深度学习实战之手写数字识别
一、简介
在深度学习的世界里,手写数字识别是一个经典且入门级的任务,它就像是深度学习领域的 “Hello, World!”,通过完成这个任务,我们能够快速掌握深度学习模型的搭建、训练与测试流程。本文将基于 PyTorch 框架,手把手教你实现一个手写数字识别模型。
二、具体代码实现
1、pytorch基础库导入
import torch
print(torch.__version__)#该行代码用来检查pytorch的版本
import torch#基础库
from torch import nn #导入神经网络模块,所有神经网络模块的基础
from torch.utils.data import DataLoader#数据包管理工具,打包数据
from torchvision import datasets #封装了很多与图像相关的模型,数据集,手写数字就在datasets里面
from torchvision.transforms import ToTensor#数据转换,张量,将其他类型的数据转换为tensor张量,numpy array,pandas dataframe首先,我们导入 PyTorch 库及其相关模块。
torch是 PyTorch 的基础库;
nn模块用于构建神经网络;
DataLoader能够帮助我们管理和加载数据;
datasets包含了许多常用的数据集,我们后续会使用其中的 MNIST 手写数字数据集;
ToTensor则用于将数据转换为 PyTorch 能够处理的张量格式。
2、数据集准备
MNIST 数据集是一个广泛应用于图像识别领域的手写数字数据集,包含了 0 - 9 共 10 个数字的手写图像。我们可以通过以下代码下载并准备训练集和测试集:
'''下载训练数据集(包含训练图片和标签)'''
training_data = datasets.MNIST(
root = "data",#表示下载的手写数字到哪个路径
train = True,#读取下载后的数据中的训练集
download = True,#如果你之前已经下载了,就不用再下载
transform = ToTensor(),#张量,图片是不能直接传入神经网络模型
)#对于pytorch库能够识别的数据类型一般是tensor张量
'''下载测试数据集,(包含训练图片和标签)'''
test_data = datasets.MNIST(
root = "data",#表示下载的手写数字数据到哪个路径
train = False,#不需要加载训练集,意味着直接加载测试集
download = False,
transform = ToTensor(),#Tensor是在深度学习中提出并广泛应用的数据类型
)
print(len(training_data))
这里,root指定了数据集的下载路径;train=True表示下载训练集,train=False则表示下载测试集;download=True会在本地没有数据集时自动下载;transform=ToTensor()将图像数据转换为张量格式,以便后续输入到神经网络中。
为了直观感受 MNIST 数据集的样子,我们还可以展示几张手写数字图片:
'''展示手写数字图片,把训练数据集中的59000张图片展示一下'''
from matplotlib import pyplot as plt
figure = plt.figure()#创建一个画布
for i in range(9):
img, label = training_data[i+59000]#提取第59000张图片
figure.add_subplot(3, 3, i + 1)#图像窗口中创建多个小窗口,小窗口用于显示图片
plt.title(label)
plt.axis("off")#plt.show(I)显示矢量
plt.imshow(img.squeeze(), cmap = "gray")
a = img.squeeze()#img.squeeze()从张量img中去掉维度为1的。如果维度大小不为1则张量不会改变
plt.show()3、对数据进行打包
'''创建数据DataLoader(数据加载器)'''
train_dataloader = DataLoader(training_data, batch_size=64)#64张图片为一个包,不打包gpu运行速度就会慢
test_dataloader = DataLoader(test_data, batch_size=64)4、判断使用gpu还是cpu
'''判断当前设备是否支持gpu,其中mps是苹果m系列芯片的gpu'''
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else "cpu"
print(f"Using {device} device")#字符串的格式化,f代表将{}中的内容格式化5、定义神经网络模型
'''定义神经网络 类的继承这种方式'''#类就是将多个函数打包到一起,当我们创建一个类的时候,会自动创建一个名为self的共享空间。例如当执行 self.flatten = nn.Flatten()
#这个语句的时候,我们就会在self中创建一个空间内容,这个空间叫做flatten,它的内容就是nn.Flatten();
class NeuralNetwork(nn.Module):#nn.Module已经是一个完整的类,名字叫module,里面包含丰富的神经网络模型,这是模型自己定义的。NeuralNetwork拥有module的所有功能
def __init__(self):#python基础关于类,self类自己本身 init负责创建每一层网络结构,forward负责将数据流过每一层网络
super().__init__()#继承的父类初始化
self.flatten = nn.Flatten()#展开,创建一个展开对象flatten,专门用来将数据从多维转换成一维
self.hidden1 = nn.Linear(28*28, 128)#第一个参数,有多少神经元传入进来;第二个参数,有多少个数据传出去
self.hidden2 = nn.Linear(128, 256)#输入信息128个,输出256个
self.out = nn.Linear(256, 10)#输入进来256个数据,输出10个
def forward(self, x):#前向传播,你得告诉他数据的流向 x就是一会要传进来的一张图片
x = self.flatten(x)#图像进行展开,把二维图片拆解成一维的 其实执行的就是nn.Flatten(x)
x = self.hidden1(x)
x = torch.relu(x)#激活函数
x = self.hidden2(x)
x = torch.relu(x)
x = self.out(x)
return xnn.Flatten()用于将输入的二维或多维图像张量展开为一维向量;
nn.Linear()是全连接层,通过设置不同的输入和输出神经元数量来构建网络层;
torch.relu()作为激活函数,为网络引入非线性,使模型能够学习到更复杂的模式;
forward方法定义了数据在网络中的前向传播路径。
6、传入模型
#模型在哪,数据也要传到哪
model = NeuralNetwork().to(device)#把刚刚创建的模型传入到GPU
print(model)
定义好模型后,将其移动到指定的设备上。
7、训练函数定义
def train(dataloader, model, loss_fn, optimizer):
model.train()#告诉模型,我要开始训练,模型中w进行随机化操作,已经更新w。在训练过程中,w会被修改的
#pytorch提供两种方式来切换训练和测试的模式,分别是model.train()和model.eval()
#一般用法是:在训练开始之前写上model.train(),在测试时写上model.eval()
batch_size_num = 1#统计有多少个批次的数据在运行,统计训练的batch的数量
for X, y in dataloader:
X, y = X.to(device), y.to(device)#把训练数据集和标签传入cpu或gpu
pred = model.forward(X)#.forward可以省略,父类中已经对此功能进行了设置
loss = loss_fn(pred, y)#通过交叉熵损失函数计算损失值loss
optimizer.zero_grad()#梯度值清零
loss.backward()#根据loss反向传播计算得到每个参数的梯度值w
optimizer.step()#根据梯度值更新网络w参数
loss_value = loss.item() #从tensor数据中提取数据出来,tensor获取损失值 loss.item()将tensor类型的数据转换成python能识别的数据类型
if batch_size_num % 100 == 0:
print(f"loss:{loss_value: > 7f} [number:{batch_size_num}]")
batch_size_num += 1model.train()将模型设置为训练模式;
通过循环遍历数据加载器中的每个批次,将数据和标签移动到指定设备上;
使用模型进行预测,计算损失值;
optimizer.zero_grad()清空梯度;
loss.backward()进行反向传播计算梯度;
optimizer.step()根据梯度更新模型参数。
8、测试函数定义
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset)#获取测试集原始数据集的个数
num_batches = len(dataloader)#获取打包之后的数量
model.eval()#测试,w就不能再更新
test_loss, correct = 0, 0
with torch.no_grad():#一个上下文管理器,关闭梯度计算
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model.forward(X)
test_loss += loss_fn(pred, y).item()# test_loss是会自动累加每一个批次的损失值
correct += (pred.argmax(1) == y).type(torch.float).sum().item()
a = (pred.argmax(1) == y)#dim=1表示每一行中的最大值对应的索引号,dim=0表示每一列中的最大值对应的索引号
b = (pred.argmax(1) == y).type(torch.float)
test_loss /= num_batches#能来衡量模型测试的好坏
correct /= size#平均的正确率
print(f"Test result:\n Accuracy: {(100*correct)}%, Avg loss:{test_loss}")model.eval()将模型设置为测试模式;
with torch.no_grad()关闭梯度计算,节省内存和计算资源;
计算测试集上的损失值和预测准确率,并打印输出结果。
9、训练模型
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
#创建一个优化器,SGD为随机梯度下降算法 parameters()用来获取模型的参数
epochs = 10
for t in range(epochs):
print(f"Epochs {t + 1}\n----------------------------")
train(train_dataloader, model, loss_fn, optimizer)
print("Done!")
test(test_dataloader, model, loss_fn)这里使用交叉熵损失函数nn.CrossEntropyLoss()作为损失度量,随机梯度下降算法torch.optim.SGD作为优化器,设置学习率lr=0.01,进行 10 轮训练后,在测试集上评估模型的性能。
10、运行结果
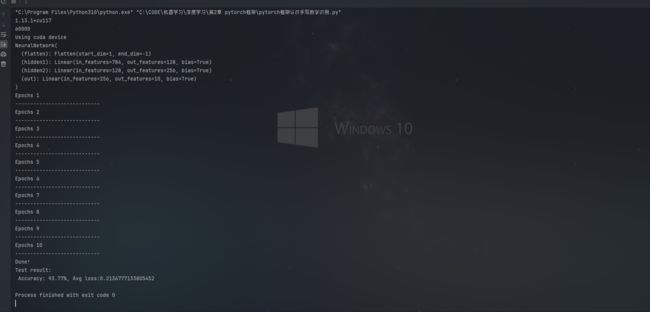
三、总结
通过以上步骤,我们成功地使用 PyTorch 完成了手写数字识别模型的搭建、训练与测试。手写数字识别只是深度学习应用的冰山一角,希望通过这个实战案例,能激发你在深度学习领域进一步探索的兴趣,开启更多有趣且富有挑战的项目之旅!下一章会为大家带来更加实用的深度学习技术,欢迎大家关注!