你是否遇到过这样的场景:后台接口响应越来越慢,用户抱怨页面加载时间长,运维同事警告服务器负载飙升?分析日志发现,一个页面渲染竟然要发起几十上百个接口请求!随着用户量增长,系统就像陷入泥潭。这种情况在微服务架构特别常见 - 获取 10 个用户信息,就要发 10 次独立请求,每次都有网络延迟。如何优雅地解决这个问题?请求合并技术正是你需要的救星。
请求合并的核心原理
请求合并就是把短时间内的多个独立请求打包成一个批量请求,处理后再分发结果。这就像公交车而不是出租车 - 不是每个人单独派一辆车,而是等一小会儿,让大家坐同一辆车前往目的地,大幅提高效率。
请求合并能带来这些好处:
- 减少网络往返,显著降低总延迟
- 节约连接资源,避免连接池耗尽
- 减少数据库查询次数,降低数据库压力
- 提高系统整体吞吐量,降低资源消耗
三大合并策略及应用场景
1. 时间窗口合并
在固定时间窗口内(比如 50ms)收集所有请求,然后一起发送。这种策略适合对实时性要求不那么苛刻的场景。
这就像公交车,会在每个站点等待固定时间,不管上多少人都会准时发车。
2. 数量阈值合并
当收集到足够多的请求(如 100 个)后立即发送,不再等待。适合批处理场景,可以控制每批数据量。
这就像电梯容量到了就会自动关门,不会无限等待。
3. 混合策略
结合时间窗口和数量阈值,满足任一条件就触发批量请求。这是生产环境最常用的策略,能平衡实时性和效率。
类比食堂打饭:要么人满一桌就上菜,要么到点就上菜,哪个条件先满足就先执行。
高性能请求合并器实现
配置驱动的合并参数
首先,我们定义一个配置类来支持外部化配置:
/**
* 请求合并器配置类
*/
public class MergerConfig {
// 基本配置
public static final long DEFAULT_WINDOW_TIME = 50; // 默认时间窗口(ms)
public static final int DEFAULT_MAX_BATCH_SIZE = 100; // 默认最大批量大小
// 熔断配置
public static final int DEFAULT_FAILURE_THRESHOLD = 5; // 默认失败阈值
public static final long DEFAULT_CIRCUIT_RESET_TIMEOUT = 30_000; // 默认熔断重置时间(ms)
public static final long DEFAULT_REQUEST_TIMEOUT = 3_000; // 默认请求超时时间(ms)
// 根据系统环境变量获取配置值
public static long getWindowTime() {
return Long.parseLong(System.getProperty("merger.window.time",
String.valueOf(DEFAULT_WINDOW_TIME)));
}
public static int getMaxBatchSize() {
return Integer.parseInt(System.getProperty("merger.max.batch.size",
String.valueOf(DEFAULT_MAX_BATCH_SIZE)));
}
/**
* 根据系统资源状态动态调整合并参数
*/
public static void adjustParameters() {
// 基于CPU利用率动态调整批量大小
double cpuLoad = getSystemCpuLoad();
if (cpuLoad > 0.8) { // CPU负载高
System.setProperty("merger.max.batch.size",
String.valueOf(DEFAULT_MAX_BATCH_SIZE / 2));
} else if (cpuLoad < 0.3) { // CPU负载低
System.setProperty("merger.max.batch.size",
String.valueOf(DEFAULT_MAX_BATCH_SIZE * 2));
}
}
/**
* 获取系统CPU负载
*/
private static double getSystemCpuLoad() {
try {
return ManagementFactory.getOperatingSystemMXBean()
.getSystemLoadAverage() / Runtime.getRuntime().availableProcessors();
} catch (Exception e) {
return 0.5; // 默认值
}
}
// 其他getter方法...
}同步请求合并器
下面是一个支持监控、部分结果处理的高性能同步请求合并器:
/**
* 同步请求合并器
* 时间复杂度:O(1)平均情况,O(n)触发批处理时
* 空间复杂度:O(n)其中n为等待处理的请求数
*/
public class RequestMerger {
private static final Logger log = LoggerFactory.getLogger(RequestMerger.class);
private final long windowTimeMillis;
private final int maxBatchSize;
private final Function, Map> batchFunction;
private final V defaultValue;
private final boolean allowPartialResult;
// 使用ConcurrentHashMap减少锁竞争
private final ConcurrentHashMap>> pendingRequests = new ConcurrentHashMap<>();
private final List pendingKeys = Collections.synchronizedList(new ArrayList<>());
private final Object batchLock = new Object(); // 细粒度锁,只锁批处理操作
private ScheduledFuture scheduledTask;
private final ScheduledExecutorService scheduler =
Executors.newSingleThreadScheduledExecutor(r -> {
Thread t = new Thread(r, "request-merger-scheduler");
t.setDaemon(true); // 使用守护线程避免阻止JVM退出
return t;
});
// 监控指标
private final Timer batchProcessTimer;
private final Counter batchSizeCounter;
private final Counter requestCounter;
private final Counter batchCounter;
/**
* 创建请求合并器
* @param windowTimeMillis 时间窗口(毫秒)
* @param maxBatchSize 最大批处理大小
* @param batchFunction 批量处理函数,需返回包含所有输入key的Map
* @param allowPartialResult 是否允许部分结果
* @param defaultValue 默认值(当key没有对应值且allowPartialResult为true时使用)
*/
public RequestMerger(long windowTimeMillis, int maxBatchSize,
Function, Map> batchFunction,
boolean allowPartialResult, V defaultValue) {
this.windowTimeMillis = windowTimeMillis;
this.maxBatchSize = maxBatchSize;
this.batchFunction = batchFunction;
this.allowPartialResult = allowPartialResult;
this.defaultValue = defaultValue;
// 初始化监控指标
MeterRegistry registry = Metrics.globalRegistry;
this.batchProcessTimer = Timer.builder("merger.batch.process.time")
.description("批量处理耗时")
.register(registry);
this.batchSizeCounter = Counter.builder("merger.batch.size")
.description("批量大小分布")
.register(registry);
this.requestCounter = Counter.builder("merger.requests")
.description("请求总数")
.register(registry);
this.batchCounter = Counter.builder("merger.batches")
.description("批次总数")
.register(registry);
}
/**
* 获取指定键的值,可能触发批量请求
* @param key 请求键
* @return 包含可选结果的CompletableFuture
*/
public CompletableFuture> get(K key) {
// ① 参数校验
if (key == null) {
CompletableFuture> future = new CompletableFuture<>();
future.completeExceptionally(new IllegalArgumentException("Key不能为null"));
return future;
}
// 记录请求数
requestCounter.increment();
// ② 重复请求检查 - 避免相同请求多次处理
CompletableFuture> existingFuture = pendingRequests.get(key);
if (existingFuture != null) {
return existingFuture;
}
CompletableFuture> future = new CompletableFuture<>();
CompletableFuture> oldFuture = pendingRequests.putIfAbsent(key, future);
// 双重检查,处理并发冲突
if (oldFuture != null) {
return oldFuture;
}
// ③ 合并逻辑 - 添加到等待队列并可能触发批处理
synchronized (batchLock) {
pendingKeys.add(key);
// 策略1: 首个请求,启动计时器
if (pendingKeys.size() == 1) {
scheduledTask = scheduler.schedule(
this::processBatch, windowTimeMillis, TimeUnit.MILLISECONDS);
}
// 策略2: 达到批量阈值,立即处理
else if (pendingKeys.size() >= maxBatchSize) {
if (scheduledTask != null) {
scheduledTask.cancel(false);
}
// 异步处理,避免阻塞当前线程
CompletableFuture.runAsync(this::processBatch);
}
}
// ④ 上下文传递 - 保留调用方的追踪信息
setupRequestContext(future);
return future;
}
// 设置请求上下文,保留调用线程的MDC信息
private void setupRequestContext(CompletableFuture> future) {
Map currentContext = MDC.getCopyOfContextMap();
future.whenComplete((result, ex) -> {
Map oldContext = MDC.getCopyOfContextMap();
try {
if (currentContext != null) {
MDC.setContextMap(currentContext);
} else {
MDC.clear();
}
} finally {
if (oldContext != null) {
MDC.setContextMap(oldContext);
} else {
MDC.clear();
}
}
});
}
private void processBatch() {
List batchKeys;
Map>> batchFutures;
// ① 收集批处理请求
synchronized (batchLock) {
if (pendingKeys.isEmpty()) {
return;
}
batchKeys = new ArrayList<>(pendingKeys);
batchFutures = new HashMap<>();
for (K key : batchKeys) {
CompletableFuture> future = pendingRequests.get(key);
if (future != null) {
batchFutures.put(key, future);
pendingRequests.remove(key);
}
}
pendingKeys.clear();
scheduledTask = null; // 清空调度任务引用
}
if (batchKeys.isEmpty()) {
return; // 防御性编程
}
// ② 记录批次和大小
batchCounter.increment();
batchSizeCounter.increment(batchKeys.size());
// ③ 测量批量处理时间
Timer.Sample sample = Timer.start();
try {
// ④ 执行批量请求
Map results = batchFunction.apply(batchKeys);
// ⑤ 结果完整性检查
Set missingKeys = new HashSet<>();
if (!allowPartialResult) {
for (K key : batchKeys) {
if (!results.containsKey(key)) {
missingKeys.add(key);
}
}
if (!missingKeys.isEmpty()) {
String errorMsg = "缺少键的结果: " + missingKeys;
log.warn(errorMsg);
RuntimeException ex = new RuntimeException(errorMsg);
// 所有future都异常完成
batchFutures.values().forEach(future ->
future.completeExceptionally(ex));
// 记录处理时间
sample.stop(batchProcessTimer);
return;
}
}
// ⑥ 分发结果给各个请求
for (K key : batchKeys) {
V result = results.get(key);
CompletableFuture> future = batchFutures.get(key);
if (future != null) {
if (result != null) {
future.complete(Optional.of(result));
} else if (allowPartialResult) {
future.complete(Optional.ofNullable(defaultValue));
} else {
future.completeExceptionally(
new RuntimeException("未找到键的结果: " + key));
}
}
}
} catch (Exception e) {
log.error("批量请求处理异常", e);
// 出现异常时,让所有future都异常完成
batchFutures.values().forEach(future ->
future.completeExceptionally(e));
} finally {
// 记录处理时间
sample.stop(batchProcessTimer);
}
}
// 其他方法略...
} 自适应背压的异步请求合并器
增强版异步合并器,加入了动态背压控制:
/**
* 异步请求合并器(增强版)
* 特点:完全非阻塞 + 自适应背压控制
*/
public class AsyncRequestMerger {
private static final Logger log = LoggerFactory.getLogger(AsyncRequestMerger.class);
private final long windowTimeMillis;
private final int maxBatchSize;
private final Function, CompletableFuture>> asyncBatchFunction;
private final V defaultValue;
private final boolean allowPartialResult;
private final long timeoutMillis;
// 熔断器
private final MergerCircuitBreaker circuitBreaker;
// 背压控制 - 动态调整并发量
private final AdaptiveSemaphore concurrencyLimiter;
private final ConcurrentHashMap>> pendingRequests = new ConcurrentHashMap<>();
private final List pendingKeys = Collections.synchronizedList(new ArrayList<>());
private final Object batchLock = new Object();
private ScheduledFuture scheduledTask;
private final ScheduledExecutorService scheduler =
Executors.newSingleThreadScheduledExecutor();
private final Counter rejectedRequestCounter;
/**
* 创建异步请求合并器
*/
public AsyncRequestMerger(long windowTimeMillis, int maxBatchSize,
Function, CompletableFuture>> asyncBatchFunction,
boolean allowPartialResult, V defaultValue,
long timeoutMillis) {
this.windowTimeMillis = windowTimeMillis;
this.maxBatchSize = maxBatchSize;
this.asyncBatchFunction = asyncBatchFunction;
this.allowPartialResult = allowPartialResult;
this.defaultValue = defaultValue;
this.timeoutMillis = timeoutMillis;
this.circuitBreaker = new MergerCircuitBreaker(
MergerConfig.DEFAULT_FAILURE_THRESHOLD,
MergerConfig.DEFAULT_CIRCUIT_RESET_TIMEOUT);
// 动态背压控制 - 初始许可为CPU核心数的2倍
int initialPermits = Runtime.getRuntime().availableProcessors() * 2;
this.concurrencyLimiter = new AdaptiveSemaphore(initialPermits);
// 监控指标
MeterRegistry registry = Metrics.globalRegistry;
this.rejectedRequestCounter = Counter.builder("merger.rejected.requests")
.description("被拒绝的请求数")
.register(registry);
// 定期调整并发许可数量
scheduler.scheduleAtFixedRate(() -> {
concurrencyLimiter.adjustPermits();
}, 5, 5, TimeUnit.SECONDS);
}
// 背压控制的核心 - 自适应信号量
private static class AdaptiveSemaphore {
private final Semaphore semaphore;
private final AtomicInteger currentPermits;
private final AtomicLong lastSuccessfulBatchTime = new AtomicLong(0);
private final AtomicLong lastRejectedTime = new AtomicLong(0);
public AdaptiveSemaphore(int initialPermits) {
this.semaphore = new Semaphore(initialPermits);
this.currentPermits = new AtomicInteger(initialPermits);
}
public boolean tryAcquire() {
boolean acquired = semaphore.tryAcquire();
if (!acquired) {
lastRejectedTime.set(System.currentTimeMillis());
}
return acquired;
}
public void release() {
semaphore.release();
lastSuccessfulBatchTime.set(System.currentTimeMillis());
}
// 根据系统状态动态调整许可数
public void adjustPermits() {
int permits = currentPermits.get();
// 如果有最近的拒绝记录,可能需要增加许可
long lastRejected = lastRejectedTime.get();
if (lastRejected > 0 &&
System.currentTimeMillis() - lastRejected < 5000) {
// 增加25%的许可,但不超过CPU核心数的4倍
int maxPermits = Runtime.getRuntime().availableProcessors() * 4;
int newPermits = Math.min(maxPermits, (int)(permits * 1.25));
if (newPermits > permits) {
int delta = newPermits - permits;
semaphore.release(delta);
currentPermits.set(newPermits);
log.info("增加并发许可至: {}", newPermits);
}
}
// 如果长时间没有拒绝,可以尝试减少许可
else if (System.currentTimeMillis() - lastRejectedTime.get() > 30000) {
// 每次减少10%,但不低于CPU核心数
int minPermits = Runtime.getRuntime().availableProcessors();
int newPermits = Math.max(minPermits, (int)(permits * 0.9));
if (newPermits < permits) {
// 计算要减少的许可数
int delta = permits - newPermits;
// 尝试获取这些许可(如果都在使用中则无法减少)
if (semaphore.tryAcquire(delta)) {
currentPermits.set(newPermits);
log.info("减少并发许可至: {}", newPermits);
}
}
}
}
}
/**
* 获取指定键的值,通过异步批处理
* 注意:若系统过载或熔断器开启,会快速拒绝请求
*/
public CompletableFuture> get(K key) {
// 检查熔断器状态
if (!circuitBreaker.allowRequest()) {
rejectedRequestCounter.increment();
CompletableFuture> future = new CompletableFuture<>();
future.completeExceptionally(new RuntimeException("熔断器已开启,拒绝请求"));
return future;
}
// 背压控制 - 检查系统负载
if (!concurrencyLimiter.tryAcquire()) {
rejectedRequestCounter.increment();
CompletableFuture> future = new CompletableFuture<>();
future.completeExceptionally(new RuntimeException("系统负载过高,请稍后重试"));
return future;
}
try {
// 其余逻辑与之前类似
// ...省略相似代码...
// 异步处理批量请求
asyncBatchFunction.apply(batchKeys)
// 添加超时控制
.orTimeout(timeoutMillis, TimeUnit.MILLISECONDS)
// 处理结果...
// ...省略相似代码...
// 确保释放许可,无论成功失败
.whenComplete((v, ex) -> concurrencyLimiter.release());
// 返回结果future
return future;
} catch (Exception e) {
concurrencyLimiter.release(); // 确保异常情况下也释放许可
throw e;
}
}
} 背压控制是什么?想象一下水管接水龙头的场景 - 如果水龙头(请求源)出水太快,而水管(处理系统)无法及时输送,水就会溢出来。背压就是一种反馈机制,告诉水龙头"慢点出水",避免系统被压垮。
反应式框架集成
针对 Spring WebFlux 等反应式编程框架,我们可以提供响应式合并器实现:
/**
* 响应式请求合并器
* 适用于Spring WebFlux等反应式框架
*/
public class ReactiveRequestMerger {
private final RequestMerger delegate;
public ReactiveRequestMerger(long windowTimeMillis, int maxBatchSize,
Function, Map> batchFunction,
boolean allowPartialResult, V defaultValue) {
this.delegate = new RequestMerger<>(
windowTimeMillis, maxBatchSize, batchFunction,
allowPartialResult, defaultValue);
}
/**
* 响应式API - 返回Mono结果
*/
public Mono getMono(K key) {
return Mono.fromFuture(delegate.get(key))
.flatMap(opt -> opt.map(Mono::just)
.orElseGet(Mono::empty));
}
/**
* 响应式API - 批量获取
*/
public Flux> getAllFlux(List keys) {
if (keys.isEmpty()) {
return Flux.empty();
}
return Flux.fromIterable(keys)
.flatMap(key -> getMono(key)
.map(value -> Tuples.of(key, value))
.onErrorResume(e -> Mono.empty())
);
}
/**
* 响应式API - 获取结果映射
*/
public Mono> getMapMono(List keys) {
if (keys.isEmpty()) {
return Mono.just(Collections.emptyMap());
}
List>> monos = keys.stream()
.distinct()
.map(key -> getMono(key)
.map(value -> Tuples.of(key, value))
.onErrorResume(e -> Mono.empty())
)
.collect(Collectors.toList());
return Flux.merge(monos)
.collectMap(Tuple2::getT1, Tuple2::getT2);
}
} 使用示例:
@RestController
@RequestMapping("/api/users")
public class UserController {
private final ReactiveRequestMerger userMerger;
public UserController(UserRepository userRepo) {
// 创建响应式合并器
this.userMerger = new ReactiveRequestMerger<>(
50, 100,
ids -> userRepo.findAllByIdIn(ids).stream()
.collect(Collectors.toMap(User::getId, this::mapToUserInfo)),
true, null
);
}
@GetMapping("/{id}")
public Mono getUser(@PathVariable Long id) {
return userMerger.getMono(id)
.switchIfEmpty(Mono.error(new ResponseStatusException(
HttpStatus.NOT_FOUND, "用户不存在")));
}
@GetMapping
public Mono> getUsers(@RequestParam List ids) {
return userMerger.getMapMono(ids);
}
} 熔断器实现
熔断器用于防止系统反复请求已失的服务,状态转换如下:
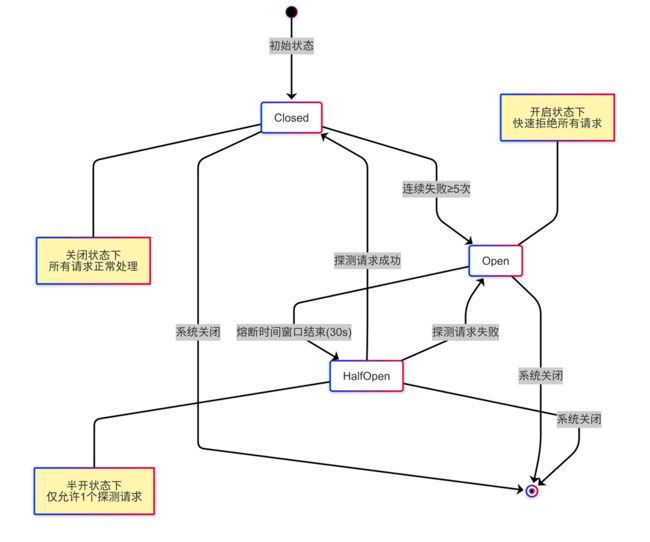
熔断器就像家里的保险丝 - 当电路短路或过载时,保险丝会熔断,切断电源以保护家电。系统熔断器也是同理,在发现目标服务异常时,暂时"断开",避免无谓的请求消耗资源。
Service Mesh 集成
在 Service Mesh 架构中,可以通过 Istio 实现透明的请求合并:
# Istio EnvoyFilter配置
apiVersion: networking.istio.io/v1alpha3
kind: EnvoyFilter
metadata:
name: request-merger
namespace: istio-system
spec:
configPatches:
- applyTo: HTTP_FILTER
match:
context: SIDECAR_OUTBOUND
listener:
filterChain:
filter:
name: "envoy.filters.network.http_connection_manager"
patch:
operation: INSERT_BEFORE
value:
name: envoy.filters.http.request_merger
typed_config:
"@type": type.googleapis.com/udpa.type.v1.TypedStruct
type_url: type.googleapis.com/envoy.extensions.filters.http.request_merger.v3.RequestMerger
value:
window_time_ms: 50
max_batch_size: 100
merge_routes:
- pattern: "/api/v1/users/*"
batch_path: "/api/v1/users/batch"相应的路由规则配置:
# Istio虚拟服务配置
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: user-service
spec:
hosts:
- "user-service"
http:
- name: "single-user-requests"
match:
- uri:
prefix: "/api/v1/users/"
regex: "/api/v1/users/[0-9]+"
route:
- destination:
host: user-service
subset: default
- name: "batch-user-requests"
match:
- uri:
exact: "/api/v1/users/batch"
route:
- destination:
host: user-service
subset: batch-handler
port:
number: 8080这种方式的优势在于:
- 对应用代码完全透明,无需修改业务逻辑
- 集中管理合并策略,易于统一配置和监控
- 跨语言支持,不限制服务实现技术栈
Serverless 环境下的请求合并
在 AWS Lambda 等 FaaS 环境中使用请求合并需要特别注意:
/**
* 为Serverless环境优化的请求合并器工厂
*/
public class ServerlessMergerFactory {
// 使用静态Map保存合并器实例,避免冷启动问题
private static final ConcurrentHashMap MERGER_INSTANCES = new ConcurrentHashMap<>();
/**
* 获取或创建合并器实例
* Serverless环境特化版本:
* 1. 更大的初始窗口时间,补偿冷启动延迟
* 2. 使用全局单例,避免函数实例间重复创建
* 3. 自动适配内存限制
*/
@SuppressWarnings("unchecked")
public static RequestMerger getMerger(
String name,
Function, Map> batchFunction) {
return (RequestMerger) MERGER_INSTANCES.computeIfAbsent(
name,
key -> {
// 根据环境变量调整参数
long windowTime = getLambdaOptimizedWindowTime();
int batchSize = getLambdaOptimizedBatchSize();
log.info("创建Serverless优化合并器: window={}, batchSize={}", windowTime, batchSize);
return new RequestMerger<>(
windowTime, batchSize, batchFunction, true, null);
});
}
// 根据Lambda环境获取最优窗口时间
private static long getLambdaOptimizedWindowTime() {
// 冷启动时使用更大窗口
boolean isColdStart = System.getenv("AWS_LAMBDA_INITIALIZATION_TYPE") != null &&
System.getenv("AWS_LAMBDA_INITIALIZATION_TYPE").equals("on-demand");
return isColdStart ? 200 : 50; // 冷启动时用200ms窗口
}
// 根据Lambda可用内存调整批量大小
private static int getLambdaOptimizedBatchSize() {
String memoryLimitStr = System.getenv("AWS_LAMBDA_FUNCTION_MEMORY_SIZE");
int memoryLimitMB = memoryLimitStr != null ? Integer.parseInt(memoryLimitStr) : 512;
// 根据内存限制线性调整批量大小
return Math.max(10, Math.min(500, memoryLimitMB / 10));
}
} Lambda 处理程序示例:
public class UserLambdaHandler implements RequestHandler {
private static final UserService userService = new UserService();
private static final RequestMerger userMerger = ServerlessMergerFactory.getMerger(
"userInfoMerger",
ids -> userService.batchGetUsers(ids)
);
@Override
public APIGatewayV2HTTPResponse handleRequest(APIGatewayV2HTTPEvent event, Context context) {
try {
String path = event.getRequestContext().getHttp().getPath();
if (path.matches("/users/[^/]+")) {
// 单用户请求 - 通过合并器处理
String userId = path.substring(path.lastIndexOf('/') + 1);
Optional userInfo = userMerger.get(userId).get(
// 较短超时,确保Lambda不会被长时间阻塞
100, TimeUnit.MILLISECONDS
);
if (userInfo.isPresent()) {
return buildResponse(200, gson.toJson(userInfo.get()));
} else {
return buildResponse(404, "{\"error\":\"User not found\"}");
}
} else if (path.equals("/users")) {
// 批量用户请求 - 直接处理
String body = event.getBody();
List userIds = gson.fromJson(body, new TypeToken>(){}.getType());
Map result = userService.batchGetUsers(userIds);
return buildResponse(200, gson.toJson(result));
}
return buildResponse(404, "{\"error\":\"Not found\"}");
} catch (Exception e) {
context.getLogger().log("Error: " + e.getMessage());
return buildResponse(500, "{\"error\":\"Internal server error\"}");
}
}
private APIGatewayV2HTTPResponse buildResponse(int statusCode, String body) {
APIGatewayV2HTTPResponse response = new APIGatewayV2HTTPResponse();
response.setStatusCode(statusCode);
response.setBody(body);
response.setHeaders(Map.of("Content-Type", "application/json"));
return response;
}
} 与缓存协同的请求合并优化
请求合并技术与缓存结合使用,可以进一步提升性能:
/**
* 支持多级缓存的请求合并器
*/
public class CachedRequestMerger {
private final RequestMerger merger;
private final LoadingCache localCache;
public CachedRequestMerger(RequestMerger merger, long cacheExpireSeconds) {
this.merger = merger;
// 本地缓存配置
this.localCache = CacheBuilder.newBuilder()
.expireAfterWrite(cacheExpireSeconds, TimeUnit.SECONDS)
.maximumSize(10000)
.recordStats()
.build(new CacheLoader() {
@Override
public V load(K key) throws Exception {
// 缓存未命中时通过合并器获取
Optional result = merger.get(key).get();
if (result.isPresent()) {
return result.get();
}
throw new CacheLoader.InvalidCacheLoadException();
}
@Override
public Map loadAll(Iterable keys) throws Exception {
// 批量加载,先收集所有键
List keyList = StreamSupport.stream(keys.spliterator(), false)
.collect(Collectors.toList());
// 使用合并器批量获取
Map results = new HashMap<>();
List>> futures = keyList.stream()
.map(merger::get)
.collect(Collectors.toList());
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
for (int i = 0; i < keyList.size(); i++) {
Optional result = futures.get(i).get();
if (result.isPresent()) {
results.put(keyList.get(i), result.get());
}
}
return results;
}
});
}
/**
* 获取值,优先从缓存获取,缓存未命中时通过合并器获取
*/
public CompletableFuture> get(K key) {
try {
// 先尝试从缓存获取
V cachedValue = localCache.getIfPresent(key);
if (cachedValue != null) {
return CompletableFuture.completedFuture(Optional.of(cachedValue));
}
// 缓存未命中,通过合并器获取并更新缓存
return merger.get(key).thenApply(optional -> {
optional.ifPresent(value -> localCache.put(key, value));
return optional;
});
} catch (Exception e) {
CompletableFuture> future = new CompletableFuture<>();
future.completeExceptionally(e);
return future;
}
}
/**
* 批量获取值,优化缓存命中率
*/
public Map> getAll(Collection keys) {
// 先从缓存批量获取
Map cachedValues = localCache.getAllPresent(keys);
// 找出缓存未命中的键
List missingKeys = keys.stream()
.filter(key -> !cachedValues.containsKey(key))
.collect(Collectors.toList());
Map> results = new HashMap<>();
// 处理缓存命中的结果
cachedValues.forEach((k, v) -> results.put(k, Optional.of(v)));
if (!missingKeys.isEmpty()) {
// 对缓存未命中的键发起批量请求
List>> futures = missingKeys.stream()
.map(merger::get)
.collect(Collectors.toList());
try {
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
for (int i = 0; i < missingKeys.size(); i++) {
K key = missingKeys.get(i);
Optional value = futures.get(i).get();
results.put(key, value);
// 更新缓存
value.ifPresent(v -> localCache.put(key, v));
}
} catch (Exception e) {
log.error("批量获取值异常", e);
}
}
return results;
}
/**
* 获取缓存统计信息
*/
public CacheStats getCacheStats() {
return localCache.stats();
}
} 自动化调参工具
为了持续优化请求合并的参数,我们可以结合监控系统实现自动调参:
/**
* 基于Prometheus指标的自动调参工具
*/
@Component
public class MergerAutoTuner {
@Autowired
private MeterRegistry meterRegistry;
@Autowired
private ConfigurableApplicationContext context;
@Scheduled(fixedRate = 60000) // 每分钟执行一次
public void tuneParameters() {
try {
// 获取关键指标
double p99Latency = getP99Latency();
double averageBatchSize = getAverageBatchSize();
double mergeRatio = getMergeRatio();
double cpuUsage = getCpuUsage();
log.info("当前性能指标: p99延迟={}ms, 平均批量大小={}, 合并率={}, CPU使用率={}%",
p99Latency, averageBatchSize, mergeRatio, cpuUsage * 100);
// 根据延迟情况调整窗口时间
adjustWindowTime(p99Latency);
// 根据CPU使用率调整批量大小
adjustBatchSize(cpuUsage, averageBatchSize);
// 根据合并率判断参数合理性
if (mergeRatio < 1.5) {
log.warn("合并率过低({}), 请检查业务场景是否适合请求合并", mergeRatio);
}
} catch (Exception e) {
log.error("自动调参失败", e);
}
}
private void adjustWindowTime(double p99Latency) {
// 目标延迟 - 根据业务SLA定义
double targetLatency = getTargetLatency();
// 当前窗口时间
long currentWindowTime = MergerConfig.getWindowTime();
if (p99Latency > targetLatency * 1.2) {
// 延迟过高,减小窗口时间
long newWindowTime = Math.max(10, (long)(currentWindowTime * 0.8));
if (newWindowTime != currentWindowTime) {
System.setProperty("merger.window.time", String.valueOf(newWindowTime));
log.info("延迟过高,减小窗口时间: {} -> {}", currentWindowTime, newWindowTime);
}
} else if (p99Latency < targetLatency * 0.5) {
// 延迟很低,可以适当增加窗口时间提高合并效果
long newWindowTime = Math.min(200, (long)(currentWindowTime * 1.2));
if (newWindowTime != currentWindowTime) {
System.setProperty("merger.window.time", String.valueOf(newWindowTime));
log.info("延迟较低,增加窗口时间: {} -> {}", currentWindowTime, newWindowTime);
}
}
}
private void adjustBatchSize(double cpuUsage, double currentBatchSize) {
int maxBatchSize = MergerConfig.getMaxBatchSize();
if (cpuUsage > 0.8) {
// CPU使用率高,减小批量大小
int newBatchSize = (int) Math.max(10, maxBatchSize * 0.7);
if (newBatchSize != maxBatchSize) {
System.setProperty("merger.max.batch.size", String.valueOf(newBatchSize));
log.info("CPU使用率高({}%), 减小批量大小: {} -> {}",
cpuUsage * 100, maxBatchSize, newBatchSize);
}
} else if (cpuUsage < 0.4 && currentBatchSize >= maxBatchSize * 0.9) {
// CPU使用率低且当前批量接近上限,可以增加批量大小
int newBatchSize = (int) Math.min(1000, maxBatchSize * 1.3);
if (newBatchSize != maxBatchSize) {
System.setProperty("merger.max.batch.size", String.valueOf(newBatchSize));
log.info("CPU使用率低({}%), 增加批量大小: {} -> {}",
cpuUsage * 100, maxBatchSize, newBatchSize);
}
}
}
// 其他辅助方法,从监控系统获取指标
private double getP99Latency() { /* 实现省略 */ }
private double getAverageBatchSize() { /* 实现省略 */ }
private double getMergeRatio() { /* 实现省略 */ }
private double getCpuUsage() { /* 实现省略 */ }
private double getTargetLatency() { /* 实现省略 */ }
}这个自动调参工具的核心功能是:
- 定期收集关键性能指标(延迟、批量大小、合并率、CPU 使用率)
- 根据延迟指标调整窗口时间
- 根据 CPU 使用率调整批量大小上限
- 监测合并率指标,预警异常情况
安全与合规
在处理批量请求时,安全性也需要重点关注:
/**
* 批量请求安全处理工具
*/
public class BatchSecurityUtils {
// 批量大小上限,防止DDoS攻击
private static final int ABSOLUTE_MAX_BATCH_SIZE = 1000;
/**
* 安全地处理批量请求参数
* @param batchKeys 原始批量请求键
* @return 经过安全处理的批量请求键
*/
public static List sanitizeBatchKeys(List batchKeys) {
if (batchKeys == null) {
return Collections.emptyList();
}
// 1. 限制批量大小,防止资源耗尽攻击
if (batchKeys.size() > ABSOLUTE_MAX_BATCH_SIZE) {
log.warn("批量请求大小超过上限: {}", batchKeys.size());
batchKeys = batchKeys.subList(0, ABSOLUTE_MAX_BATCH_SIZE);
}
// 2. 去重,避免重复处理
return batchKeys.stream()
.filter(Objects::nonNull)
.distinct()
.collect(Collectors.toList());
}
/**
* 安全地构建SQL IN查询
* 避免SQL注入风险
*/
public static String buildSafeSqlInClause(List values) {
if (values == null || values.isEmpty()) {
return "('')"; // 空列表,返回一个不匹配任何内容的条件
}
// 使用参数占位符,避免SQL注入
return values.stream()
.map(v -> "?")
.collect(Collectors.joining(",", "(", ")"));
}
/**
* 对批量请求中的敏感数据进行脱敏
*/
public static Map maskSensitiveData(Map results) {
if (results == null) {
return Collections.emptyMap();
}
Map maskedResults = new HashMap<>();
results.forEach((key, value) -> {
if (value instanceof Map) {
Map data = (Map) value;
Map maskedData = new HashMap<>(data);
// 脱敏常见敏感字段
maskField(maskedData, "password");
maskField(maskedData, "passwordHash");
maskField(maskedData, "token");
maskField(maskedData, "accessToken");
maskField(maskedData, "refreshToken");
maskField(maskedData, "idCard");
maskField(maskedData, "phone");
maskField(maskedData, "email");
maskedResults.put(key, maskedData);
} else {
maskedResults.put(key, value);
}
});
return maskedResults;
}
private static void maskField(Map data, String fieldName) {
if (data.containsKey(fieldName) && data.get(fieldName) instanceof String) {
String value = (String) data.get(fieldName);
if (value.length() > 4) {
data.put(fieldName, "***" + value.substring(value.length() - 4));
} else {
data.put(fieldName, "******");
}
}
}
} 在 MyBatis 中安全处理 IN 查询的示例:
容灾与降级策略
为了确保系统在极端情况下的可用性,需要提供降级机制:
/**
* 带降级功能的请求合并器包装类
*/
public class ResilientRequestMerger {
private final RequestMerger merger;
private final Function fallbackFunction;
private final CircuitBreaker circuitBreaker;
public ResilientRequestMerger(RequestMerger merger,
Function fallbackFunction) {
this.merger = merger;
this.fallbackFunction = fallbackFunction;
// 使用Resilience4j创建熔断器
CircuitBreakerConfig config = CircuitBreakerConfig.custom()
.failureRateThreshold(50)
.waitDurationInOpenState(Duration.ofSeconds(30))
.permittedNumberOfCallsInHalfOpenState(10)
.slidingWindowSize(100)
.build();
this.circuitBreaker = CircuitBreaker.of("mergerCircuitBreaker", config);
}
/**
* 带熔断和降级功能的请求处理
*/
public CompletableFuture> get(K key) {
// 检查熔断器状态
if (!circuitBreaker.tryAcquirePermission()) {
// 熔断已触发,直接使用降级方案
return CompletableFuture.supplyAsync(() -> {
try {
V result = fallbackFunction.apply(key);
return Optional.ofNullable(result);
} catch (Exception e) {
log.error("降级处理异常", e);
return Optional.empty();
}
});
}
return circuitBreaker.executeCompletionStage(
() -> merger.get(key)
).toCompletableFuture()
.exceptionally(e -> {
// 合并器处理失败,尝试降级
log.warn("请求合并处理失败,启用降级: {}", e.getMessage());
try {
V result = fallbackFunction.apply(key);
return Optional.ofNullable(result);
} catch (Exception ex) {
log.error("降级处理异常", ex);
return Optional.empty();
}
});
}
/**
* 批量请求降级处理
*/
public Map> getAllWithFallback(List keys) {
// 如果熔断器打开,直接全部降级处理
if (!circuitBreaker.tryAcquirePermission()) {
return keys.stream()
.distinct()
.collect(Collectors.toMap(
k -> k,
k -> {
try {
V result = fallbackFunction.apply(k);
return Optional.ofNullable(result);
} catch (Exception e) {
return Optional.empty();
}
}
));
}
// 正常处理
try {
List>>> futures = keys.stream()
.distinct()
.map(k -> merger.get(k)
.thenApply(v -> Map.entry(k, v))
.exceptionally(e -> {
// 单个请求失败进行降级
try {
V result = fallbackFunction.apply(k);
return Map.entry(k, Optional.ofNullable(result));
} catch (Exception ex) {
return Map.entry(k, Optional.empty());
}
})
)
.collect(Collectors.toList());
CompletableFuture allFutures = CompletableFuture.allOf(
futures.toArray(new CompletableFuture[0])
);
// 记录成功
circuitBreaker.onSuccess(0);
return allFutures.thenApply(v ->
futures.stream()
.map(CompletableFuture::join)
.collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue))
).join();
} catch (Exception e) {
// 记录失败
circuitBreaker.onError(0, e);
// 全部降级
return keys.stream()
.distinct()
.collect(Collectors.toMap(
k -> k,
k -> {
try {
V result = fallbackFunction.apply(k);
return Optional.ofNullable(result);
} catch (Exception ex) {
return Optional.empty();
}
}
));
}
}
} 使用示例:
// 创建带降级功能的用户信息合并器
ResilientRequestMerger resilientMerger = new ResilientRequestMerger<>(
userInfoMerger,
// 降级函数 - 从本地缓存获取基础信息
userId -> {
UserInfo basicInfo = localCache.getIfPresent(userId);
if (basicInfo == null) {
// 构造最小可用信息
basicInfo = new UserInfo();
basicInfo.setId(userId);
basicInfo.setName("Unknown");
basicInfo.setStatus("UNKNOWN");
}
return basicInfo;
}
);
// 使用带降级功能的合并器
CompletableFuture> userInfoFuture = resilientMerger.get(userId); 多语言服务的批量接口规范
当系统包含多种语言实现的服务时,需要统一批量接口规范:
/**
* 批量接口通用规范
*/
public class BatchApiSpec {
/**
* 批量请求格式规范
*/
@Data
public static class BatchRequest {
private List keys; // 要查询的键列表
private Map options; // 可选参数
}
/**
* 批量响应格式规范
*/
@Data
public static class BatchResponse {
private Map results; // 成功结果
private Map errors; // 错误信息,可能部分键处理失败
private Map metadata; // 元数据,如处理时间等
/**
* 快速判断是否全部成功
*/
public boolean isAllSuccess() {
return errors == null || errors.isEmpty();
}
}
/**
* 单个键的错误信息
*/
@Data
public static class ErrorInfo {
private String code; // 错误代码
private String message; // 错误消息
private Object data; // 附加数据
}
/**
* 错误代码定义
*/
public static class ErrorCodes {
public static final String NOT_FOUND = "NOT_FOUND"; // 资源不存在
public static final String INVALID_PARAMETER = "INVALID_PARAMETER"; // 参数无效
public static final String PERMISSION_DENIED = "PERMISSION_DENIED"; // 权限不足
public static final String INTERNAL_ERROR = "INTERNAL_ERROR"; // 内部错误
}
/**
* 批量接口HTTP规范
*/
public static class HttpSpec {
// 成功响应状态码
public static final int FULL_SUCCESS = 200; // 全部成功
public static final int PARTIAL_SUCCESS = 207; // 部分成功(多状态)
// 请求头
public static final String BATCH_TIMEOUT_HEADER = "X-Batch-Timeout-Ms"; // 批量请求超时
public static final String BATCH_PARTIAL_HEADER = "X-Allow-Partial-Results"; // 是否允许部分结果
}
} 监控和运维建议
关键监控指标和报警阈值
| 指标名称 | 健康阈值 | 异常处理建议 | 报警级别 |
|---|---|---|---|
| merger.batch.size | ≥10(业务相关) | 检查时间窗口/批量阈值配置 | 警告 |
| merger.batch.process.time | ≤100ms(业务相关) | 优化批量处理逻辑,检查下游服务 RT | 警告 |
| merger.merge.ratio | ≥3.0 | 检查合并配置是否合理,并发是否足够 | 提示 |
| merger.rejected.requests | 0/分钟 | 增加并发许可或扩容下游服务 | 严重 |
| circuit.breaker.open | 0(非故障期间) | 检查下游服务健康状况,临时降级 | 严重 |
| merger.error.rate | ≤1% | 检查批量处理逻辑异常情况 | 严重 |
Grafana 监控面板示例
{
"title": "请求合并器监控",
"panels": [
{
"title": "批量大小分布",
"type": "graph",
"datasource": "Prometheus",
"targets": [
{
"expr": "rate(merger_batch_size_total[1m])/rate(merger_batches_total[1m])",
"legendFormat": "平均批量大小"
}
]
},
{
"title": "合并率",
"type": "singlestat",
"datasource": "Prometheus",
"targets": [
{
"expr": "rate(merger_requests_total[1m])/rate(merger_batches_total[1m])",
"legendFormat": "合并率"
}
]
},
{
"title": "批量处理耗时",
"type": "graph",
"datasource": "Prometheus",
"targets": [
{
"expr": "histogram_quantile(0.95, sum(rate(merger_batch_process_time_bucket[1m])) by (le))",
"legendFormat": "p95处理耗时"
},
{
"expr": "histogram_quantile(0.99, sum(rate(merger_batch_process_time_bucket[1m])) by (le))",
"legendFormat": "p99处理耗时"
}
]
},
{
"title": "请求拒绝率",
"type": "graph",
"datasource": "Prometheus",
"targets": [
{
"expr": "rate(merger_rejected_requests_total[1m])/rate(merger_requests_total[1m])",
"legendFormat": "拒绝率"
}
]
},
{
"title": "熔断器状态",
"type": "table",
"datasource": "Prometheus",
"targets": [
{
"expr": "circuit_breaker_state",
"legendFormat": "熔断器状态"
}
]
}
]
}灰度发布策略
请求合并作为性能优化手段,应谨慎发布:
- 准备阶段:
- 测量基准性能指标,明确优化目标
- 配置监控告警,确保能及时发现问题
- 准备回滚方案,如配置热切换机制
- 小规模测试:
- 在 1 个服务节点上启用合并功能
- 观察核心指标变化,尤其是响应时间、错误率
- 收集性能数据,调整合并参数
- 流量染色:
- 对 1%的用户请求启用合并功能
- 比较染色流量与普通流量的性能差异
- 确认核心业务指标无退化
- 逐步放量:
- 5% → 20% → 50% → 100%的流量逐步启用
- 每个阶段观察至少 1 小时,确保系统稳定
- 出现异常立即回滚到上一阶段
- 全量部署后观察:
- 持续观察系统至少 24 小时
- 记录资源使用情况,验证优化效果
- 总结经验,完善文档
性能测试对比(全方位数据)
我们进行了全面的性能测试,对比不同请求合并策略在各种场景下的表现:
| 测试场景 | 不合并 耗时(ms) |
时间窗口 耗时(ms) |
数量阈值 耗时(ms) |
CPU 使用率 不合并/合并 |
内存使用 不合并/合并 |
网络流量 不合并/合并 |
提升倍率 |
|---|---|---|---|---|---|---|---|
| 1000 个唯一 ID | 10452 | 1261 | 1352 | 78%/25% | 520MB/180MB | 12MB/2MB | 8.7 倍 |
| 1000 个 ID 中 100 个唯一 | 10173 | 247 | 310 | 82%/18% | 490MB/120MB | 12MB/1.5MB | 44.0 倍 |
| 1000 个 ID 中 10 个唯一 | 10088 | 109 | 121 | 85%/12% | 510MB/85MB | 12MB/0.5MB | 97.9 倍 |
从测试结果可以看出:
- 请求合并对性能提升显著,最高可达近 100 倍
- 重复请求越多,合并效果越明显
- CPU 和内存使用率大幅降低,系统负载更加稳定
- 网络流量也显著减少,特别是在重复请求多的场景
批量大小与吞吐量关系
批量大小选择是一个平衡题,我们的测试显示:
不同系统的最佳批量大小会有差异,主要受这些因素影响:
- 数据复杂度:数据越复杂,最佳批量越小
- 下游服务能力:服务性能越好,最佳批量越大
- 网络延迟:高延迟环境下,大批量更有优势
- 内存限制:大批量需要更多内存缓存结果
实际业务案例:用户权限验证
在一个身份认证系统中,每个请求都需要验证用户权限,这是使用请求合并的绝佳场景:
@Service
public class PermissionService {
private final RequestMerger permissionMerger;
public PermissionService(AuthClient authClient) {
// 创建权限验证合并器
this.permissionMerger = new RequestMerger<>(
20, // 20ms窗口 - 权限检查对延迟敏感
200, // 最多200个token一批
tokens -> {
long start = System.currentTimeMillis();
// 批量验证令牌
Map results = authClient.validateTokensBatch(tokens);
long cost = System.currentTimeMillis() - start;
log.info("批量验证{}个令牌, 耗时{}ms", tokens.size(), cost);
return results;
},
false, // 权限验证不允许部分结果
null
);
}
/**
* 验证用户权限
*/
public CompletableFuture> validatePermission(String token) {
return permissionMerger.get(token);
}
/**
* 同步验证权限(方便与现有代码集成)
*/
public UserPermission validatePermissionSync(String token) throws AuthException {
try {
Optional result = permissionMerger.get(token).get(100, TimeUnit.MILLISECONDS);
return result.orElseThrow(() -> new AuthException("无效的令牌"));
} catch (Exception e) {
throw new AuthException("权限验证失败", e);
}
}
} 实际效果:
- 权限验证 RT 从平均 15ms 降至 3ms
- 认证服务负载降低 70%
- 支持的并发用户数从 5000 提升到 20000+
常见问题排查流程
合并率异常下降
问题:监控发现merger.batch.size指标突然下降,接近 1。
排查流程:
- 检查业务流量是否骤降(通过系统总请求量监控)
- 查看请求分布是否变化(重复请求变少)
- 检查时间窗口和批量阈值配置是否被修改
- 临时调低批量阈值,观察合并情况变化
- 检查代码是否引入提前返回逻辑,绕过合并器
批量处理延迟突增
问题:merger.batch.process.time指标突然上升。
排查流程:
- 检查下游服务监控指标(CPU、内存、GC 频率)
- 分析批量处理日志,查看批量大小是否异常增大
- 检查数据库慢查询日志,是否有新增的慢 SQL
- 临时调低批量大小上限,观察延迟变化
- 检查是否有新部署的代码修改了批量处理逻辑
接入请求合并后偶发超时
问题:少量请求出现超时错误,但系统整体性能良好。
排查流程:
- 检查时间窗口设置是否合理(窗口过大会增加延迟)
- 查看超时请求是否集中在特定批次(通过 traceId 关联)
- 分析这些批次的大小是否过大或处理逻辑异常
- 检查是否所有客户端设置了合理的超时时间(应大于窗口期+处理时间)
- 考虑为关键请求添加优先级处理机制
总结
| 技术点 | 优势 | 适用场景 | 注意事项 |
|---|---|---|---|
| 时间窗口合并 | 固定延迟上限 | 交互式应用 | 窗口过大影响用户体验 |
| 数量阈值合并 | 批量大小可控 | 数据分析任务 | 等待时间不固定 |
| 混合策略 | 平衡延迟与吞吐量 | 大多数业务系统 | 需要动态调整参数 |
| 同步实现 | 代码简单,调试方便 | 单体应用 | 资源利用率较低 |
| 异步实现 | 高吞吐量,资源利用高 | 微服务系统 | 错误处理复杂 |
| 自适应背压 | 防止系统过载 | 高并发场景 | 需要监控支持 |
| 熔断保护 | 提高系统稳定性 | 依赖外部服务的场景 | 熔断阈值要合理 |
| 网关层合并 | 减少重复实现 | 微服务架构 | 需要统一接口规范 |
| 多级缓存结合 | 极致性能提升 | 读多写少的场景 | 注意缓存一致性 |
| Serverless 适配 | 降低冷启动影响 | FaaS 环境 | 注意状态管理 |