强化学习原理:基本概念
脉络图
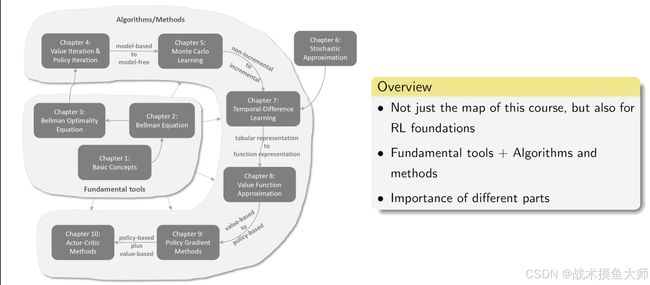
图片来自西湖大学赵世钰老师课程截图
理论基础
Basic Concepts
被训练的目标被称为agent,agent的所有可能的状态组合形成状态空间 S = { s i } S = \left \{ s_i \right \} S={si},处于每个状态时所能执行的行动称为action,每个状态对应的action构成一个action space: A ( s i ) = { a i } A(s_i) = \left \{ a_i \right \} A(si)={ai},从一个状态经过一个action到达另一个状态,称为状态转移 s 1 → a 2 s 2 s_1 \overset{a_2}{\rightarrow} s_2 s1→a2s2,
感觉有点像有限状态机模型
对于行为具有固定结果状态的情况,可以将action和state列出来,形成一个表格:
| a 1 a_1 a1 | a 2 a_2 a2 | |
|---|---|---|
| s 1 s_1 s1 | s 1 s_1 s1 | s 2 s_2 s2 |
| s 2 s_2 s2 | s 2 s_2 s2 | s 1 s_1 s1 |
更一般化,可以以概率的形式表达 p ( s 2 ∣ s 1 , a 2 ) = 0.5 , p ( s 1 ∣ s 1 , a 2 ) = 0.5 p(s_2 | s_1,a_2) = 0.5,p(s_1 | s_1,a_2) = 0.5 p(s2∣s1,a2)=0.5,p(s1∣s1,a2)=0.5
每个状态下的决策系统被称为policy策略,用 π \pi π表示, π ( a 1 ∣ s 1 ) \pi(a_1|s_1) π(a1∣s1)表示在该策略指导下,在 s 1 s_1 s1状态下执行 a 1 a_1 a1的概率是多少,同一状态下所有action和应该为1,策略也可以用表格表示
| a 1 a_1 a1 | a 2 a_2 a2 | |
|---|---|---|
| s 1 s_1 s1 | 0.6 0.6 0.6 | 0.4 0.4 0.4 |
| s 2 s_2 s2 | 0.6 0.6 0.6 | 0.5 0.5 0.5 |
Reward:每次action之后,得到一个score,表示对该行为的鼓励or惩罚,可以通过设计reward来实现对RL的控制,reward的设计可以用表格来表示。
| a 1 a_1 a1 | a 2 a_2 a2 | |
|---|---|---|
| s 1 s_1 s1 | r 1 r_1 r1 | r 2 r_2 r2 |
| s 2 s_2 s2 | r 3 r_3 r3 | r 4 r_4 r4 |
也可以用概率表示,p(r1 | s_1,a_1)表示在 s 1 s_1 s1状态下, a 1 a_1 a1行为得到 r 1 r_1 r1 reward的概率,所有可能的reward概率和应该为1。
trajectory is a state-action-reward chain,也就是agent不断作出动作的轨迹: s 1 → a 2 s 2 → a 2 s 1 s_1 \overset{a_2}{\rightarrow} s_2 \overset{a_2}{\rightarrow} s_1 s1→a2s2→a2s1
return是指一个trajectory所有action的reward的和 r e t u r n = r 1 + r 2 return = r1+r2 return=r1+r2,用于评价trajectory或policy的优劣。为了控制轨迹过长的情况,引入discount rate γ \gamma γ, d i s c o u n t e d r e t u r n = r 1 + γ 1 r 2 + γ 2 r 3 + . . . discounted return = r1+\gamma^1r_2+\gamma^2r3+... discountedreturn=r1+γ1r2+γ2r3+... ,通过调节discount rate可以调节策略的偏好
当agent进入来terminal states,停止运行,形成的trajectory称为episode
terminal states就是目标状态,到达这个状态就停止,很多任务是没有terminal states,episode任务和continus任务是可以互相转换的,例如把目标状态的action space设定为只有一个action就是停在原地,episode任务就变成了continus任务。
markov decesion process(MDP)
- 集合
- 状态空间,行为空间,奖励空间
- 概率分布:
- 行为结果状态概率,行为reward概率
- 策略模型
- 马尔可夫性:当下概率仅与上一状态有关,与更前面的状态无关
如果策略一旦确定,概率融入到模型里了,就不需要策略模型了,MDP就变成了MP马尔可夫模型
Bellman Equation贝尔曼公式
state value
return的计算方式:
- 定义法,按照轨迹中的每个action的return加和
- 递归求return,从该state出发的轨迹的return依赖于该步本身的 r r r以及后续state出发的轨迹的return,可以得出方程 v 1 = r 1 + γ v 2 v1 = r_1+\gamma v2 v1=r1+γv2,每个state的列一下方程,就可以得到一个线性方程组,解线性方程组可得return值。
- v1,v2表示从 s 1 s 2 s_1 s_2 s1s2出发的所有轨迹的return的平均值(期望)
- 在RL中被称为bootstrapping,
对于策略而言,将整个轨迹以更一般的形式写出来:
S t → A t R t + 1 , S t + 1 → A t + 1 R t + 2 , S t + 2 → A t + 2 R t + 3 , … S_t\xrightarrow{A_t}R_{t+1},S_{t+1}\xrightarrow{A_{t+1}}R_{t+2},S_{t+2}\xrightarrow{A_{t+2}}R_{t+3},\ldots StAtRt+1,St+1At+1Rt+2,St+2At+2Rt+3,…
其中所有的大写符号都是随机变量,discounted return计算如下:
G t = R t + 1 + γ R t + 2 + γ 2 R t + 3 + … G_t=R_{t+1}+\gamma R_{t+2}+\gamma^2R_{t+3}+\ldots Gt=Rt+1+γRt+2+γ2Rt+3+…
为了评价策略,定义state value为一个策略所可能出现的所有轨迹的discounted return G t G_t Gt的期望值 v π = E [ G t ∣ S t = s ] v_{\pi} = E[G_t |S_t = s] vπ=E[Gt∣St=s],是一个关于初始状态s的函数,代表了该state的value,如果一个state的value高,表示该state更有价值,值得我们向这个state前进。
Bellman equation贝尔曼公式
结合上面的递推公式以及 discounted return公式,得到 G t = R t + 1 + G t + 1 G_t = R_{t+1} + G_{t+1} Gt=Rt+1+Gt+1,因此:
E ( G t ∣ S t = s ) = E ( R t + 1 + G t + 1 ∣ S t = s ) = E ( R t + 1 ∣ S t = s ) + E ( G t + 1 ∣ S t = s ) E(G_t |S_t=s) = E(R_{t+1} + G_{t+1} | S_t = s) = E(R_{t+1}| S_t = s)+E(G_{t+1}| S_t = s) E(Gt∣St=s)=E(Rt+1+Gt+1∣St=s)=E(Rt+1∣St=s)+E(Gt+1∣St=s)
其中:
E ( R t + 1 ∣ S t = s ) = ∑ a π ( a ∣ s ) E [ R t + 1 ∣ S t = s , A t = a ] = ∑ a π ( a ∣ s ) ∑ r p ( r ∣ s , a ) r \begin{align} E(R_{t+1}| S_t = s) &= \sum_a \pi(a|s)E[R_{t+1} | S_t=s ,A_t=a] \\ &= \sum_a \pi(a|s)\sum_r p(r | s,a)r \\ \end{align} E(Rt+1∣St=s)=a∑π(a∣s)E[Rt+1∣St=s,At=a]=a∑π(a∣s)r∑p(r∣s,a)r
表示从s出发,进行一次action的平均reward
E [ G t + 1 ∣ S t = s ] = ∑ s ′ E [ G t + 1 ∣ S t = s , S t + 1 = s ′ ] p ( s ′ ∣ s ) = ∑ s ′ E [ G t + 1 ∣ S t + 1 = s ′ ] p ( s ′ ∣ s ) = ∑ s ′ v π ( s ′ ) p ( s ′ ∣ s ) = ∑ s ′ v π ( s ′ ) ∑ a p ( s ′ ∣ s , a ) π ( a ∣ s ) \begin{aligned} \mathbb{E}[G_{t+1}|S_{t}=s]& \begin{aligned}=\sum_{s'}\mathbb{E}[G_{t+1}|S_t=s,S_{t+1}=s']p(s'|s)\end{aligned} \\ &=\sum_{s'}\mathbb{E}[G_{t+1}|S_{t+1}=s']p(s'|s) \\ &=\sum_{s'}v_\pi(s')p(s'|s) \\ &=\sum_{s'}v_\pi(s')\sum_ap(s'|s,a)\pi(a|s) \\ \end{aligned} E[Gt+1∣St=s]=s′∑E[Gt+1∣St=s,St+1=s′]p(s′∣s)=s′∑E[Gt+1∣St+1=s′]p(s′∣s)=s′∑vπ(s′)p(s′∣s)=s′∑vπ(s′)a∑p(s′∣s,a)π(a∣s)
表示从s出发,到达的下一状态的state value的平均值。
得到Bellman equation:
v π ( s ) = E [ R t + 1 ∣ S t = s ] + γ E [ G t + 1 ∣ S t = s ] , = ∑ a π ( a ∣ s ) ∑ r p ( r ∣ s , a ) r ⏟ mean of immediate rewards + γ ∑ a π ( a ∣ s ) ∑ s ′ p ( s ′ ∣ s , a ) v π ( s ′ ) ⏟ mean of future rewards , = ∑ a π ( a ∣ s ) [ ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v π ( s ′ ) ] , ∀ s ∈ S . \begin{aligned} v_{\pi}(s) & =\mathbb{E}\left[R_{t+1} \mid S_{t}=s\right]+\gamma \mathbb{E}\left[G_{t+1} \mid S_{t}=s\right], \\ & =\underbrace{\sum_{a} \pi(a \mid s) \sum_{r} p(r \mid s, a) r}_{\text {mean of immediate rewards }}+\underbrace{\gamma \sum_{a} \pi(a \mid s) \sum_{s^{\prime}} p\left(s^{\prime} \mid s, a\right) v_{\pi}\left(s^{\prime}\right)}_{\text {mean of future rewards }}, \\ & =\sum_{a} \pi(a \mid s)\left[\sum_{r} p(r \mid s, a) r+\gamma \sum_{s^{\prime}} p\left(s^{\prime} \mid s, a\right) v_{\pi}\left(s^{\prime}\right)\right], \quad \forall s \in \mathcal{S} . \end{aligned} vπ(s)=E[Rt+1∣St=s]+γE[Gt+1∣St=s],=mean of immediate rewards a∑π(a∣s)r∑p(r∣s,a)r+mean of future rewards γa∑π(a∣s)s′∑p(s′∣s,a)vπ(s′),=a∑π(a∣s)[r∑p(r∣s,a)r+γs′∑p(s′∣s,a)vπ(s′)],∀s∈S.
看整理后的bellman公式,就是每个轨迹的discounted return乘以policy得出执行每个action的概率。
所以可以用于评估策略模型。
将前者定义为 r π ( s i ) r_{\pi}(s_i) rπ(si),表示前者执行action的return的期望值,后者定义为 p π ( s j ∣ s i ) = ∑ a p ( s ′ ∣ s , a ) π ( a ∣ s ) p_{\pi}(s_j|s_i) = \sum_ap(s'|s,a)\pi(a|s) pπ(sj∣si)=∑ap(s′∣s,a)π(a∣s)表示从 s i s_i si到 s j s_j sj的概率,可以简写为:
v π ( s ) = r π ( s ) + γ ∑ s ′ p π ( s ′ ∣ s ) v π ( s ′ ) (1) r π ( s ) ≜ ∑ a π ( a ∣ s ) ∑ r p ( r ∣ s , a ) r , p π ( s ′ ∣ s ) ≜ ∑ a π ( a ∣ s ) p ( s ′ ∣ s , a ) v_\pi(s)=r_\pi(s)+\gamma\sum_{s^{\prime}}p_\pi(s^{\prime}|s)v_\pi(s^{\prime})\text{(1)}\\r_\pi(s)\triangleq\sum_a\pi(a|s)\sum_rp(r|s,a)r,\quad p_\pi(s^{\prime}|s)\triangleq\sum_a\pi(a|s)p(s^{\prime}|s,a) vπ(s)=rπ(s)+γs′∑pπ(s′∣s)vπ(s′)(1)rπ(s)≜a∑π(a∣s)r∑p(r∣s,a)r,pπ(s′∣s)≜a∑π(a∣s)p(s′∣s,a)
考虑所有state列方程,可以得到矩阵形式的贝尔曼方程:
v π = r π + γ P π v π v_\pi=r_\pi+\gamma P_\pi v_\pi vπ=rπ+γPπvπ
where
∙ \bullet ∙ v π = [ v π ( s 1 ) , … , v π ( s n ) ] T ∈ R n v_\pi = [ v_\pi ( s_1) , \ldots , v_\pi ( s_n) ] ^T\in \mathbb{R} ^n vπ=[vπ(s1),…,vπ(sn)]T∈Rn
∙ \bullet ∙ r π = [ r π ( s 1 ) , … , r π ( s n ) ] T ∈ R n r_\pi = [ r_\pi ( s_1) , \ldots , r_\pi ( s_n) ] ^T\in \mathbb{R} ^n rπ=[rπ(s1),…,rπ(sn)]T∈Rn
∙ \bullet ∙ P π ∈ R n × n P_\pi \in \mathbb{R} ^{n\times n} Pπ∈Rn×n, where [ P π ] i j = p π ( s j ∣ s i ) [P_\pi]_{ij}=p_\pi(s_j|s_i) [Pπ]ij=pπ(sj∣si), is the state transition matrix
例子如下:
[ v π ( s 1 ) v π ( s 2 ) v π ( s 3 ) v π ( s 4 ) ] = [ r π ( s 1 ) r π ( s 2 ) r π ( s 3 ) r π ( s 4 ) ] ⏟ r π + γ [ p π ( s 1 ∣ s 1 ) p π ( s 2 ∣ s 1 ) p π ( s 3 ∣ s 1 ) p π ( s 4 ∣ s 1 ) p π ( s 1 ∣ s 2 ) p π ( s 2 ∣ s 2 ) p π ( s 3 ∣ s 2 ) p π ( s 4 ∣ s 2 ) p π ( s 1 ∣ s 3 ) p π ( s 2 ∣ s 3 ) p π ( s 3 ∣ s 3 ) p π ( s 4 ∣ s 3 ) p π ( s 1 ∣ s 4 ) p π ( s 2 ∣ s 4 ) p π ( s 3 ∣ s 4 ) p π ( s 4 ∣ s 4 ) ] ⏟ P π [ v π ( s 1 ) v π ( s 2 ) v π ( s 3 ) v π ( s 4 ) ] ⏟ v π . \left.\left[\begin{array}{c}v_\pi(s_1)\\v_\pi(s_2)\\v_\pi(s_3)\\v_\pi(s_4)\end{array}\right.\right]=\underbrace{\left[\begin{array}{c}r_\pi(s_1)\\r_\pi(s_2)\\r_\pi(s_3)\\r_\pi(s_4)\end{array}\right]}_{r_\pi}+\gamma\underbrace{\left[\begin{array}{c}p_\pi(s_1|s_1)&p_\pi(s_2|s_1)&p_\pi(s_3|s_1)&p_\pi(s_4|s_1)\\p_\pi(s_1|s_2)&p_\pi(s_2|s_2)&p_\pi(s_3|s_2)&p_\pi(s_4|s_2)\\p_\pi(s_1|s_3)&p_\pi(s_2|s_3)&p_\pi(s_3|s_3)&p_\pi(s_4|s_3)\\p_\pi(s_1|s_4)&p_\pi(s_2|s_4)&p_\pi(s_3|s_4)&p_\pi(s_4|s_4)\end{array}\right]}_{P_\pi}\underbrace{\left[\begin{array}{c}v_\pi(s_1)\\v_\pi(s_2)\\v_\pi(s_3)\\v_\pi(s_4)\end{array}\right]}_{v_\pi}. vπ(s1)vπ(s2)vπ(s3)vπ(s4) =rπ rπ(s1)rπ(s2)rπ(s3)rπ(s4) +γPπ pπ(s1∣s1)pπ(s1∣s2)pπ(s1∣s3)pπ(s1∣s4)pπ(s2∣s1)pπ(s2∣s2)pπ(s2∣s3)pπ(s2∣s4)pπ(s3∣s1)pπ(s3∣s2)pπ(s3∣s3)pπ(s3∣s4)pπ(s4∣s1)pπ(s4∣s2)pπ(s4∣s3)pπ(s4∣s4) vπ vπ(s1)vπ(s2)vπ(s3)vπ(s4) .
P π 就是概率论里面马尔可夫链中的状态转移矩阵 P_{\pi}就是概率论里面马尔可夫链中的状态转移矩阵 Pπ就是概率论里面马尔可夫链中的状态转移矩阵
使用矩阵形式的Bellman公式求state value时,一般都是使用叠代法求解,先估计一个结果 v 0 v_{0} v0,带入 v k + 1 = r π + γ P π v k v_{k+1}=r_\pi+\gamma P_\pi v_{k} vk+1=rπ+γPπvk,随着k的增大, v k v_k vk收敛于 v π v_\pi vπ
这里收敛的原因,跟现代控制工程中的观测器收敛是一样的原因,观测值和实际值间的error是不断趋于0的。
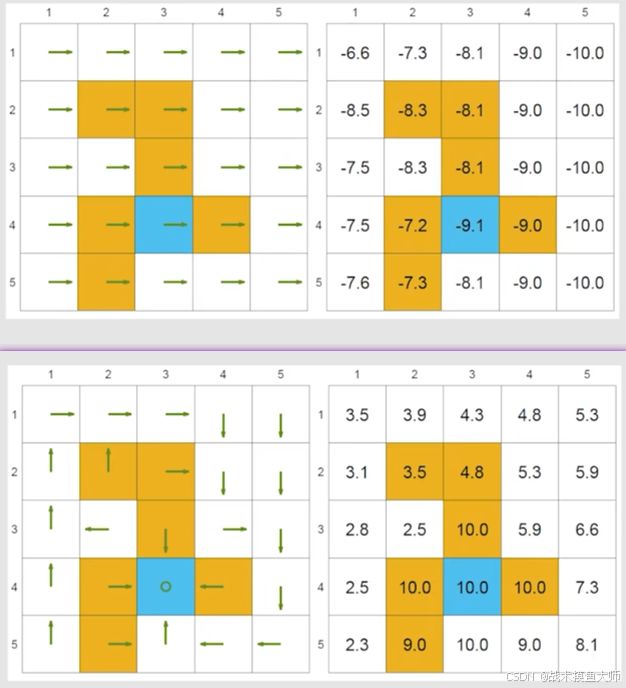
这个图是赵老师PPT里面的图,上面是一个较差策略的结果,下面是较好策略的结果。
action value
action value表示该action的价值,policy依据action value判断选择哪个action执行。action value定义如下:
q π ( s , a ) = E [ G t ∣ S t = s , A t = a ] q_\pi(s,a)=\mathbb{E}[G_t|S_t=s,A_t=a] qπ(s,a)=E[Gt∣St=s,At=a]
含义是从s状态出发,选择a行为时的discounted return
只是帮助理解,严格来说,这个不是discounted return,因为它只限定了第一个action,并不是一个路径
action value和state value的联系:
E [ G t ∣ S t = s ] ⏟ v π ( s ) = ∑ a E [ G t ∣ S t = s , A t = a ] ⏟ q π ( s , a ) π ( a ∣ s ) v π ( s ) = ∑ a π ( a ∣ s ) q π ( s , a ) \underbrace{\mathbb{E}[G_t|S_t=s]}_{v_\pi(s)}=\sum_a\underbrace{\mathbb{E}[G_t|S_t=s,A_t=a]}_{q_\pi(s,a)}\pi(a|s) \\ v_\pi(s)=\sum_a\pi(a|s)q_\pi(s,a) vπ(s) E[Gt∣St=s]=a∑qπ(s,a) E[Gt∣St=s,At=a]π(a∣s)vπ(s)=a∑π(a∣s)qπ(s,a)
可以参考上面的贝尔曼公式得到action value的计算公式 q π ( s , a ) = r a + γ v π s j q_\pi(s,a) = r_a + \gamma v_\pi {s_j} qπ(s,a)=ra+γvπsj
Bellman Optimality Equation 贝尔曼最优公式
最优策略
如果有两个策略 π 1 \pi_1 π1和 π 2 \pi_2 π2,如果满足 v π 1 ( s ) ≥ v π 2 ( s ) , ∀ s ∈ S v_{\pi_1}(s) \ge v_{\pi_2}(s),\space \space \forall s \in S vπ1(s)≥vπ2(s), ∀s∈S,则称 π 1 \pi_1 π1优于 π 2 \pi_2 π2,如果一个策略比任意策略都优,就称为最优策略。
存在性,唯一性,确定性,都可以通过贝尔曼最优公式证明
贝尔曼最优公式
element-wise form:
v ( s ) = max π ∑ a π ( a ∣ s ) ( ∑ r p ( r ∣ s , a ) r + γ ∑ s ′ p ( s ′ ∣ s , a ) v ( s ′ ) ) , ∀ s ∈ S = max π ∑ a π ( a ∣ s ) q ( s , a ) \begin{align} v(s) & =\max_\pi \sum_{a} \pi(a \mid s)\left(\sum_{r} p(r \mid s, a) r+\gamma \sum_{s^{\prime}} p\left(s^{\prime} \mid s, a\right) v\left(s^{\prime}\right)\right), \quad \forall s \in \mathcal{S} \\ & = \max_\pi \sum_a \pi(a|s)q(s,a) \end{align} v(s)=πmaxa∑π(a∣s)(r∑p(r∣s,a)r+γs′∑p(s′∣s,a)v(s′)),∀s∈S=πmaxa∑π(a∣s)q(s,a)
matrix from:
v = max π ( r π + γ P π v ) v = \max_\pi(r_\pi + \gamma P_\pi v) v=πmax(rπ+γPπv)
γ \gamma γ的取值会影响策略对远近reward的取舍, γ \gamma γ越大越远视,越小越近视,如果设为0,策略就只会考虑第一步的reward
如果reward奖励改为了 a r + b ar+b ar+b,相应的state value改为 v ′ = a v + b 1 − γ 1 v^{\prime} = av+\frac{b}{1-\gamma}1 v′=av+1−γb1,action value也会一样变化。
求解最优策略
根据action value更新策略,将action value较大的action的概率调高/直接设置为1。
流程如下:
- 初始化策略 π 0 \pi_0 π0和state value向量 v 0 v_0 v0
- 带入贝尔曼最优化公式,求解出 v 1 v_1 v1
- 根据 v 1 v_1 v1求解出action value
- 根据action value更新策略 π 1 \pi_1 π1
- 根据 π 1 \pi_1 π1和 v 1 v_1 v1计算 v 2 v_2 v2
- …
每次都选择action value最大的action,一定会得到最优策略
证明:
前置知识:contraction mapping theorem
不动点fixed point: f ( x ) = x f(x) = x f(x)=x
收缩映射contraction mapping: ∣ ∣ f ( x 1 ) − f ( x 2 ) ∣ ∣ ≤ γ ∣ ∣ x 1 − x 2 ∣ ∣ , γ ∈ ( 0 , 1 ) ||f(x_1) - f(x_2)|| \le \gamma ||x_1-x_2||,\quad \gamma \in (0,1) ∣∣f(x1)−f(x2)∣∣≤γ∣∣x1−x2∣∣,γ∈(0,1)
这些都是可以扩展到向量和矩阵的,相应的绝对值变为向量模
对于一个线性函数: f ( x ) = a x f(x) = ax f(x)=ax,可以得到0是一个不动点,当 a i n ( 0 , 1 ) a \ in(0,1) a in(0,1)时是一个contraction mapping
扩展到矩阵向量形式里面: f ( x ) = A x , x ∈ R n , A ∈ R n × n f(x) = Ax,x \in R^{n},A \in R^{n\times n} f(x)=Ax,x∈Rn,A∈Rn×n,可以得到0向量是一个不动点,当 ∣ ∣ A ∣ ∣ ≤ 1 ||A|| \le 1 ∣∣A∣∣≤1的时候,是个contraction mapping
对于任意 f ( x ) = x f(x) = x f(x)=x的等式,如果 f f f是contraction mapping,那么:
- 一定存在fixed point
- fixed point一定是唯一的
- 可以通过 x k + 1 = f ( x k ) x_{k+1} = f(x_k) xk+1=f(xk)的方式迭代求解
这不就是把这个问题当作控制问题来解决了嘛?如果A的特征值小于1,x收敛
至于该最优state value是否存在,看赵老师课程讲解
Ref
【【强化学习的数学原理】课程:从零开始到透彻理解(完结)