python数据处理之pandas.read_csv()用法详解
1.读取CSV数据:
def read_csv(
filepath_or_buffer: FilePathOrBuffer,
sep=lib.no_default,
delimiter=None,
# Column and Index Locations and Names
header="infer",
names=None,
index_col=None,
usecols=None,
squeeze=False,
prefix=None,
mangle_dupe_cols=True,
# General Parsing Configuration
dtype=None,
engine=None,
converters=None,
true_values=None,
false_values=None,
skipinitialspace=False,
skiprows=None,
skipfooter=0,
nrows=None,
# NA and Missing Data Handling
na_values=None,
keep_default_na=True,
na_filter=True,
verbose=False,
skip_blank_lines=True,
# Datetime Handling
parse_dates=False,
infer_datetime_format=False,
keep_date_col=False,
date_parser=None,
dayfirst=False,
cache_dates=True,
# Iteration
iterator=False,
chunksize=None,
# Quoting, Compression, and File Format
compression="infer",
thousands=None,
decimal: str = ".",
lineterminator=None,
quotechar='"',
quoting=csv.QUOTE_MINIMAL,
doublequote=True,
escapechar=None,
comment=None,
encoding=None,
dialect=None,
# Error Handling
error_bad_lines=True,
warn_bad_lines=True,
# Internal
delim_whitespace=False,
low_memory=_c_parser_defaults["low_memory"],
memory_map=False,
float_precision=None,
storage_options: StorageOptions = None,
)| 参数名称 | 说明 |
| filepath | 接收string。代表文件路径,无默认设置 |
| sep | 接收string。代表分隔符,默认为‘,’ |
| header | 接收int或者sequence。表示将某行数据作为列名称,默认为infer,表示自动识别 |
| names | 接收array。表示列名,默认为None |
| index_col | 接收int,sequence或False.表示索引列表的位置,取值为sequence表示多重索引,默认为None |
| dtype | 接收dict.代表写入数据类型,列名为key,数据格式为values,默认为None |
| engine | 接收c或者python,代表数据解析引擎,默认为C |
| encoding | 接收string。表示文件的编码方式,常用的有utf-8,utf-16,gbk,gb2312,gb18030等等 |
import pandas as pd
# sep表示数据之间的分隔符,如果不指定,则默认为‘,’
data=pd.rean_csv(path,sep=' ')读取某一CSV文件,但是可以看到其列名称是乱码,这是因为列名称是中文的,为现在的解码方式不能解析中文,所以我们需要修改一下encoding参数设置。
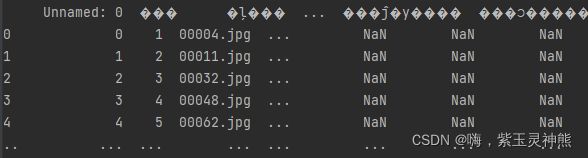
设置如下:
data=pd.read_csv(path,sep=' ',encoding='gb2312')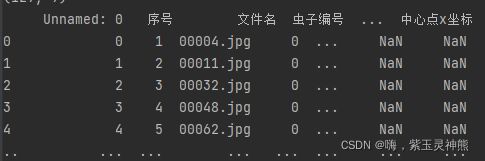
然后可以将读取的CSV数据转换为numpy数据,就可以像数组一样读取了。
data1=np.array(data)2.将数据存储为CSV文件:
def to_csv(
self,
path_or_buf: Optional[FilePathOrBuffer] = None,
sep: str = ",",
na_rep: str = "",
float_format: Optional[str] = None,
columns: Optional[Sequence[Label]] = None,
header: Union[bool_t, List[str]] = True,
index: bool_t = True,
index_label: Optional[IndexLabel] = None,
mode: str = "w",
encoding: Optional[str] = None,
compression: CompressionOptions = "infer",
quoting: Optional[int] = None,
quotechar: str = '"',
line_terminator: Optional[str] = None,
chunksize: Optional[int] = None,
date_format: Optional[str] = None,
doublequote: bool_t = True,
escapechar: Optional[str] = None,
decimal: str = ".",
errors: str = "strict",
storage_options: StorageOptions = None,
)| 参数名称 | 说明 |
| path_or_buf | 接收string。表示文件的存储位置,无默认 |
| sep | 接收string。表示存储数据之间的分隔符,默认为‘,’ |
| index | 接收bool。表示是否将行名称写出,默认为True |
| mode | 接收特定的string。表示数据写入模式,默认为w |
| na_rep | 接收string。表示缺失值,默认为‘ ’ |
| columns | 接收list。表示写出的列名,默认为None |
| header | 接收bool。表示是否将列名写出 |
| encoding | 接收特定string。表示数据存储的编码格式。 |
DataFrame.to_csv(path)在CSV文件中新增一列并保存:
# 假设data为一个CSV数据,我们需要在这个数据的最后新增一列数据
# 新增的数据长度要与data的长度相同
list=[0,1,2,3,4,5,6]
# 新增到data上,sorce为新增列的名称
data['sorce']=list
# 保存,不保存列的编号,编码方式为gbk
data.to_csv(path ,encoding='gbk',index=False)