作为输出目标。然而,由于混合音频中歌词与伴奏的重叠,导致歌词信号噪声比低,模型在生成清晰歌词方面面临挑战。为了解决这一问题,SongGen模型引入了辅助歌词令牌预测目标,通过专门的线性头来预测歌词令牌,从而显著提高了生成歌词的清晰度。
3.2.3 双轨模式
在双轨模式下,SongGen模型分别生成歌词和伴奏两个关键组件。为了确保两个轨道之间的和谐性,SongGen模型引入了并行和交错两种组合模式。并行模式将伴奏和歌词音频令牌沿代码本维度连接,而交错模式则将两个轨道的令牌沿时间维度交错排列。实验结果表明,交错(A-V)模式在保持歌词和伴奏之间精确帧级对齐方面表现最佳。
3.3 模型条件
3.3.1 歌词条件
为了应对数据稀缺性挑战,SongGen模型采用6681个令牌的VoiceBPE(字节对编码)分词器将歌词转换为类似音素的令牌序列。随后,这些令牌通过一个小型Transformer基编码器(即歌词编码器)以提取关键的发音相关信息。
3.3.2 声音条件
SongGen模型采用冻结的MERT(音乐表示模型)编码器来生成稳健的声音特征嵌入,从而实现对音色和演唱技巧的控制。模型随机选择3秒的声乐片段作为声音条件输入,并通过1D卷积层聚合MERT的隐藏层和输出层输出以生成声音嵌入。
3.3.3 文本条件
SongGen模型的文本描述涵盖了包括乐器、音乐情绪、节奏、流派和歌手性别在内的多种音乐属性。给定与歌曲匹配的描述文本,模型采用冻结的FLAN-T5编码器来获取文本嵌入。
3.4 自动化数据预处理流水线
由于目前没有公开可用的包含配对音频、歌词和字幕的文本到歌曲生成数据集,SongGen模型开发了一条自动化的数据注释流水线,通过多种过滤策略来确保数据的高质量。该流水线包括数据源收集、源分离、分割、歌词识别和字幕生成等步骤。经过预处理后,训练数据集包含约540K个英语声乐片段,总计约2000小时音频。
3.5 训练方案
3.5.1 混合模式训练
混合模式训练包括三个关键步骤:模态对齐、无声音支持和高质量微调。通过逐步增强模型对输入模态和音频输出之间对齐的能力,并在没有参考声音的情况下保持模型功能,最终通过高质量微调来优化模型性能。
3.5.2 双轨模式训练
由于从头开始训练双轨模式具有挑战性,SongGen模型采用预训练的混合模式模型进行初始化,并通过仅微调Transformer解码器来适应新的令牌模式。随后的训练步骤与混合模式的步骤2和步骤3相似。
3.5.3 课程学习
为了调整训练过程中代码本损失的权重,SongGen模型采用课程学习策略。在训练初期,模型优先关注最重要的组件(即前三个代码本),并随着训练的进行逐渐平衡权重,以捕捉更精细的音频细节。
4. 实验
4.1 实验设置
4.1.1 基线模型
由于缺乏开源的文本到歌曲生成模型,SongGen模型与两种最先进的文本到音乐生成模型(Stable Audio Open和MusicGen)以及经过微调的文本到语音模型(Parler-tts)进行比较。此外,还通过主观评估与商业产品Suno进行了比较。
4.1.2 评估数据集和指标
评估数据集通过过滤MusicCaps基准测试集中的英语声乐样本获得,包含326个样本。实验采用客观和主观评估相结合的方式进行。客观评估指标包括弗雷歇音频距离(FAD)、KL散度、CLAP分数、音素错误率(PER)和说话人嵌入余弦相似度(SECS)。主观评估则通过平均意见分数(MOS)测试来评估整体质量、与文本描述的相关性、声乐质量、和声质量以及与原始歌手的相似性。
4.2 文本到歌曲生成结果
4.2.1 与基线模型的比较
SongGen模型在混合模式和双轨模式下均显著优于基线模型。尽管与Ground Truth和Suno相比仍存在一定差距,但考虑到SongGen模型仅使用2000小时标记数据,其性能已经相当具有竞争力。
4.2.2 混合模式与双轨模式的比较
在混合模式下,“Mixed Pro”方法通过引入辅助歌词令牌预测目标,在所有指标上均优于基本的“Mixed”模型,特别是在声乐质量方面。在双轨模式下,“交错(A-V)”模式表现最佳,尽管并行模式在计算上更高效,但其性能不如交错模式。
4.2.3 没有参考声音的情况
实验还探索了在没有参考声音的情况下SongGen模型的歌曲生成能力。结果表明,尽管性能略有下降,但模型仍然能够生成令人愉悦的、声乐连贯的歌曲。
4.3 消融研究
4.3.1 训练策略的有效性
高质量微调和课程学习策略均显著提高了模型性能,验证了这些策略的有效性。
4.3.2 歌词模块设计的影响
实验结果表明,采用VoiceBPE分词器、歌词编码器和交叉注意力机制的歌词模块设计在所有指标上均取得了最佳结果。
5. 结论
SongGen模型是一种完全开源的单阶段自回归Transformer模型,专为可控歌曲生成而设计。通过在一个统一的自回归框架内支持混合模式和双轨模式两种输出模式,SongGen模型能够灵活地生成符合用户需求的歌曲。实验结果表明,SongGen模型在生成高质量歌曲方面表现出色,并具有显著的细粒度控制能力。此外,通过发布模型权重、训练代码、标注数据和预处理流水线,SongGen模型有望促进社区参与和未来研究的发展。
6. 影响声明
SongGen模型的提出为音乐创作领域带来了新的可能性。它降低了音乐创作的门槛,使得内容创作者和新手能够轻松表达自己的创造力。然而,随着自主生成歌曲和声音克隆技术的出现,也带来了版权侵权、知识产权滥用和深度伪造音频等风险。因此,在开发和应用此类技术时,需要谨慎考虑其伦理和社会影响。
7. 未来工作
尽管SongGen模型在文本到歌曲生成任务上取得了显著进展,但仍存在一些局限性。例如,由于开源歌曲数据的稀缺性,当前模型只能生成长达30秒的歌曲片段。未来工作将包括训练一个渲染器来上采样音频以提高输出质量,并探索生成具有完整结构歌曲的方法。此外,还将研究如何进一步提高模型的细粒度控制能力以生成更符合用户需求的歌曲。
8. 附录
附录部分提供了详细的实验设置、评估指标计算方法、消融研究结果以及不同音频编解码器性能比较等额外信息。这些信息有助于读者更全面地了解SongGen模型的设计和实现细节以及实验验证过程。
通过对2502.13128v1.pdf文献的详细总结,我们可以全面了解SongGen模型的设计思路、实现细节、实验验证过程以及其在文本到歌曲生成任务上的性能和潜力。SongGen模型作为一种创新的单阶段自回归Transformer模型,为可控歌曲生成领域带来了新的突破和可能性。