YOLOv8n-OBB使用C#在windows10进行部署(CPU)
1. 训练YOLOv8-OBB模型
1.1 数据集制作
所用标注工具:X-AnyLabeling
下载链接:https://github.com/CVHub520/X-AnyLabeling/releases/download/v2.3.6/X-AnyLabeling-CPU.exe
附上两张图片为标注过程中的重要步骤;
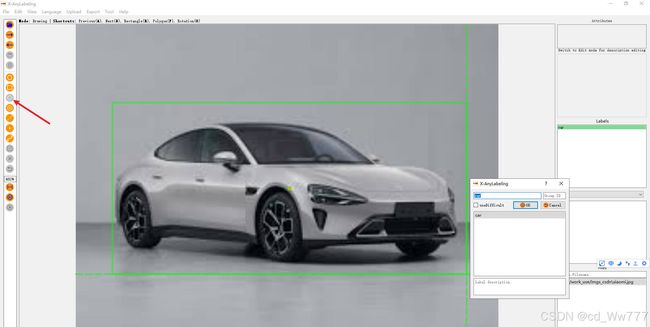
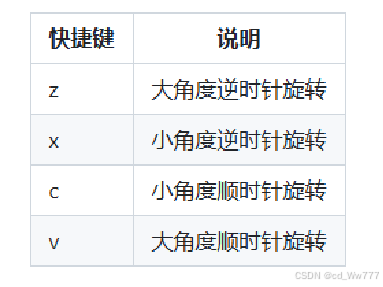
标注快捷键的使用具体参考官方文档,附图为简单实用的快捷键。https://github.com/CVHub520/X-AnyLabeling/blob/main/docs/zh_cn/user_guide.md
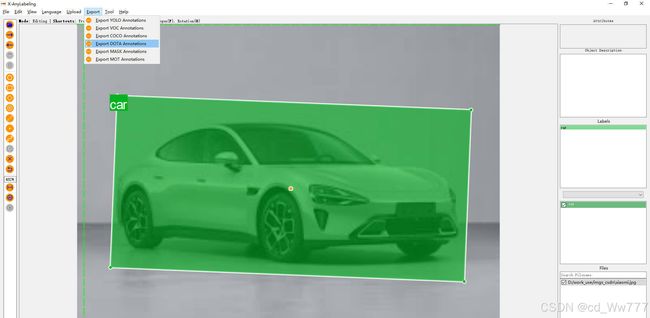
1.2 数据格式转换
使用X-AnyLabeling标注完成后,选择导出DOTA格式的txt文件,具体如图所示:
进行数据集预处理前,需要安装anaconda创建管理虚拟环境,并且需要安装一些预处理过程中需要安装的工具包。数据集划分的代码如下:
from tqdm import tqdm
import shutil
import os
from sklearn.model_selection import train_test_split
def CollateDataset(image_dir,label_dir,val_size = 0.1,random_state=42): # image_dir:图片路径 DOTA label_dir:标签路径
if not os.path.exists("./YOLODataset"):
os.makedirs("./YOLODataset")
images = []
labels = []
for image_name in os.listdir(image_dir):
image_path = os.path.join(image_dir, image_name)
ext = os.path.splitext(image_name)[-1]
label_name = image_name.replace(ext, ".txt")
label_path = os.path.join(label_dir, label_name)
if not os.path.exists(label_path):
print("there is no:", label_path)
else:
images.append(image_path)
labels.append(label_path)
train_data, test_data, train_labels, test_labels = train_test_split(images, labels, test_size=val_size, random_state=random_state)
destination_images = "./YOLODataset/images"
destination_labels = "./YOLODataset/labels"
os.makedirs(os.path.join(destination_images, "train"), exist_ok=True)
os.makedirs(os.path.join(destination_images, "val"), exist_ok=True)
os.makedirs(os.path.join(destination_labels, "train_original"), exist_ok=True)
os.makedirs(os.path.join(destination_labels, "val_original"), exist_ok=True)
# 遍历每个有效图片路径
for i in tqdm(range(len(train_data))):
image_path = train_data[i]
label_path = train_labels[i]
image_destination_path = os.path.join(destination_images, "train", os.path.basename(image_path))
shutil.copy(image_path, image_destination_path)
label_destination_path = os.path.join(destination_labels, "train_original", os.path.basename(label_path))
shutil.copy(label_path, label_destination_path)
for i in tqdm(range(len(test_data))):
image_path = test_data[i]
label_path = test_labels[i]
image_destination_path = os.path.join(destination_images, "val", os.path.basename(image_path))
shutil.copy(image_path, image_destination_path)
label_destination_path = os.path.join(destination_labels, "val_original", os.path.basename(label_path))
shutil.copy(label_path, label_destination_path)
if __name__ == '__main__':
CollateDataset(r"D:\work_use\dataset",r"D:\work_use\labelTxt")DOTA数据格式转换为YOLO-OBB格式的脚本为:
from pathlib import Path
from ultralytics.utils import TQDM
import cv2
import os
def convert_dota_to_yolo_obb(dota_root_path: str,class_mapping:dict):
"""
Converts DOTA dataset annotations to YOLO OBB (Oriented Bounding Box) format.
The function processes images in the 'train' and 'val' folders of the DOTA dataset. For each image, it reads the
associated label from the original labels directory and writes new labels in YOLO OBB format to a new directory.
Args:
dota_root_path (str): The root directory path of the DOTA dataset.
Notes:
The directory structure assumed for the DOTA dataset:
- DOTA
├─ images
│ ├─ train
│ └─ val
└─ labels
├─ train_original
└─ val_original
After execution, the function will organize the labels into:
- DOTA
└─ labels
├─ train
└─ val
"""
dota_root_path = Path(dota_root_path)
class_mapping = class_mapping
def convert_label(image_name, image_width, image_height, orig_label_dir, save_dir):
"""Converts a single image's DOTA annotation to YOLO OBB format and saves it to a specified directory."""
orig_label_path = orig_label_dir / f"{image_name}.txt"
save_path = save_dir / f"{image_name}.txt"
with orig_label_path.open("r") as f, save_path.open("w") as g:
lines = f.readlines()
for line in lines:
parts = line.strip().split()
if len(parts) < 9:
continue
class_name = parts[8]
class_idx = class_mapping[class_name]
coords = [float(p) for p in parts