1)强化学习入门
#网页连接_需要认真学习#
【强化学习】40分钟透彻理解 理论+实践+改进;一气呵成,践行科技美学!_哔哩哔哩_bilibili
初探强化学习
GitHub - XinJingHao/DRL-Pytorch: Clean, Robust, and Unified PyTorch implementation of popular Deep Reinforcement Learning (DRL) algorithms (Q-learning, Duel DDQN, PER, C51, Noisy DQN, PPO, DDPG, TD3, SAC, ASL)
================【强化学习】40分钟透彻理解 理论+实践+改进======================
倒阶摆:
obs_dim 4 action_dim 2 左 右
强化学习:通过正反馈和负反馈,使得智能体学会一个策略,最大化累计奖励,即时奖励reward,我们将累计的奖励称为回报,将回报的期望作为优化目标。
简述 :action根据environment-->reward 即时回馈-->即时回馈进行累加![]() -->R (return)
-->R (return)
然后对Return期望E[R]或者Return平均值即是我们优化目标
马尔可夫过程:
下一时刻只依赖于当前时刻状态和动作,没有前向依赖
理解方式,
---正例子:下棋只看一眼当前的棋盘局势,就知道下一步怎么走,没有
---反例子:开车,当前视觉帧无法分辨预估下一步动作是前进还是倒车

优化目标最大化,优化问题就是梯度最优化
每次动作有概率,动作的好坏可以强化选择该次动作的概率或者减弱选择该次动作的概率
样本均值替换期望值
Overview:
建立一个Multilayer perceptron作为策略函数的核心构成
Arguments:
-obs:当前step下的观测值
Returns:
一策略分布,本质上是一个分布函数,softmax(logits)MLP多层感知机(人工神经网络)原理及代码实现_学习并实现或调用多层感知器mlpclassifier-CSDN博客
Policy 是一个分布
定义Loss函数
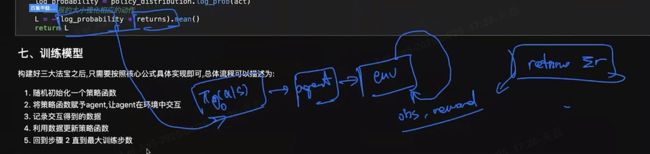
训练模型:
1,随机初始化一个策略函数
2,将策略函数赋予agent,让agent在环境中交互
3,记录交互得到数据
4,利用数据更新策略函数
5,回到步骤2直到最大训练步数
改进:
1)无偏估计是指估计量的期望值等于被估计的参数真值,方差和样本数量的关系(大数定律视角),增加样本数量
2)将整个时刻之前动作的奖励也进行了加和,当前动作对之前的奖励是毫无影响的,只有时刻之后得到的奖励才有资格评价时刻动作的好坏,因此可以计算“reward to go”代替“sum of reward’
3)baseline作为基线,可以通过reward设计,人工的减去一个baseline(也可以理解为阈值),使得回报有正有负,相当于班级分数平均值做个尺子
动作好坏的评价挺重要
numba加速(小函数加速)
重点总结:
1)Policy:Π(a|s) obs->mlp->logats->分布
给个s返回a obs/state ->action
2)通过正负反馈使得智能体学会一个策略,最大化累计奖励,我们将累计奖励称为回报,将回报的期望作为优化目标