HDU 1403 Longest Common Substring(后缀自动机——附讲解 or 后缀数组)
Description
For example:
str1 = banana
str2 = cianaic
So the Longest Common Substring is "ana", and the length is 3.
Input
Process to the end of file.
Output
如果建立在学过AC自动机的基础上的话,下面的par(parent)指针大概就相当于AC自动机中的失配指针(我不知道叫什么,反正就是匹配失败用的那个……),也就是说一点p的失配指针所指向的点为p的最长后缀,这样就比较好说了。
然后新增一个结点np(w),之前的最后一个点,也就是last指针,必然需要接上w作为下一个点。而last的失配指针指向的点,都是从root走到last的字符串的后缀,都需要接上w。
如果某一点p没有到w的边,那么直接建边就好了。如果能一直走到root都没有w的边,那说明w第一次出现,那么np的失配指针就要指向root。
如果走到一个点p之后,p所指向的w已经有所属了(即!p->go[w]),那么我们不能直接删掉原来的边然后接到np上去(这样会丢失了一条边)。如果p->val + 1 == q->val(val为从root一直走走到某个点的步数,应该是算最长的那条边),那么可以直接让np的失配指针指向p->go[w]。
如果p->val + 1 != q->val,那么我们只能新建一个结点nq为q(p->go[w])的副本(把q的所有边(包括失配边)都复制到nq上),再把q和np的失配指针指向nq。nq->val = p->val + 1,把p的本来指向q的
所有后缀指向nq。
至于为什么要新增一个结点嘛,我想大概是因为如果直接用原来那个结点,会导致val的计算出问题,也就是失配指针所指向的东东不是真正的后缀(可以参考HDU1403看看后缀自动机是怎么用的O__O"…)
每次extend都至多增加两个点,空间复杂度为O(n),时间复杂度不会算,大概也是O(n)
1 #include <cstdio> 2 #include <algorithm> 3 #include <cstring> 4 using namespace std; 5 6 const int MAXN = 100000 + 10; 7 char buf[MAXN]; 8 struct State { 9 State *par, *go[26]; 10 int val;/* 11 State() : 12 par(0), val(0) { 13 memset(go, 0, sizeof go); 14 }*/ 15 }*root, *last; 16 State statePool[MAXN * 2], *cur; 17 18 void init() { 19 memset(statePool, 0, 2 * strlen(buf) * sizeof(State)); 20 cur = statePool; 21 root = last = cur++; 22 } 23 24 void extend(int w) { 25 State *p = last, *np = cur++; 26 np->val = p->val + 1; 27 while (p && !p->go[w]) 28 p->go[w] = np, p = p->par; 29 if (!p) np->par = root; 30 else { 31 State*q = p->go[w]; 32 if (p->val + 1 == q->val) np->par = q; 33 else { 34 State *nq = cur++; 35 memcpy(nq->go, q->go, sizeof q->go); 36 nq->val = p->val + 1; 37 nq->par = q->par; 38 q->par = nq; 39 np->par = nq; 40 while (p && p->go[w] == q) 41 p->go[w] = nq, p = p->par; 42 } 43 } 44 last = np; 45 } 46 47 int main() { 48 char *pt; 49 while(scanf("%s", buf) != EOF) { 50 init(); 51 for (pt = buf; *pt; ++pt) 52 extend(*pt - 'a'); 53 scanf("%s", buf); 54 State *t = root; 55 int l = 0, ans = 0; 56 for (pt = buf; *pt; ++pt) { 57 int w = *pt - 'a'; 58 if (t->go[w]) { 59 t = t->go[w]; 60 ++l; 61 } else { 62 while (t && !t->go[w]) t = t->par; 63 if (!t) l = 0, t = root; 64 else { 65 l = t->val + 1; 66 t = t->go[w]; 67 } 68 } 69 ans = max(ans, l); 70 } 71 printf("%d\n", ans); 72 } 73 return 0; 74 }
思路:后缀数组。用一个奇怪的字符连接两个字符串,求排名相邻但原来不在同一个字符串的后缀的最长公共前缀(LCP)。(前缀极大相似的字符串的rank一定是相邻的)
有关后缀数组可以查阅国家集训队论文,2004年许智磊的《后缀数组》和2009年罗穗骞的《后缀数组——处理字符串的有力工具》
1 #include <cstdio> 2 #include <cstring> 3 using namespace std; 4 5 #define MAXN 200005 6 char S[MAXN], s2[MAXN]; 7 int n, sa[MAXN], height[MAXN], rank[MAXN], tmp[MAXN], c[MAXN]; 8 int apart; 9 //rank[i] i的名次 10 //sa[i] 第i名的位置 11 //height[i] 第i名和第i-1名的LCP 12 void makesa(int m) { // O(MAXN * log MAXN) 13 int i, j, k; 14 memset(c, 0, m * sizeof(int)); 15 for(i = 0; i < n ; ++i) ++c[rank[i] = S[i]]; 16 for(i = 1; i < m; ++i) c[i] += c[i - 1]; 17 for(i = 0; i < n ; ++i) sa[--c[rank[i]]] = i; 18 for(k = 1; k < n; k <<= 1) { 19 for(i = 0; i < n; ++i) { 20 j = sa[i] - k; 21 if(j < 0) j += n; 22 tmp[c[rank[j]]++] = j; 23 } 24 sa[tmp[c[0] = 0]] = j = 0; 25 for(i = 1; i < n; i++) { 26 if(rank[tmp[i]] != rank[tmp[i-1]] || rank[tmp[i] + k] != rank[tmp[i - 1] + k]) 27 c[++j] = i; 28 sa[tmp[i]] = j; 29 } 30 memcpy(rank, sa, n * sizeof(int)); 31 memcpy(sa, tmp, n * sizeof(int)); 32 if(j >= n - 1) break; 33 } 34 } 35 36 void calheight() { 37 int i, j, k = 0; 38 for(i = 0; i < n; height[rank[i++]] = k) { 39 if(k > 0) --k; 40 for(j = sa[rank[i] - 1]; S[i + k] == S[j + k]; ++k) ; 41 } 42 } 43 44 int main() { 45 while(scanf("%s%s", S, s2) != EOF) { 46 apart = strlen(S); 47 strcat(S, "*"); 48 strcat(S, s2); 49 n = strlen(S); 50 makesa(1 << 8); 51 calheight(); 52 int ans = 0; 53 for (int i = 1; i < n; ++i) 54 if((sa[i - 1] < apart && sa[i] > apart) || (sa[i - 1] > apart && sa[i] < apart)) 55 if (height[i] > ans) ans = height[i]; 56 printf("%d\n",ans); 57 } 58 return 0; 59 }
以下转自:http://hi.baidu.com/myidea/item/142c5cd45901a51820e25039
首先CTSC只有Silver(注意不是Sliver.....被gyz吐槽了......捂),Day2第一题由于一直以来对01串很敏感,所以马上短路,认为是个神级DP题,要用到01串的各种性质,所以80分算法都没有打,不然就Gold了.
补一下后缀自动机,比较难懂,不管是FHQ的还是CLJ的(注:WC2012没去,名额限制啊),
感谢本校的Neroysq神犇的cnblog<后缀自动机初探>举了一个简单而且很有代表性的例子(FHQ的回文串太囧了)
这个例子就是aabbabd,以此构造后缀自动机(请耐心看,因为前面几步没有体现算法)
有几点要记得:
1.由一个接受态沿Parent往前走所到的状态也是接受态
2.一个节点及其父辈的代表的串有相同的后缀
1.首先神马都没有:

此时后缀只有一个就是空串:

红字表示此节点代表最长串的长度,一个节点可能代表多个串
2.现在构建"a"的自动机,就是下面这样
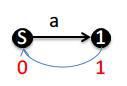
现在后缀变成了这样:

3.然后以上为基础构建"aa"的自动机
现在想一下,由S或者说0号节点可以接受的后缀为空串和"a"这两个,那么现在要将"aa"和"a"这两个后缀更新到后缀自动机中,那么1号节点的后缀"a"就要加入一个字符"a",而空串也要加入字符"a"
也就是所有之前的后缀都要在后面加入一个字符"a".
但是由于1号节点之前所代表的后缀"a"和1的Parent所代表的后缀(空串)+"a"代表的一样,所以,无需更新1及之前的可接受态
如下图:
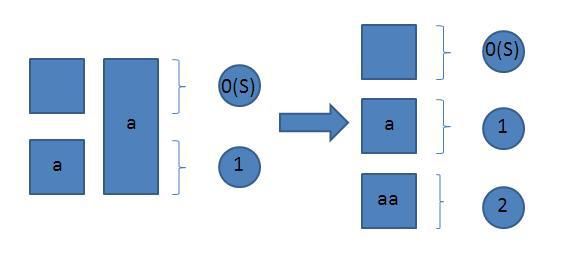
自动机就变成了如下:

3.更新自动机变成"aab"自动机
同上加所有接受态也要调整,就是在后面加上"b"字符:

这时,由于1,2节点无法代表三个后缀的任意一个,所以除空串的所有后缀都由3代替
这时3号节点和0号节点为接受态.
自动机成了这样:

具体过程是这样的:
S1:新建节点3
S2:找到最后一个后缀也就是最后一个接受态是节点2
S3:2号节点直接连向3,表示插入后缀"aab"
S4:向上找2的Parent,1号节点,向3连边,表示插入后缀"ab"
S5:找到S,连边,表示插入后缀"b".
S6:没有其他接受态了,那么3的上一个接受态为S,Parent[3]=S
4:更新成"aabb"的自动机
同理,在所有接受态后加上字符"b"
不过由于接受态0(S)的转移"b"已经存在,那么,由于不能破坏原来的中间态的转移,只能新建一个节点,来代替接受态0(S)的转移节点
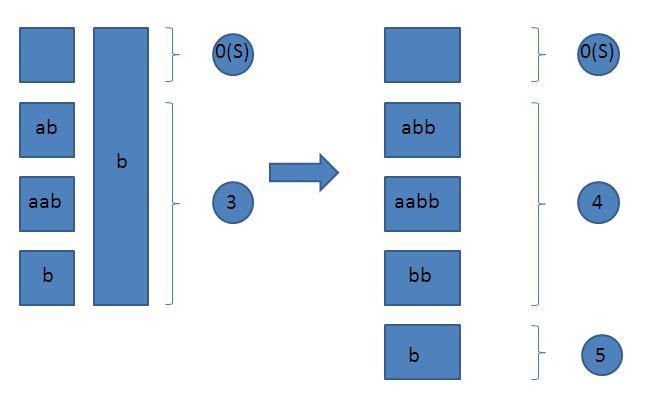
自动机成了这样:

找到0(S)时,发现转移"b"已经有节点占了,所以新建节点5,将3号所有信息Copy(包括Parent),然后更新len值,就是node[5]->len=node[5]->parent->len+1,所以5号节点可以代表后缀空串(0号代表的串)+字符"b"=后缀"b",节点3成了中间态,所以将节点为原接受态的节点指向3的转移改为指向5,这时,我们发现指向3的原接受态节点一定是当前节点0(S)及当前未访问的原接受态节点,所以可以直接沿着Parent往上更新.
然后节点5的Parent及祖先加入了现在的接受态
再次重申一点:一个节点及其父辈的代表的串有相同的后缀,且代表串长度递减,由于5号节点是接受态,所以他的父辈也是接受态,同时反过来也一样,与任意接受态拥有相同后缀的长度小于当前节点的未访问节点一定是当前节点的父辈,如与5号节点有相同后缀的长度小于5号节点的未访问的节点一定是5号的父辈,一定可以作为接受态.
因此为了维护这个性质,我们应该将3号节点的父亲重定义为5
到这里基本上应该明白了
就将剩下的构造过程放出来:
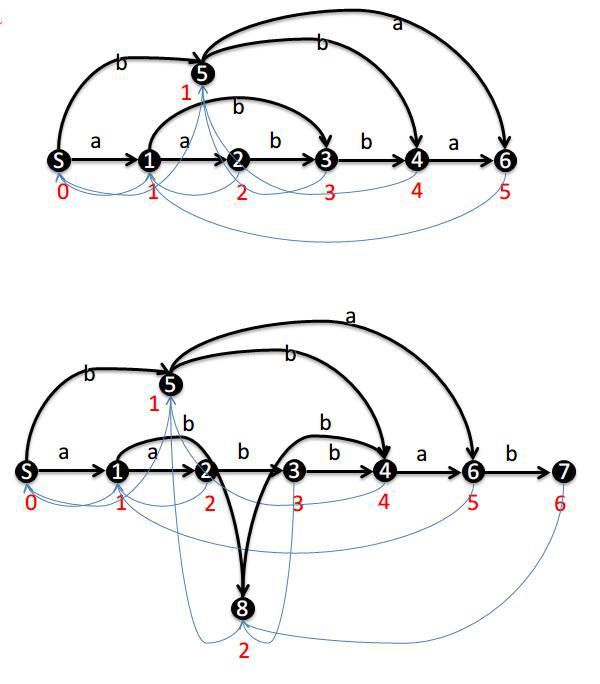

代码什么的如下:
插入一个节点:

意义:
当前新建节点为np,最后的接受态为tail,接受态指针p,pool是内存池,就是一个很大的数组,2*n的空间吧
init就是0号节点
Step 1:建立节点np,p指向tail,np的len更新
Step 2:沿着Parent寻找第一个有转移冲突的接受态节点并沿途更新转移
Step 3:
如果找不到,np的Parent更新为init.
如果正好冲突的节点长度为当前接受态节点那么np的Parent赋为冲突的节点.
否则,新建节点r,Copy冲突节点所有信息,更新r->len=p->len+1,将冲突节点的Parent和np的Parent赋为r,再往前更新与冲突节点有关的转移.
至此结束..........
个人感觉应该表达还算清楚吧(=.=)......