分组汇总 with rollup和with cube和compute by 和排名函数
retmxls-- 商品销售明细表
rq--日期
spid--商品信息
sshje--每笔销售记录的金额
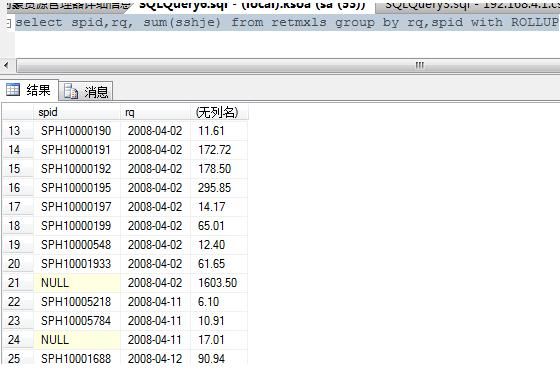
select spid,rq, sum(sshje) from retmxls group by rq,spid with ROLLUP order by spid
根据group by 后的第一个字段进行分组,我这里的是rq,那就是同日期的为一组,并在这一组完的最后一行插入一个空行,显示这个组的sshje 的汇总
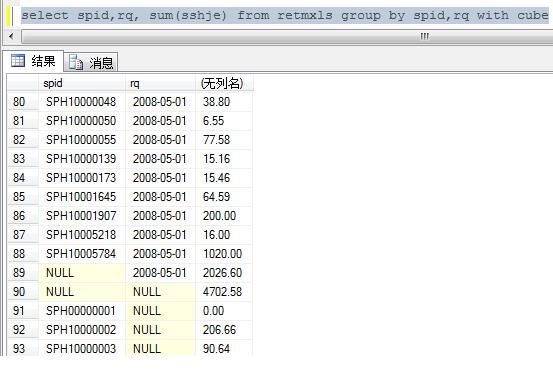
select spid,rq, sum(sshje) from retmxls group by spid,rq with cube order by spid
根据group by 后的每一个字段进行分组,并在这一组完的最后一行插入一个空行,显示这个组的sshje 的汇总
下图的结果中有2026.6这个是2005-05-01这个日期的所有商品的汇总额,而4702.58是整个表的所有商品所
有日期的总汇总,而206.66是SPH10000002在所有天的汇总。
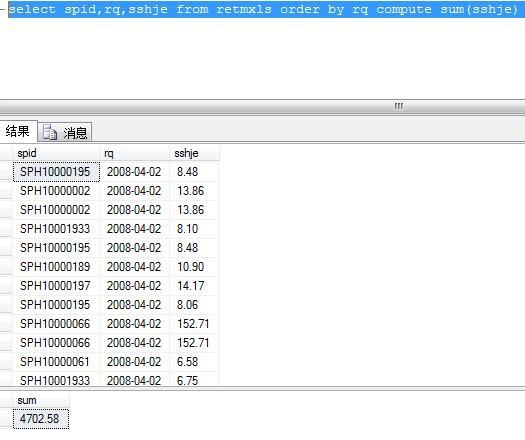
select spid,rq,sshje from retmxls order by rq compute sum(sshje)
对compute 后的sum字段进行汇总,返回明细和一个汇总两个结果
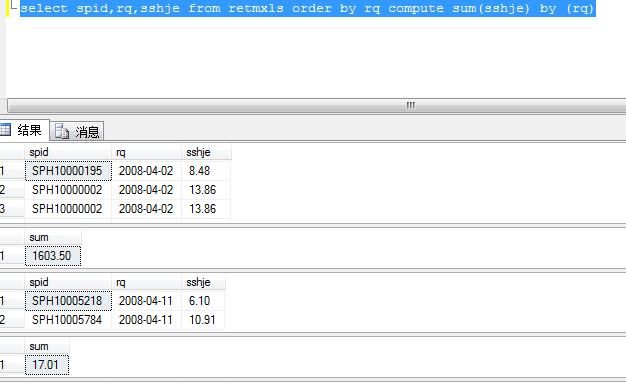
select spid,rq,sshje from retmxls order by rq compute sum(sshje) by (rq)
对compute 后的sum字段进行汇总,对by后的字段进行分组,返回由日期分组后的每个明细和每个汇总的多个结果
下面再说几个比较有用的排名函数(RANK ()、NTILE (integer_expression)、row_number() 、DENSE_RANK)
1、RANK ()
语法
RANK ( ) OVER ( [ < partition_by_clause > ] < order_by_clause > )
参数
< partition_by_clause>
将 FROM 子句生成的结果集划分成 RANK 函数适用的分区。若要了解 PARTITION BY 语法,请参阅 OVER 子句 (Transact-SQL)。
< order_by_clause>
确定将 RANK 值应用于分区中的行时所基于的顺序。有关详细信息,请参阅 ORDER BY 子句 (Transact-SQL)。当在排名函数中使用 <order_by_clause> 时,不能用整数表示列。
示列:select rank () over(PARTITION BY sshje order by spid) as r,spid,sshje from retmxls结果生成以sshje分区,按spid排序的序号,返回结果同一spid序号一样,下一序号从实际行号开始。而不是上一序号加1
也可以select rank () over(order by spid) as r,spid,sshje from retmxls
返回结果同一spid序号一样,下一序号从实际行号开始。而不是上一序号加1
2、NTILE (integer_expression)
语法
NTILE (integer_expression) OVER ( [ <partition_by_clause> ] < order_by_clause > )
参数
integer_expression
一个正整数常量表达式,用于指定每个分区必须被划分成的组数。
integer_expression 的类型可以为 int 或 bigint。
<partition_by_clause>
将 FROM 子句生成的结果集划分成 RANK 函数适用的分区。
< order_by_clause>
确定 NTILE 值分配到分区中各行的顺序。有关详细信息,请参阅 ORDER BY 子句 (Transact-SQL)。当在排名函数中使用 <order_by_clause> 时,不能用整数表示列。
示列:select NTILE (4) over(PARTITION BY sshje order by spid) as r,spid,sshje from retmxls
根据sshje进行分区,按照spid进行排序,把每个分区分成4份
也可以select NTILE (4) over(order by spid) as r,spid,sshje from retmxls
将整个结果分成四份
3、DENSE_RANK ( )
语法
| DENSE_RANK ( ) OVER ( [ < partition_by_clause > ] < order_by_clause > ) |
参数
< partition_by_clause>
将 FROM 子句生成的结果集划分为数个应用 DENSE_RANK 函数的分区。若要了解 PARTITION BY 语法,请参阅 OVER 子句 (Transact-SQL)。
< order_by_clause>
确定将 DENSE_RANK 值应用于分区中各行的顺序。整数不能表示排名函数中使用的 <order_by_clause> 中的列。
示列:select DENSE_RANK() over( order by spid) as r,spid,sshje from retmxls
返回结果同NTILE的区别是他的下一区的序号是上一区的数值加1而不是实际的行数。
select DENSE_RANK() over(PARTITION BY sshje order by spid) as r,spid,sshje from retmxls
生成结果根据sshje分区,spid排序,生成序号,序号是连续的顺序
4、row_number()
语法
| ROW_NUMBER ( ) OVER ( [ <partition_by_clause> ] <order_by_clause> ) |
参数
<partition_by_clause>
将 FROM 子句生成的结果集划入应用了 ROW_NUMBER 函数的分区。若要了解 PARTITION BY 语法,请参阅 OVER 子句 (Transact-SQL)。
<order_by_clause>
确定将 ROW_NUMBER 值分配给分区中的行的顺序。有关详细信息,请参阅 ORDER BY 子句 (Transact-SQL)。当在排名函数中使用 <order_by_clause> 时,不能用整数表示列。
示列:select row_number() over(order by spid) as r,spid,sshje from retmxls
生成结果,以spid排序,生成连续的序号。和标识种子类似
select row_number() over(PARTITION BY sshje order by spid) as r,spid,sshje from retmxls
生成以sshje分区的序号,每个分区从1开始