深度解析 MySQL 数据冷热分离:从原理到电商实战的全链路实践
在数据量呈指数级增长的今天,MySQL 数据库面临着存储成本飙升与查询性能下降的双重挑战。数据冷热分离通过将高频访问的 "热数据" 与低频使用的 "冷数据" 分区分层存储,成为解决这一难题的核心技术。本文结合底层原理与电商实战案例,完整呈现从架构设计到落地优化的全流程,助您构建高性能低成本的数据存储体系。
一、数据冷热分离核心原理:构建分级存储体系
1. 数据分级的三维模型
根据访问频率、业务价值和存储时效,将数据划分为三层架构:
- 热数据(Hot Data):最近 30 天内的数据,承载 80% 以上的业务操作,需毫秒级响应(如电商实时订单、金融交易流水)
- 温数据(Warm Data):30 天 - 1 年内的数据,用于报表统计与历史分析,需秒级查询(如用户半年消费记录、季度运营报表)
- 冷数据(Cold Data):1 年以上的归档数据,仅用于合规审计或长期趋势分析(如三年前的交易日志、历史库存记录)
2. 存储介质的差异化选型
| 数据类型 | 存储方案 | 典型介质 | 成本对比 | 读写 IOPS | 适用场景 |
|---|---|---|---|---|---|
| 热数据 | 本地 SSD+InnoDB | NVMe SSD | 10x | 10,000+ | 实时交易、高频查询 |
| 温数据 | 机械硬盘 + InnoDB/MyISAM | SATA HDD | 3x | 1,000 | 报表统计、历史数据查询 |
| 冷数据 | 归档表 + 对象存储 / 磁带库 | AWS S3/IBM 磁带库 | 1x | 100 | 长期备份、合规存储 |
3. 核心技术实现矩阵
- 分区表(Partitioning):按时间 / 范围 / 哈希将数据分散到独立物理文件,如按年 / 月创建分区
- 分库分表(Sharding):通过业务维度拆分数据库,热数据集中主库,冷数据迁移归档库
- 归档存储(Archiving):使用
ENGINE=ARCHIVE+ 分区技术实现冷数据离线存储,降低 IO 消耗 - 读写分离(Read/Write Splitting):热数据读写走主库,冷数据查询路由到低成本从库
二、实战架构设计:构建三层存储体系
1. 分层架构全景图
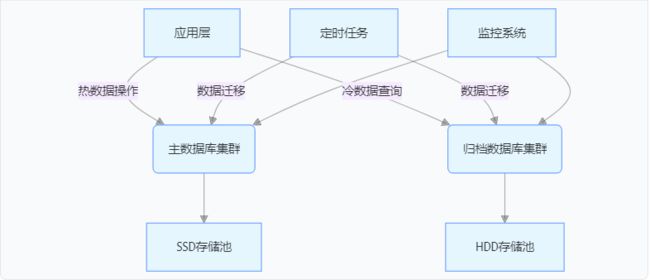
2. 分区表设计最佳实践
热数据表(订单实时库)
sql
CREATE TABLE orders_hot (
order_id BIGINT PRIMARY KEY AUTO_INCREMENT,
user_id BIGINT,
order_time DATETIME,
amount DECIMAL(10,2),
status TINYINT
) ENGINE=InnoDB
PARTITION BY RANGE (TO_DAYS(order_time)) (
PARTITION p202407 VALUES LESS THAN (TO_DAYS('2024-08-01')),
PARTITION p202408 VALUES LESS THAN (TO_DAYS('2024-09-01')),
PARTITION p_max VALUES LESS THAN MAXVALUE -- 预留未来分区
);
冷数据表(订单归档库)
sql
CREATE TABLE orders_cold (
order_id BIGINT,
user_id BIGINT,
order_time DATETIME,
amount DECIMAL(10,2)
) ENGINE=ARCHIVE
PARTITION BY KEY (order_id)
PARTITIONS 10; -- 哈希分区均衡存储压力
三、电商实战案例:亿级订单系统的性能突围
1. 业务挑战与数据特征
- 数据规模:日增订单 80 万 +,累计 12 亿条,单表突破 8 亿条
- 核心痛点:
- 实时查询延迟超 1.2 秒,促销期主库负载飙红
- SSD 存储成本年增 200%,历史数据导出常引发锁表
- 访问特征:30 天内数据承载 75% 的读写操作,1 年以上数据仅占 5% 访问量
2. 实施路径与关键技术
步骤 1:数据清洗与初始迁移
bash
# 使用pt-archiver迁移历史冷数据(一次性迁移5年数据)
pt-archiver \
--source h=old_master,D=order_db,t=orders \
--dest h=archive_db,D=order_cold,t=orders_2023 \
--where "order_time < '2023-01-01'" \
--limit 10000 --bulk-insert --progress 30000
步骤 2:自动化迁移体系构建
python
# 热→温数据迁移脚本(每日凌晨执行)
def migrate_heat_to_warm():
cutoff = datetime.now() - timedelta(days=30)
with connect_hot() as src, connect_warm() as dst:
# 查询待迁移分区
src.cursor.execute(f"SELECT PARTITION_NAME FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_NAME='orders_hot' AND PARTITION_DESCRIPTION < {TO_DAYS(cutoff)}")
# 跨库迁移数据
dst.cursor.executemany("INSERT INTO orders_warm VALUES (%s,%s,%s,%s,%s)", src.fetchall())
# 删除过期分区(DDL操作需在业务低峰期执行)
src.cursor.execute(f"ALTER TABLE orders_hot DROP PARTITION {partition_name}")
步骤 3:索引优化与读写分离
- 热库索引:组合索引
(order_time, user_id)优化实时查询,索引大小压缩 30% - 温库索引:覆盖索引
(order_id, amount)减少回表,查询效率提升 40% - 读写分离:热库配置 3 主 2 从,温库 / 冷库仅开放只读节点,主库写入 TPS 提升 70%
3. 实施效果与成本对比
| 指标 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
| 订单查询 RT | 1200ms | 280ms | 76.7% |
| 存储成本 | 1800 万 / 年 | 650 万 / 年 | 63.9% |
| 慢查询数量 | 320 次 / 小时 | 25 次 / 小时 | 92.2% |
| 硬件资源 | 8 台 SSD 服务器 | 3 台 SSD+5 台 HDD | 服务器减少 40% |
四、关键技术点与避坑指南
1. 分区修剪优化
通过EXPLAIN PARTITIONS验证查询是否精准命中分区:
sql
EXPLAIN PARTITIONS SELECT * FROM orders_hot
WHERE order_time BETWEEN '2024-07-01' AND '2024-07-31';
-- 确保输出结果中partitions列仅包含p202407分区
2. 事务一致性保障
- 跨分区事务使用分布式事务框架(如 Seata),避免 XA 协议性能损耗
- 大批次迁移时采用
LIMIT 10000 + ORDER BY order_id,防止锁表影响业务
3. 冷数据回迁机制
对促销期高频访问的冷数据,通过临时视图加载到温库缓存:
sql
CREATE TEMPORARY TABLE temp_old_orders AS
SELECT * FROM orders_cold WHERE order_time BETWEEN '2023-11-11' AND '2023-11-12';
五、经验总结:从理论到落地的核心法则
1. 数据特征优先原则
- 优先选择时间字段(如
order_time)作为分区键,天然符合交易数据时间局部性 - 高频查询字段必须包含在分区键或索引中,避免跨分区全表扫描
2. 渐进式实施策略
- 先迁移历史冷数据,再实现增量数据自动化迁移,降低业务中断风险
- 采用 A/B 测试验证分区方案,通过
SHOW CREATE TABLE对比分区文件大小
3. 监控体系建设
- 按分区级别监控数据量、IOPS、慢查询,使用 Grafana 绘制分区健康度仪表盘
- 设定存储水位告警(热库使用率 > 80% 触发扩容,冷库迁移成功率 < 95% 自动重试)
结语
MySQL 数据冷热分离是平衡性能与成本的核心技术,其本质是通过数据分级实现资源的精准分配。从电商实战经验来看,成功的关键在于:
- 精准的数据特征分析:明确冷热数据边界,避免过度设计导致的复杂度
- 工具链的深度整合:结合 pt-archiver、Python 脚本、Prometheus 形成闭环管理
- 业务场景的深度适配:根据订单查询高频字段优化索引,确保冷热数据访问效率
随着数据治理需求的深化,冷热分离将与湖仓一体、数据湖等架构进一步融合。建议技术团队从时间范围分区入手,逐步构建分层存储体系,在数据量爆发增长的场景下保持数据库的高效运行。