【AI论文】RWKV-7“鹅”模型,具备富有表现力的动态状态演化能力
摘要:我们推出RWKV-7“鹅”,这是一种全新的序列建模架构,同时发布的还有预训练语言模型。在多语言任务中,这些模型在30亿参数规模下实现了下游性能的全新最优水平,并且在英语语言性能上,尽管训练所用的标记数量远少于其他顶尖30亿参数模型,但仍能与当前最优水平相媲美。然而,RWKV-7模型仅需常量内存使用和每个标记的常量推理时间。RWKV-7引入了一种新泛化的delta规则,该规则具有向量值门控和上下文学习率,以及一种放宽的值替换规则。我们表明,RWKV-7能够进行状态跟踪并识别所有正规语言,同时保持训练的并行性。这超出了标准复杂度猜想下Transformer的能力范围,因为Transformer受限于TC^0。为了展示RWKV-7的语言建模能力,我们还推出了一个扩展的开源3.1万亿标记多语言语料库,并在此数据集上训练了四个参数范围从1.9亿到29亿的RWKV-7模型。为促进开放性、可重复性和采用,我们在https://huggingface.co/RWKV 上发布了我们的模型和数据集组件列表,并在https://github.com/RWKV/RWKV-LM上发布了我们的训练和推理代码,所有这些均遵循Apache2.0许可证。Huggingface链接:Paper page,论文链接:2503.14456
研究背景和目的
研究背景
近年来,自注意力机制(Self-Attention Mechanism)在序列建模任务中取得了显著的成功,尤其是在自然语言处理(NLP)领域。以Transformer为代表的模型通过自注意力机制实现了卓越的在上下文处理和高度并行化训练能力。然而,自注意力机制在计算复杂度和内存使用上随着序列长度的增加呈二次增长,这限制了其在处理长序列任务中的应用。为了解决这一问题,研究者们开始探索具有压缩状态的循环神经网络(RNN)架构,这些架构能够在保持线性计算复杂度和常量内存使用的同时,仍然允许高效的并行训练。
线性注意力(Linear Attention)变体和状态空间模型(State Space Models, SSMs)是两种最常见的满足这些要求的替代方案。尽管这些架构已经取得了显著的进展,但仍存在一些问题,如状态信息的累积和混合,以及缺乏有效的位置编码等。为了解决这些问题,研究者们提出了DeltaNet等模型,通过部分替换状态中的值来模拟在线学习过程,从而提高了模型的表达能力和训练稳定性。
研究目的
本文旨在提出一种新的RNN架构——RWKV-7“Goose”,该架构通过泛化delta规则,引入向量值门控和上下文学习率,以及放宽的值替换规则,显著提高了模型的表达能力和训练效率。RWKV-7旨在解决线性注意力架构中存在的问题,同时保持其线性计算复杂度和常量内存使用的优势。此外,本文还旨在通过训练一系列RWKV-7模型,在多语言任务和英语语言任务上展示其卓越的性能,并与当前最优水平的Transformer模型进行比较。
研究方法
RWKV-7架构设计
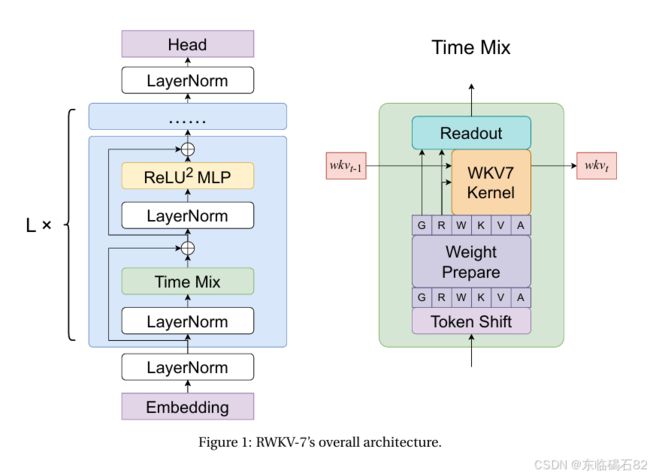
RWKV-7通过泛化delta规则,引入了一种新的状态更新机制。该机制包括向量值衰减、上下文学习率和放宽的值替换规则。具体来说,RWKV-7的状态更新公式为:
wkvt=wkvt−1(diag(wt)−κ^tT(at⊙κ^t))+vtTk~t
其中,wt是向量值衰减,κ^t是归一化的移除键,at是上下文学习率,k~t是替换键,vt是值。这些参数都是通过低秩多层感知机(MLP)动态计算的,以确保模型的高效性和灵活性。
RWKV-7还引入了一种新的奖励机制,通过额外的接收门(receptance gate)和值残差学习(value residual learning)来增强模型的表达能力。此外,RWKV-7还通过解耦移除键和替换键,以及引入向量值门控,进一步提高了模型的灵活性和稳定性。
训练与评估
为了评估RWKV-7的性能,本文在多语言基准测试、英语语言基准测试、联想记忆测试、机制设计基准测试、长上下文实验以及通过组乘法评估状态跟踪能力等方面进行了广泛的实验。具体来说,本文使用了LM Evaluation Harness、MMLU、ARC、GLUE、Winogrande、SciQ等基准测试,以及自定义的联想记忆测试和机制设计基准测试。
在训练过程中,本文使用了RWKV World v3语料库,这是一个包含3.1万亿标记的多语言语料库,旨在提供与现代大型语言模型训练所用数据量相当的数据集。为了训练RWKV-7模型,本文采用了AdamW优化器,并使用了余弦学习率衰减策略和动态批量大小缩放策略。
研究结果
多语言与英语语言基准测试
在多语言基准测试中,RWKV-7模型在MMLU、ARC、GLUE等基准测试上取得了显著优于其他模型的成绩。特别地,RWKV-7-World-3-2.9B模型在MMLU基准测试上取得了71.5的平均准确率,显著优于其他模型。在英语语言基准测试中,RWKV-7模型在LAMBADA、Hellaswag、PIQA等基准测试上也取得了与当前最优水平相当的成绩,尽管其训练所用的标记数量远少于其他顶尖模型。
联想记忆测试
在联想记忆测试中,RWKV-7模型展现出了强大的记忆和复制能力。特别是在MQAR测试中,RWKV-7模型在256个键值对设置下取得了72.93%的召回率,表明其能够在有限的状态维度内有效地存储和检索信息。
机制设计基准测试
在机制设计基准测试中,RWKV-7模型在六个任务上取得了平均98.8的最高分数,显著优于其他模型。这表明RWKV-7模型在处理需要复杂状态跟踪和记忆能力的任务时具有显著优势。
长上下文实验
在长上下文实验中,RWKV-7模型展现出了出色的长上下文处理能力。特别地,RWKV-7-World-3-2.9B模型在处理长达35000个标记的上下文时仍能保持较高的准确率,这表明其能够有效地处理和利用长上下文信息。
状态跟踪能力评估
通过组乘法评估状态跟踪能力,本文发现RWKV-7模型在识别正规语言方面展现出了强大的能力。特别地,RWKV-7模型能够使用恒定数量的层来识别任何正规语言,这超出了标准复杂度猜想下Transformer的能力范围。
研究局限
尽管RWKV-7模型在多个基准测试上取得了显著优于其他模型的成绩,但仍存在一些局限性。首先,RWKV-7模型对数值精度较为敏感,这可能导致在实际部署时需要注意数值稳定性的问题。其次,RWKV-7模型尚未进行指令调优和对齐训练,这限制了其在现实世界应用中的可用性。此外,RWKV-7模型对特殊标记的敏感性也可能影响其在实际应用中的性能。最后,由于计算资源的限制,本文的训练过程受限于最多使用96个Nvidia H800 GPU,这可能限制了RWKV-7模型的潜力。
未来研究方向
针对RWKV-7模型的局限性,未来研究可以从以下几个方面进行改进和拓展:
-
优化数值稳定性:通过改进RWKV-7模型的数值计算方法和优化算法,提高其在实际部署时的数值稳定性。
-
指令调优和对齐训练:对RWKV-7模型进行指令调优和对齐训练,以提高其在现实世界应用中的可用性和性能。
-
降低对特殊标记的敏感性:通过改进RWKV-7模型的架构和训练方法,降低其对特殊标记的敏感性,提高其在实际应用中的鲁棒性。
-
扩展模型规模和数据集:利用更多的计算资源来训练更大规模的RWKV-7模型,并使用更大的数据集来提高其性能和泛化能力。
-
探索新的应用场景:将RWKV-7模型应用于更多的序列建模任务中,如文本生成、图像理解、语音识别等,以进一步验证其有效性和泛化能力。
-
集成链式思考推理能力:通过集成链式思考推理能力,使RWKV-7模型在处理需要多步逻辑推理和复杂问题解决的任务时表现出色。
-
优化训练和推理速度:通过探索新的速度优化技术,如管道并行、混合专家、多标记预测和低精度训练等,进一步提高RWKV-7模型的训练和推理速度。