HBase可靠性管理方法浅析
HBase是一个可以进行实时读和写操作的分布式NoSQL系统,建立在HDFS之上,是Hadoop生态圈中重要的一部分。在HBase中底层存储结构采用的LSM-tree的方式进行处理,为了保证HBase的数据可靠性和可用性,HBase采用了多种方式,包括Snapshot、Replication等多种方式,下面简单分析HBase中的这几种方法。
1、Snapshot(快照)
快照是一些重要的元数据信息,这样系统管理员可以根据这些元数据信息有效的恢复到以前的状态。在系统运行过程中,有时需要恢复到以前的某个时候,保证以前的数据的可用性这时需要采用快照的方式保存以前的数据。在大规模高新能分布NoSQL系统中,为了保证系统性能,需要快速的进行系统表的快照的处理。HBase中的快照技术可以不用原始的保存原来的Table数据文件。HBase中的快照技术有如下几个作用:
- 恢复程序以前的错误。在程序或者应用运行错误的情况下,可以恢复到系统运行以前的状态
- 保存特定时间点的系统数据,可以用于生成系统特定时间点的报告
- 进行离线工作,可以把生成的快照文件导出到别的Hbase集群中进行处理

上图是HBase的架构图。在HBase中,HBase管理的snapshot的技术包括在线快照和离线快照,整个HBase的快照技术过程类似与两阶段提交过程,如下所示
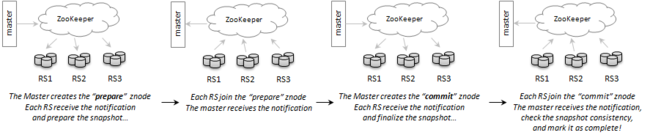
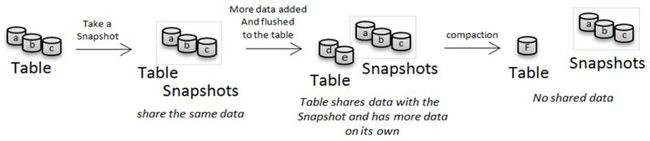
Note:在完成快照过程后,HBase集群会执行compact和split过程,这时原有的HFile文件会被删除,这是需要对于原有的HFile文件进行存档,所以在compact和split完成后需要对于原有的HFile文件进行archive。如下图所示
2、Replication(集群复制技术)
HBase集群的Replication技术是指复制一个HBase集群上的数据到另外一个HBase集群上去,它的工作原则就是在两个不同的HBase集群之间进行数据的复制。HBase的Replication技术主要用于多个数据中心之间,目标是进行容灾备份。在一个主HBase集群失效以后,从HBase集群可以接替原有的主HBase集群服务原有的HBase集群服务。HBase的集群复制模式包括三种:主-从(master-slave)、主-主(master-master)、循环(cyclic),如下图所示

主-主(master-master)模式 循环(cyclic)模式
参考资料:
[1] Apache HBase Replication Overview. http://blog.cloudera.com/blog/2012/07/hbase-replication-overview-2/
[2] Introduction to Apache HBase Snapshots. http://blog.cloudera.com/blog/2013/03/introduction-to-apache-hbase-snapshots/
[3] Introduction to Apache HBase Snapshots, Part 2: Deeper Dive. http://blog.cloudera.com/blog/2013/06/introduction-to-apache-hbase-snapshots-part-2-deeper-dive/