使用 AMD GPU 加速推理的投机采样
Speed Up Text Generation with Speculative Sampling on AMD GPUs — ROCm Blogs
随着变压器模型的规模增长,进行推理的成本也在增加,影响了延迟和吞吐量。量化和蒸馏等压缩方法,以及诸如闪存注意力和Triton等硬件优化,已被提出在不同层面上减少计算成本。然而,这些方法要么在准确性上有所妥协,要么需要对模型实现进行重大改动。
投机采样是一种加速推理的技术(在70B Chinchilla模型上可以提高2-2.5倍的速度),既不改变数学准确性,也不改变模型配置或训练。此外,它可以与上述优化策略结合使用,进一步减少文本生成的延迟。在这篇博客文章中,我们将简要介绍投机采样、基于草稿模型和目标模型的算法方法,以及其在使用ROCm的AMD GPU上的实现。
了解推测采样
推测采样技术在DeepMind的论文Accelerating Large Language Model Decoding with Speculative Sampling和Google Research的论文Fast Inference from Transformers via Speculative Decoding中首次提出。尽管两者略有不同,但它们都提出了类似的策略来减少大型语言模型的推断成本。
在高层次上,推测采样采用辅助生成的方法,使用一个小型的草稿模型来生成接下来的`k`个token,并使用一个大型的目标模型来验证这些生成的token。使用这种方法生成和验证token所需的总时间低于仅使用大型目标模型生成token的时间。
使用草稿模型的基本原理是,大多数“下一个token”的预测是简单而显而易见的。例如,它们可能是常见的短语或预期的代词。想象一下,使用一个具有数十亿参数的模型的前向传递仅仅是为了生成一个逗号作为下一个token!一个较小版本的模型能做到吗?在大多数情况下,它可以。
此外,大多数变压器模型中的计算更依赖于内存带宽,而不是计算能力。随着参数数量的增加,矩阵乘法器和大型KV缓存的内存带宽使用率也会增加,因此有必要减小模型的大小,从而减少延迟。
此外,推测采样并行地对K个token进行评分和验证,这相较于传统自回归方法提高了速度。
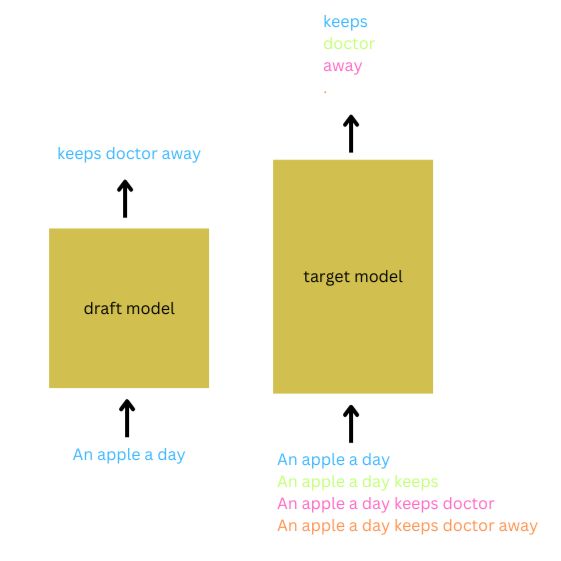
为了说明推测采样,考虑输入提示“An apple a day”。设置K=3,草稿模型自回归地推测接下来的3个token将是“keeps doctor away”。目标模型将输入提示与预测token的不同延续进行批处理以验证这些预测。当满足验证标准时,并且草稿模型的分布与目标模型的分布在所有三个token上都非常接近,则接受这三个token的预测。除了接受前`K`个token的预测外,还接受目标模型对`(K+1)`个token的预测。在这种情况下,`K+1`个token在大型模型的单次前向传递和草稿模型的`K`次前向传递中生成,从而大大减少了延迟。这个过程将重复进行,直到达到所需序列长度。
自然地,我们好奇如果任何预测的token未通过验证会发生什么。为了解决这一问题,作者提出了一种`修改后的拒绝采样`策略。验证策略如算法2所述,通过计算目标模型预测该token的概率的比率,即`q(x_n+1|x_1,...,x_n)`,与草稿模型预测该token的概率,即`p(x_n+1|x_1,...,x_n)`。如果这个比率高于指定的阈值,则接受该token。如果该比率低于此阈值,则拒绝该token,并从基于这两个概率`q()-p()`差异的新分布中重新采样。

图片来源于Chen等人的推测采样论文
使用草稿模型进行预测已被证明能够产生与使用目标模型进行预测的数学等效结果。但是,选择与目标模型高度一致的草稿模型非常重要。选择目标模型的较小版本作为草稿模型可以实现最低的延迟。
需求
本博客中概述的推测采样示例使用了以下硬件和软件:
-
AMD GPU: 请在ROCm文档页面上查看支持的操作系统和硬件列表。
-
ROCm 6.1.2: 请参考ROCm安装说明。
-
PyTorch 2.1.2: 我们将使用官方的ROCm Docker镜像rocm6.1.2_ubuntu20.04_py3.9_pytorch_release-2.1.2。您可以运行以下docker命令来启动一个基于ROCm的pytorch会话。将`/YOUR/FOLDER`替换为您的本地文件位置。
docker run -it --rm --device=/dev/kfd --device=/dev/dri --group-add=video --shm-size 8G -v /YOUR/FODLER:/root rocm/pytorch:rocm6.1.2_ubuntu20.04_py3.9_pytorch_release-2.1.2
-
安装 Hugging Face 库
pip install transformers datasets accelerate
代码
在本节中,您将使用通过投机采样加速大型语言模型解码中概述的算法来实现投机采样。
您将使用EleutherAI/gpt-neo-1.3B模型作为草稿模型,EleutherAI/gpt-neox-20B模型作为目标模型。EleutherAI/gpt-neo-1.3B拥有13亿个参数,而EleutherAI/gpt-neox-20B拥有200亿个参数。由EleutherAI社区开发的GPT Neo系列模型是GPT-3的开源替代品。在本文中,将使用N=30和K=4的GPT Neo系列模型来生成文本。
这里使用的代码可以在 the Jupyter Notebook located in this blog’s src directory中找到。
首先使用目标模型基准测试`N=50`个token的自回归采样。预测50个token的字符串所需的总时间约为3.85秒。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
torch.manual_seed(0)
import torch.nn.functional as F
import time
import numpy as np
np.random.seed(30)
draft_model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-neo-1.3B", device_map='auto',torch_dtype=torch.float16)
draft_tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-neox-20b", device_map='auto',torch_dtype=torch.float16)
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neox-20b")
model.device.type=='cuda', draft_model.device.type=='cuda'
prompt = "Difference between a gasoline and hybrid vehicles is"
K=4
N=50
############## 自回归采样测试 ##############
inputs = tokenizer(prompt, return_tensors="pt")
inp = inputs['input_ids'].to('cuda')
start = time.time()
while(inp.shape[-1]
Time taken is 3.85893177986145s
Now benchmark this blog’s implementation of Speculative Sampling using the same pair of models. You can uncomment the debug statements in the code to observe the tokens accepted at every iteration.
############## 投机采样测试 ##############
inputs = draft_tokenizer(prompt, return_tensors="pt")
inp = inputs['input_ids'].to('cuda')
print(inp)
start = time.time()
while(inp.shape[-1]0,1,0))
target_output.logits = torch.softmax(target_output.logits,-1)
########## 打印目标模型的序列化输出 #########################
# out = torch.argmax(target_output.logits,-1)
# out_decode = [tokenizer.decode(out[i][first_tok_idx+i-1]) for i in range(K+1)]
# print('Target output: ',out_decode)
all_accepted=True
inp = global_inp[0] #为下一次投机采样准备草稿模型输入
for i in range(K):
print(f'K: {first_tok_idx+i-1}')
token_idx, prob_d = global_o[i] #来自草稿模型的token索引和概率
# 来自目标模型的相同token的概率
prob_t = target_output.logits[i,first_tok_idx+i-1,tokenizer(draft_tokenizer.decode(token_idx)).input_ids[0]]
# 接受的token
if np.random.random() < min(1,prob_t/prob_d):
# if prob_t/prob_d>=1:
# print(f'Accepted {first_tok_idx+i-1} token: ', draft_tokenizer.decode(token_idx), token_idx)
inp = torch.cat((inp,torch.tensor([token_idx],device='cuda')))
# Modified Rejected token
else:
token_idx = torch.argmax(target_output.logits[i][first_tok_idx+i-1])
# print(f'Replaced {first_tok_idx+i-1} token: ', tokenizer.decode(token_idx), token_idx)
draft_token_idx = draft_tokenizer([tokenizer.decode(token_idx)]).input_ids[0]
inp = torch.cat((inp,torch.tensor(draft_token_idx,device='cuda')))
all_accepted = False
break
if inp.shape[-1]==N-1:
print(inp.shape)
break
# 如果全部接受则添加额外的目标模型预测token
if all_accepted:
#print('All tokens are accepted, adding extra token')
token_idx = torch.argmax(target_output.logits[-1,first_tok_idx+K-1])
draft_token_idx = draft_tokenizer([tokenizer.decode(token_idx)]).input_ids[0]
prob_t = torch.tensor(draft_token_idx,device='cuda')
inp = torch.cat((inp,prob_t))
print(f'After verification: {draft_tokenizer.decode(inp)}\n')
inp = inp.unsqueeze(0) #batched input
end = time.time()
print(f'Time taken is {end-start}s')
在下面的输出中,我们展示了每次迭代后的Speculative Sampling(推测采样)的验证输出,以及验证过程中接受的token索引。在大多数迭代中,目标模型接受了3-4个token,证明了Speculative Sampling在减少延迟方面的有效性。总用时大约2.849秒(请注意,由于PyTorch函数中固有的伪随机性,这个基准测试不能精确复制),比起传统的自回归采样约快1.35倍。
K: 8
After verification: Difference between a gasoline and hybrid vehicles is that
K: 9
K: 10
K: 11
K: 12
After verification: Difference between a gasoline and hybrid vehicles is that the gasoline vehicle has
K: 13
K: 14
After verification: Difference between a gasoline and hybrid vehicles is that the gasoline vehicle has a fuel
K: 15
K: 16
After verification: Difference between a gasoline and hybrid vehicles is that the gasoline vehicle has a fuel tank that
K: 17
K: 18
K: 19
K: 20
After verification: Difference between a gasoline and hybrid vehicles is that the gasoline vehicle has a fuel tank that is filled with gasoline.
K: 22
K: 23
After verification: Difference between a gasoline and hybrid vehicles is that the gasoline vehicle has a fuel tank that is filled with gasoline. The hybrid
K: 24
K: 25
K: 26
K: 27
After verification: Difference between a gasoline and hybrid vehicles is that the gasoline vehicle has a fuel tank that is filled with gasoline. The hybrid vehicle has a fuel tank
K: 29
K: 30
K: 31
K: 32
After verification: Difference between a gasoline and hybrid vehicles is that the gasoline vehicle has a fuel tank that is filled with gasoline. The hybrid vehicle has a fuel tank that is filled with a
K: 34
K: 35
After verification: Difference between a gasoline and hybrid vehicles is that the gasoline vehicle has a fuel tank that is filled with gasoline. The hybrid vehicle has a fuel tank that is filled with a fuel that
K: 36
K: 37
After verification: Difference between a gasoline and hybrid vehicles is that the gasoline vehicle has a fuel tank that is filled with gasoline. The hybrid vehicle has a fuel tank that is filled with a fuel that is a
K: 38
K: 39
K: 40
K: 41
After verification: Difference between a gasoline and hybrid vehicles is that the gasoline vehicle has a fuel tank that is filled with gasoline. The hybrid vehicle has a fuel tank that is filled with a fuel that is a mixture of gasoline and electricity
K: 43
K: 44
K: 45
After verification: Difference between a gasoline and hybrid vehicles is that the gasoline vehicle has a fuel tank that is filled with gasoline. The hybrid vehicle has a fuel tank that is filled with a fuel that is a mixture of gasoline and electricity. The electricity
K: 46
K: 47
torch.Size([49])
After verification: Difference between a gasoline and hybrid vehicles is that the gasoline vehicle has a fuel tank that is filled with gasoline. The hybrid vehicle has a fuel tank that is filled with a fuel that is a mixture of gasoline and electricity. The electricity is generated battery
Time taken is 2.8490023612976074s
使用单个AMD GPU,Speculative Sampling在生成50个token的时间上比自回归采样快了1.35倍。你可以选择用其他现有的模型,比如Google的Gemma(9B & 27B)、Meta的Llama(7B & 70B)、Mistral的模型,来分析文本生成的加速效果。
这篇博客中实现的Speculative Sampling仅用于演示目的,并未优化用于性能分析。对于相同的提示,自动回归采样和Speculative Sampling的输出可能不完全相同,如以上两次实验所示。这是由于两种策略中伪随机种子的不同处理导致的不同数值。然而,该算法保证解码的tokens来自相同的分布。
总结
在这篇博客文章中,我们简要介绍了一种辅助文本生成的方法,称为Speculative Sampling(推测采样)。我们解释了推测采样的基本原理,以及如何使用来自同一模型系列的两个模型,通过在确保数学准确性的前提下,不改变训练架构或实现方式,加速生成推理大约2倍。然后,我们演示了如何利用AMD硬件和ROCm的强大功能,实现对一系列模型的推测采样。