Redis---LRU原理与算法实现
文章目录
-
- LRU概念理解
- LRU原理
- 基于HashMap和双向链表实现LRU
- Redis中的LRU的实现
-
- LRU时钟
- 淘汰策略
- 近似LRU的实现
- LRU算法的优化
- Redis LRU的核心代码逻辑
- Redis LRU的核心代码逻辑
- Redis LRU的配置参数
- Redis LRU的优缺点
- Redis LRU的优缺点
LRU概念理解
LRU(Least Recently Used) 最近最少使用算法,是一种常用的页面置换算法,广泛应用于操作系统中的内存管理和缓存系统。LRU 的基本思想是:当缓存空间满时,当需要置换页面时,选择最近最少使用的页面进行淘汰。
LRU原理
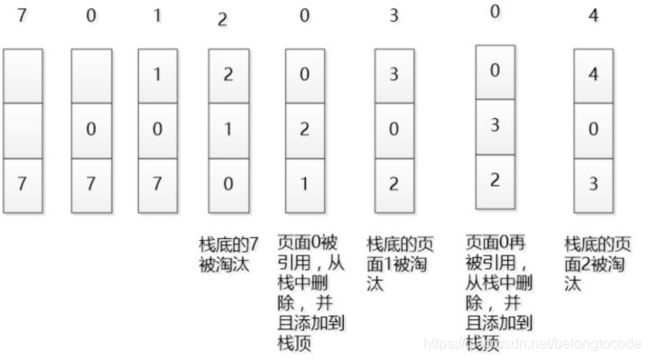
可以用一个特殊的栈来保存当前正在使用的各个页面的页面号。当一个新的进程访问某页面时,便将该页面号压入栈顶,其他的页面号往栈底移,如果内存不够,则将栈底的页面号移除。这样,栈顶始终是最新被访问的页面的编号,而栈底则是最近最久未访问的页面的页面号。
在一般标准的操作系统教材里,会用下面的方式来演示 LRU 原理,假设内存只能容纳3个页大小,按照 7 0 1 2 0 3 0 4 的次序访问页。假设内存按照栈的方式来描述访问时间,在上面的,是最近访问的,在下面的是,最远时间访问的,LRU就是这样工作的。
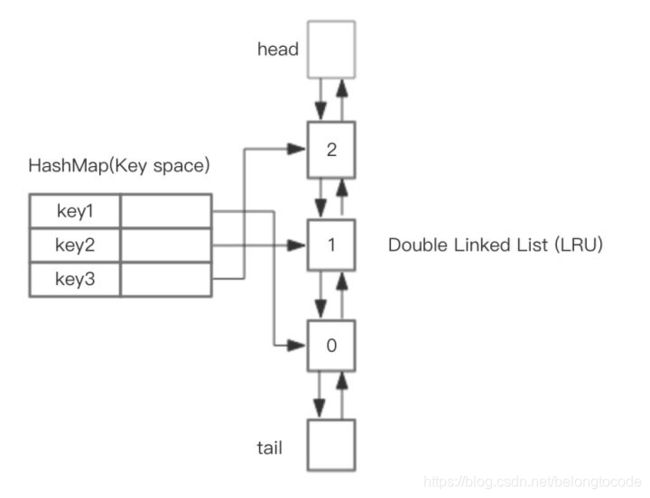
基于HashMap和双向链表实现LRU
HahsMap用于快速查找到结点所在位置,然后将使用到的结点放在对头,这样最近最少使用的结点自然就落入到队尾。双向链表提供了良好的灵活性,两边可达。如下图所示。
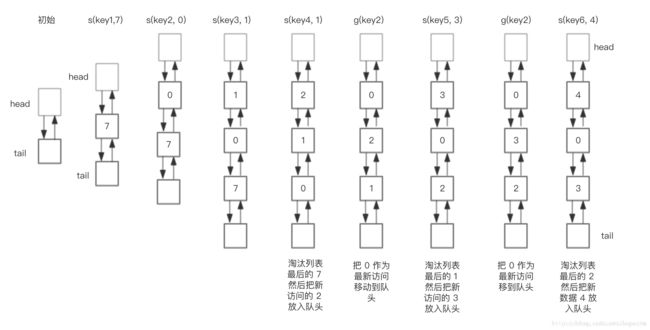
假设我们需要执行如下操作
save(“key1”, 7)
save(“key2”, 0)
save(“key3”, 1)
save(“key4”, 2)
get(“key2”)
save(“key5”, 3)
get(“key2”)
save(“key6”, 4)
使用HashMap + 双向链表数据结构实现的LRU操作双向链表部分的轨迹如下。
核心操作的步骤:
- save(key, value)
- 首先在 HashMap 找到 Key 对应的节点,如果节点存在,更新节点的值,并把这个节点移动队头。
- 如果不存在,需要构造新的节点,并且尝试把节点塞到队头。
- 如果LRU空间不足,则通过 tail 淘汰掉队尾的节点,同时在 HashMap 中移除 Key。
- get(key),通过 HashMap 找到 LRU 链表节点,把节点插入到队头,返回缓存的值。
完整基于Java的代码参考如下
package LRU;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
public class LRUCache {
// 定义双向链表的节点类
class DLinkedNode {
String key; // 节点的键
int value; // 节点的值
DLinkedNode pre; // 前驱节点
DLinkedNode post; // 后继节点
}
// 使用ConcurrentHashMap来存储缓存数据,保证线程安全
private ConcurrentMap<String, DLinkedNode> cache = new ConcurrentHashMap<String, DLinkedNode>();
private int count; // 当前缓存中的元素数量
private int capacity; // 缓存的最大容量
private DLinkedNode head, tail; // 双向链表的头节点和尾节点
// 构造函数,初始化LRU缓存
public LRUCache(int capacity) {
this.count = 0;
this.capacity = capacity;
// 初始化头节点和尾节点
head = new DLinkedNode();
head.pre = null;
tail = new DLinkedNode();
tail.post = null;
// 头节点和尾节点相互连接
head.post = tail;
tail.pre = head;
}
// 获取缓存中的值
public int get(String key) {
DLinkedNode node = cache.get(key);
if(node == null){
return -1; // 如果缓存中没有该键,返回-1
}
// 将该节点移动到链表头部,表示最近使用
moveToHead(node);
return node.value;
}
// 向缓存中插入或更新值
public void put(String key, int value) {
DLinkedNode node = cache.get(key);
if (node != null) {
// 如果键已存在,更新值并将节点移动到链表头部
node.value = value;
moveToHead(node);
return;
}
// 创建新节点
DLinkedNode newNode = new DLinkedNode();
newNode.key = key;
newNode.value = value;
// 将新节点加入缓存和链表头部
cache.put(key, newNode);
addNode(newNode);
++count;
// 如果缓存已满,移除链表尾部的节点(最久未使用的节点)
if(count > capacity){
DLinkedNode tail = popTail();
cache.remove(tail.key);
--count;
}
}
// 将节点添加到链表头部
private void addNode(DLinkedNode node){
node.pre = head;
node.post = head.post;
head.post.pre = node;
head.post = node;
}
// 从链表中移除节点
private void removeNode(DLinkedNode node){
DLinkedNode pre = node.pre;
DLinkedNode post = node.post;
pre.post = post;
post.pre = pre;
}
// 将节点移动到链表头部
private void moveToHead(DLinkedNode node){
removeNode(node);
addNode(node);
}
// 移除链表尾部的节点并返回该节点
private DLinkedNode popTail(){
DLinkedNode res = tail.pre;
removeNode(res);
return res;
}
}
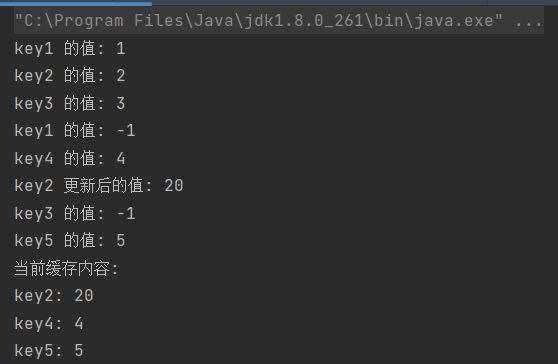
测试LRUCache
package LRU;
public class LRUCacheTest {
public static void main(String[] args) {
// 创建一个容量为 3 的 LRU 缓存
LRUCache cache = new LRUCache(3);
// 插入键值对
cache.put("key1", 1);
cache.put("key2", 2);
cache.put("key3", 3);
// 测试获取操作
System.out.println("key1 的值: " + cache.get("key1")); // 应返回 1
System.out.println("key2 的值: " + cache.get("key2")); // 应返回 2
System.out.println("key3 的值: " + cache.get("key3")); // 应返回 3
// 插入新键值对,触发淘汰策略(key1 是最久未使用的,应被淘汰)
cache.put("key4", 4);
// 测试淘汰策略
System.out.println("key1 的值: " + cache.get("key1")); // 应返回 -1,因为 key1 已被淘汰
System.out.println("key4 的值: " + cache.get("key4")); // 应返回 4
// 更新现有键的值,并测试是否移动到链表头部
cache.put("key2", 20);
System.out.println("key2 更新后的值: " + cache.get("key2")); // 应返回 20
// 插入新键值对,触发淘汰策略(key3 是最久未使用的,应被淘汰)
cache.put("key5", 5);
// 测试淘汰策略
System.out.println("key3 的值: " + cache.get("key3")); // 应返回 -1,因为 key3 已被淘汰
System.out.println("key5 的值: " + cache.get("key5")); // 应返回 5
// 打印当前缓存中的所有键值对
System.out.println("当前缓存内容:");
System.out.println("key2: " + cache.get("key2")); // 应返回 20
System.out.println("key4: " + cache.get("key4")); // 应返回 4
System.out.println("key5: " + cache.get("key5")); // 应返回 5
}
}
输出结果:
Redis中的LRU的实现
Redis 的 LRU 实现与传统的 LRU 算法有所不同。由于 Redis 是一个高性能的内存数据库,完全实现标准的 LRU 算法会带来较大的性能开销。因此,Redis 采用了一种 近似 LRU(Approximated LRU) 算法,在保证性能的同时,尽可能接近标准的 LRU 行为。
LRU时钟
Redis 为每个对象(键值对)维护一个 lru 字段,用于记录该对象最后一次被访问的时间戳。这个时间戳是一个 24 位的整数,表示从 Redis 启动开始计算的秒数的低 24 位。
- LRU 时钟的更新:
- 每次访问一个键时(例如
GET或SET),Redis 会更新该键的lru字段为当前的 LRU 时钟值。 - LRU 时钟的值会定期更新(默认每 100 毫秒更新一次)。
- 每次访问一个键时(例如
淘汰策略
当 Redis 需要淘汰键时(例如内存不足时),会根据配置的淘汰策略选择一个键进行删除。Redis 支持多种淘汰策略,其中与 LRU 相关的策略包括:
volatile-lru:从设置了过期时间的键中,淘汰最近最少使用的键。allkeys-lru:从所有键中,淘汰最近最少使用的键。
近似LRU的实现
Redis 并不完全遍历所有键来找到最久未使用的键,而是通过以下方式近似实现 LRU:
- 随机采样:Redis 会随机选择一定数量的键(默认是 5 个),然后从这些键中淘汰
lru值最小的键(即最久未使用的键)。 - 采样数量:可以通过配置
maxmemory-samples参数来调整采样数量。采样数量越多,淘汰的精度越高,但性能开销也越大。
LRU算法的优化
为了进一步优化性能,Redis 做了一些额外的优化:
- 惰性删除:Redis 不会在每次访问时都更新
lru字段,而是通过一些启发式方法减少更新频率。 - 淘汰池:Redis 维护一个淘汰池(eviction pool),用于缓存一些候选键,避免每次淘汰时都需要重新采样。
Redis LRU的核心代码逻辑
以下是 Redis 中 LRU 实现的核心逻辑(伪代码):
// 更新键的 LRU 时间戳
void updateLRU(redisObject *obj) {
obj->lru = getCurrentLRUClock();
}
// 获取当前的 LRU 时钟
unsigned int getCurrentLRUClock() {
return (server.unixtime & LRU_CLOCK_MAX) | (server.lruclock & ~LRU_CLOCK_MAX);
}
// 近似 LRU 淘汰算法
void evictKeysUsingLRU() {
int sample_count = server.maxmemory_samples;
redisObject *best_key = NULL;
unsigned int best_lru = LRU_CLOCK_MAX;
// 随机采样
for (int i = 0; i < sample_count; i++) {
redisObject *key = getRandomKey();
if (key->lru < best_lru) {
best_key = key;
best_lru = key->lru;
}
}
// 淘汰最久未使用的键
if (best_key != NULL) {
deleteKey(best_key);
}
}
Redis LRU的核心代码逻辑
以下是 Redis 中 LRU 实现的核心逻辑(伪代码):
// 更新键的 LRU 时间戳
void updateLRU(redisObject *obj) {
obj->lru = getCurrentLRUClock();
}
// 获取当前的 LRU 时钟
unsigned int getCurrentLRUClock() {
return (server.unixtime & LRU_CLOCK_MAX) | (server.lruclock & ~LRU_CLOCK_MAX);
}
// 近似 LRU 淘汰算法
void evictKeysUsingLRU() {
int sample_count = server.maxmemory_samples;
redisObject *best_key = NULL;
unsigned int best_lru = LRU_CLOCK_MAX;
// 随机采样
for (int i = 0; i < sample_count; i++) {
redisObject *key = getRandomKey();
if (key->lru < best_lru) {
best_key = key;
best_lru = key->lru;
}
}
// 淘汰最久未使用的键
if (best_key != NULL) {
deleteKey(best_key);
}
}
Redis LRU的配置参数
maxmemory:- 设置 Redis 实例的最大内存限制。
- 当内存使用达到该限制时,Redis 会根据淘汰策略删除键。
maxmemory-policy:- 设置淘汰策略,支持以下选项:
volatile-lru:从设置了过期时间的键中淘汰最近最少使用的键。allkeys-lru:从所有键中淘汰最近最少使用的键。volatile-random:从设置了过期时间的键中随机淘汰键。allkeys-random:从所有键中随机淘汰键。volatile-ttl:从设置了过期时间的键中淘汰剩余生存时间(TTL)最短的键。noeviction:不淘汰任何键,直接返回错误。
- 设置淘汰策略,支持以下选项:
maxmemory-samples:- 设置 LRU 淘汰时的采样数量。
- 默认值为 5,表示每次淘汰时随机选择 5 个键,然后淘汰其中最久未使用的键。
- 增加该值可以提高淘汰的精度,但会增加 CPU 开销。
Redis LRU的优缺点
优点:
- 高性能:
- 通过随机采样和近似算法,Redis 的 LRU 实现避免了完全遍历所有键的开销。
- 灵活性:
- 支持多种淘汰策略,可以根据业务需求灵活配置。
- 内存友好:
- 每个键只需要额外存储 24 位的
lru字段,内存开销较小。
- 每个键只需要额外存储 24 位的
缺点:
- 近似性:
- Redis 的 LRU 是近似的,可能无法完全准确地淘汰最久未使用的键。
- 采样数量影响精度:
- 采样数量较少时,淘汰的精度可能较低。
择 5 个键,然后淘汰其中最久未使用的键。 - 增加该值可以提高淘汰的精度,但会增加 CPU 开销。
- 采样数量较少时,淘汰的精度可能较低。
Redis LRU的优缺点
优点:
- 高性能:
- 通过随机采样和近似算法,Redis 的 LRU 实现避免了完全遍历所有键的开销。
- 灵活性:
- 支持多种淘汰策略,可以根据业务需求灵活配置。
- 内存友好:
- 每个键只需要额外存储 24 位的
lru字段,内存开销较小。
- 每个键只需要额外存储 24 位的
缺点:
- 近似性:
- Redis 的 LRU 是近似的,可能无法完全准确地淘汰最久未使用的键。
- 采样数量影响精度:
- 采样数量较少时,淘汰的精度可能较低。