【课程笔记】华为 HCIA-Big Data 大数据 总结
目录
HDFS分布式文件系统
ZooKeeper分布式应用程序协调服务
HBase非关系型分布式数据库
Hive分布式数据仓库
ClickHouse列式数据库管理系统
MapReduce分布式计算框架
Yarn资源管理调度器
Spark分布式计算框架
Flink分布式计算框架
Flume日志采集工具
Kafka分布式消息队列
本课程主要围绕以下几个服务展开:
HDFS(Hadoop分布式文件系统)
ZooKeeper(分布式应用程序协调服务)
HBase(非关系型分布式数据库)
Hive(分布式数据仓库)
ClickHouse(列式数据库管理系统)
MapReduce(分布式计算框架)
Yarn(资源管理调度器)
Spark(分布式计算框架)
Flink(分布式计算框架)
Flume(日志采集工具)
Kafka(分布式消息队列)
它们之间的关系可以用下面这个图来进行总结概况: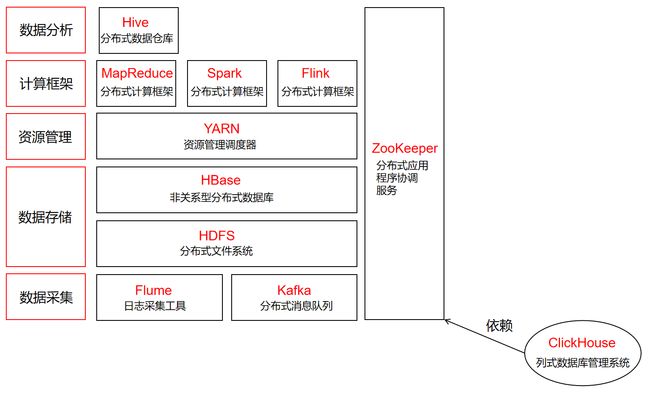
(1)OLAP:联机分析处理 OLTP:联机事务处理,同时成功或失败
(2)文件系统:由文件名、元数据Metadata、数据块Block组成
HDFS分布式文件系统
(1)Client:提供类似shell命令行访问HDFS中数据
(2)NameNode名称节点:存放元数据Metadata,负责管理命名空间Namespace(包含目录、文件和块),保存了Fslmage(NameNode启动会先加载到内存,而内存就是它)和EditLog(记录加载内存后文件的增删改查)
(3)DataNode数据节点:存放数据,以数据块Block存储
(4)ZooKeeper保障HDFS中NameNode的高可用性,传输心跳
(5)ZKFC监测Active节点是否正常,如果挂了能切换到Stand by节点
(6)Distributed FileSystem分布式文件系统
(7)FSData OutputStream和FSData IntputStream是流连接
ZooKeeper分布式应用程序协调服务
(1)安全认证依赖于KerberOS+LdapServer=令牌
(2)ZooKeeper集群由一组Server节点组成。Server节点由一个Leader节点(接受到数据变更请求,先写磁盘再写内存)和多个Follow节点组成
HBase非关系型分布式数据库
(1)HBase是分布式存储系统,利用HDFS作为其文件存储系统,提供分布式数据系统,而ZooKeeper是协同服务
(2)HBase数据模型(由表构成、列存储),有行键Row Key、列族、列、单元格cell、时间戳,数据类型是字节数组byte[ ](anchor(列族):aa.com(列))
(3)HMaster负责协调,只有一个。ZooKeeper会避免单点失效
(4)HRegionServer负责存,有多个。而HBase最基本单元就是Region(列族)
(5)HLog预写日志
(6)HRegion是工作节点,里面有MemStore(当数据刚存入或刚被读取会被当做热点数据存在"内存",为了高效)和StoreFile(数据持久化在磁盘,里面还有HFile用于对接HDFS,实际数据存储在HDFS)
(7)HBase有一个自己维护的meta表(包含Meta Region和User Region)
(8)Namespace命名空间包含Table表,再包含Region,再包含Store,再包含MemStore和StoreFile,而StoreFile包含Block对接HDFS
(9)Compaction机制减少同一个Region中同一个Column Family列族下的HFile数目。分Minor Compaction(小范围HFile合并)和Major Compaction(全局HFile合并)
(10)OpenScanner(读取过程会创建),分读取内存数据MemStore的为MemStoreScanner和读取磁盘数据HFile的StoreFileScanner
(11)BloomFilter用于查询数据是否存在。相当于在大表里查询某一格是否存在,若该格不存在则一定为空,若该格存在可能有误差,存的是别的数据,概率小
(12)Hindex二级索引,华为开发支持列索引,一般HBase是行
Hive分布式数据仓库
(1)Hive封装了MapReduce,可以用SQL调用它。数据存储在HDFS上
(2)ETL(提取、转换、加载数据到目标数据仓库)
(3)支持Tez、Spark等多种计算引擎
(4)Hive是离线数仓,不支持实时
(5)HiveServer是Hive的工作节点,并使用MetaStore存储元数据
(6)Hive的架构:接口层(Beeline、JDBC、Thrift、ODBC),访问层(Web Interface Web方式访问、Thrift Server 第三方方式访问),Driver层(Compiler编译、Optimizer自动优化、Executor执行,并由MetaStore作元数据管理),执行层(Tez、MapReduce、Spark计算引擎)
(7)Hive数据存储模型,存储在HDFS上:数据库database,在HDFS上是目录 -> 表,目录中的目录(分为托管表MANAGED_TABLE元数据和数据会被一起删除和外部表EXTERNAL_TABLE只删除元数据) -> 分区,表目录中的目录 -> 桶,文件 -> 倾斜数据和正常数据
(8)UDF(输入一条返回一条,都是用户自定义函数,内置函数也算)
(9)DDL数据定义语言(建表、修改表、删表、分区、数据类型),DML数据管理语言(数据导入、数据导出),DQL数据查询语言(简单查询、复杂查询)
ClickHouse列式数据库管理系统
(1)是OLAP(联机分析处理)的列式数据库,查询速度特别快,特别基于大宽表。支持SQL查询,主要引擎式MergeTree
(2)DBMS是数据库+管理系统
(3)ClickHouse应用场景分离线数据湖、实时数据湖、逻辑数据湖。CDC(增量数据采集)、Redis(非关系型数据库,流处理批处理都可以)、DLC(元数据管理)、ES(谷歌百度底层查询服务)
(4)ClickHouse架构有CLI(ClickHouseClient)客户端TCP访问、JDBC Driver(BalancedClickHouseDataSource)HTTPS访问、ClickHouseBalancer负载、ClickHouse Server工作节点、ZooKeeper的ZNodes提供冗余
(5)常见表引擎:TinyLog(小日志文件)、Memory(内存)、MergeTree(树型结构)、Replacing MergeTree(复制聚合树,支持副本机制)、Summing MergeTree(摘要聚合树)
(6)TTL(Time to Live,数据的存活时间到期自动删除),Data Skipping Index(二级索引,跳级索引,偏移量)
(7)分片:数据量很大时切分存储,数据不同;副本:复制了一份,数据完全相同
(8)原子性:Block数据块数据全部写入成功或失败;唯一性:避免重复写入,依靠Hash信息摘要
(9)分片机制:将一张表的数据水平切分到多个节点,不同节点之间数据不重复shard;分布式表:用于查询分片数据,通过分布式表进行查询。Replicate副本
(10)CV(用","分隔数据,支持表格打开)
MapReduce分布式计算框架
(1)Map是分而治,Reduce把处理完的结果进行统计合并
(2)用于大规模数据集的并行计算和离线计算
(3)Job计算任务
(4)Map阶段:数据所在计算,在一堆杂乱无章的数据提取key和value,也就是特征。(提取)会先将待处理文件分片,而每一分片就是一个数据块Block。Map()完后会放入环形内存缓冲区,并达到80%发生Spill溢写,溢出前会有Map Phase(partition分区、sort排序、combine合并可选、Merge归并)
(5)Shuffle一定规则放入=Map Shuffle+Reduce Shuffle,从环形内存缓冲区到Reduce归约之间都是Shuffle
(6)Reduce阶段:数据是以key后跟着的value来组织的,这些value是有相关性。(合并)Map()(Map Tesk)后成为MOF文件到本地磁盘,再对其进行排序和合并处理再给Reduce,这个过程Reduce Phase(Copy复制到缓存,Merge归并到磁盘,Reduce进行归约)
(7)WordCount就是Map Phase过程,最后Reduce主动找Map拉取数据
Yarn资源管理调度器
(1)ResourceManager主管理节点
(2)NodeManager从管理节点,每个都可以设置分配的内存和CPU。每个机器可以打标签
(3)ApplicationMaster运行程序的管理者,在从管理节点中,负责向调度器申请、释放资源
(4)Container容器,是Yarn资源抽象,任务最终跑的地方,一个容器只能运行一个Job
(5)Yarn的高可用通过引入ZooKeeper,对ResourceManager主管理节点进行解决单点失效,有一个Active和多个Stand by(HDFS的NameNode同样)
(6)Yarn APPMaster容错机制,是失败重启机制,重新启动ApplicationMaster来调度容器
(7)Scheduler调度器负责给应用分配资源,有FIFO Scheduler(先进先出调度器)、Capacity Scheduler(容器调度器)、Fair Scheduler(公平竞争调度器)。以队列为单位划分资源
Spark分布式计算框架
(1)应用场景:离线批处理、实时流处理、交互式查询
(2)ETL(抽取、转换、加载)
(3)Spark比MapReduce可以处理更大数据量,因为是基于内存计算
(4)RDD弹性分布式数据集,只可读不可修改,默认存储在内存,内存不足溢写到磁盘。具有血统机制Lineage,会溯源到源头重新计算,当数据丢失可快速进行数据恢复
(5)RDD的依赖关系:窄依赖每个父RDD的Partition分区最多被子RDD的一个Partition使用。没有数据交换,没有数据在网络间传输。宽依赖多个子RDD的Partition会依赖同一个父RDD的Partition,有数据交换,有数据在网络间传输,往往对应有shuffle操作
(6)RDD的Stage阶段划分,根据宽依赖划分
(7)RDD的操作类型(创建操作、转换操作只定义逻辑不执行、控制操作、行为操作)
(8)DataFrame也是弹性分布式数据集,只可读不可修改,底层是RDD。但它支持记录数据的结构信息即schema类似二维表格,还支持通过Spark Catalyst Optimiser进行默认优化
(9)DataSet,DataFrame是DataSet的特例为DataFrame=DataSet[ROW],有Dataset[Row]、Dataset[Car]、Dataset[Person]。是强类型
(10)Spark体系架构:①核心是Spark Core(RDD);②可以跑在Standalone、YARN、Mesos上面;③上层可以进行应用有Spark SQL(调用SQL,一般与Hive对比)、Structured Streaming(流式计算结构处理)、Spark Streaming(小批量流处理)、MLlib、GraphX(图论)、SparkR
(11)Spark SQL用于结构化数据处理的模型,可以无缝使用SQL语句或DataFrame API(Table API)对结构化数据进行查询
(12)Structured Streaming是构建在Spark SQL(当流式数据不断的产生时,Spark SQL将会增量的、持续不断处理数据,并将结构更新到数据集)引擎上的流式数据处理引擎
(13)Spark Streaming将实时输入数据流以时间片(秒级)为单位进行拆分,然后经Spark引擎以类似批处理的方式处理每个时间片数据(对一个时间段内的数据收集起来作为一个RDD再处理)。返回的数据类型时DStream。并有窗口在DStream滑动,并合并和操作落入窗口内的RDDs,产生窗口化的RDDs(窗口间隔和滑动间隔)。Spark Streaming经常与Storm(来一条数据处理一条数据)对比。Spark Streaming支持Checkpoint容错
Flink分布式计算框架
(1)Flink支持高吞吐和exactly-once语义(仅有一次,不多也不少)的实时计算
(2)Flink核心理念状态(之前计算的计算结构,因为是流计算,数据源源不断,需要用"状态"传递)状态管理(Flink内置了状态,不需要把它存储在外部系统)
(3)Flink Runtime流处理引擎整体架构:①APIs(DataStream API Stream Processing流处理、DataSet API Batch Processing批处理、对于关系型数据可以使用Table API和SQL查询);②Corn(Runtime Distributed Streaming DataFlow架构);③Deploy部署模式(Local Single JVM本地、Cluster Standalone,Yarn集群、Cloud,GCE EC2云);④Libraries应用(CEP Event Processing复杂编程、Table Relational关系型表计算、Flink ML Machine Learning机器学习、Gelly Graph Processing图论计算、Table Relational基于批处理表计算)
(4)Flink中用DataStream表示流数据(含有重复数据的不可修改集合)和DataSet表示批处理
(5)Flink程序由Source(负责数据读取)、Transformation(负责对数据转换)、Sink(负责最终数据输出),各部分之间流转的数据为流Stream
(6)Flink程序运行(计算角度):JobManager主节点,负责调度,也是作业管理器;TaskManager从节点,负责管理计算,也是任务管理器(还有资源管理器、分发器);Task Slot负责计算;Task最终运行的地方,在Task Slot里。(物理角度):主节点是master,工作节点(从)是worker
(7)JobClient是Flink程序和JobManager交互的桥梁
(8)在Flink有三类Operator分别为Source Operator(数据源操作)、Transformation Operator(数据转换操作)、Sink Operator(数据存储操作)。都是逻辑
(9)Flink基本数据模型是数据流。流是无边界的无限流,即流处理;流是有边界的有限流,即批处理(批处理是流处理的一种特殊情况)
(10)无状态处理:如果处理一个事件(或一条数据)的结果只跟事件本身的内容有关;有状态处理:如果还和之前处理过的事件有关联
(11)无界流:有定义流的开始,没有定义流的结束,必须持续处理;有界流:有定义流的开始,也定义流的结束,可以读取所有数据后再进行计算
(12)在事件流数据中,我们需要用key将事件分组,并且每隔一段时间就针对每一个key对应的事件计数
(13)processing time作为某个事件的时间,与数据无关,是系统时间。即事件被系统处理的时间
(14)event time是数据事件。即事件发生时的时间。携带TimeStamp时间戳
(15)ingestion time是Flume维护的数据时间。即事件到达流处理系统的时间
(16)Window是切割无限数据为有限块进行处理的手段。它将无限的stream拆分成有限大小的buckets桶
(17)Window类型:分为Count Window(数据驱动,计数与时间无关)和Time Window(时间驱动,按照时间生成Window)
(18)Time Window根据窗口分为:Tumbling Window滚动窗口(头对尾)、Sliding Window滑动窗口(头不对尾)、Session Window会话窗口
(19)乱序问题:流处理从事件产生流经source再到operator中间由于网络会导致乱序,导致Flink接收到的事件不是按照Event Time
(20)Watermark保证等一定时间发车,但算子如果延迟太久也不会被接收
(21)Watermark能保证基于event-time的窗口被销毁时已处理完所有数据。Watermark会携带一个单调递增的时间戳t,Watermark(t)表示所有时间戳不大于t的数据已经到来,未来小于等于t的数据不会再来,可以放心销毁窗口(Watermark策略是定期生成的)
(22)延迟事件:是乱序事件的特例,超过了水位线Watermark的预计,导致窗口在它们到达之前已经关闭
(23)延迟事件处理机制:重新激活已经关闭的窗口并重新计算以修正结果、将延迟事件收集起来另外处理、将延迟事件视为错误消息并丢弃。Flink默认的处理方式是第三种,其他两种分别使用Side Output和Allowed Lateness
(24)Side Output机制可以将延迟事件单独放入一个数据流分支,作为Window计算结果的副产品,以便用户获取并对其特殊处理。Allowed Lateness机制允许用户设置最大延迟时间,Flink会在窗口关闭后一直保存窗口状态直至超过允许延迟时间,这期间的延迟事件不会被丢弃而是默认触发窗口重新计算
(25)设置Allowed Lateness之后迟来的数据同样可以触发窗口,进行输出。再利用Side Output获取这些延迟的数据
(26)Flink提供三层API分别是DataStream API、DataSet API、Table API(类SQL)
(27)Checkpoint保证Flink的excatly-once,相当于快照,在出现故障时将系统重置回正确状态
(28)Flink会在输入的数据集上间隔性生成checkpoint barrier,通过栅栏(barrier)将间隔时间段内的数据划分到相应checkpoint中
(29)外部检查点:将状态数据保存在外部系统
(30)exactly-once:有且仅有一次。保证端到端数据一致性,数据要求高,不允许出现数据丢失和数据重复
(31)at-least-once:至少有一次。会一直发数据直至被接收,数据可能重复,适合时延和吞吐量要求高但对数据一致性要求不高的场景
(32)Savapoint也是保存数据,靠checkpoint实现。区别是checkpoint是自动恢复开始永远不停,由Flink自动触发并管理。而Savapoint是手动停止手动恢复,开始后可以停止升级或修改
(33)State Backend:用DataStream API编写的程序会以各种形式保存状态,在启动checkpoint机制时,状态会随着checkpoint而持久化,但状态内部的存储格式和状态存储在哪取决于State Backend 状态后端
(34)MemoryStateBackend存储基于内存
(35)FsStateBackend基于文件存储
(36)RocksDBStateBackend基于数据库RocksDB(内存+磁盘)存储
Flume日志采集工具
(1)本地文件spooling directory source从目录里采集新的文件内数据
(2)实时日志taildir从目录或文件中采集增量数据,exec执行Linux命令的结果被采集
(3)级联:多个Flume对接起来,合并数据的能力,用于远端本端
(4)Flume架构,节点Agent=Source+Channel+Sink
(5)在Flume传递的数据叫事件events,且为事务管理方式
(6)Source:负责接收events或通过特殊机制产生events,并将events批量放到一个或多个Channels,Source必须至少和一个Channel关联。驱动型Source(外部主动发送数据给Flume,驱动Flume接受数据);轮询Source(是Flume周期性主动去获取数据)
(7)Channel:作用类似队列,用于临时缓存进来的events,当Sink成功将events发送到下一跳的Channel或最终目的,events会从Channel移除。Memory Channel(不会持久化数据但最快、不安全);File Channel(基于WAL预写式日志Write-Ahead Log实现)对数据持久化,但需要配置数据目录和checkpoint目录,不同FileChannel均要配置一个checkpoint;JDBC Channel(基于嵌入式Database实现,可以简单取代File Channel)对数据持久化
(8)Sink:将events传输到下一跳或最终目的,成功完成后将events从Channel移除。Sink必须作用于一个确切的Channel
(9)多路复制:将数据复制了两份
(10)Flume支持使用MRS(MapReduce)服务监控
Kafka分布式消息队列
(1)Kafka强依赖ZooKeeper
(2)分布式消息队列:基于可靠的消息队列,在客户端应用和消息系统之间异步传递消息。分为点对点传递模式和发布-订阅模式
(3)点对点消息传递模式(一条消息只能被消费一次,被消费后会在队列中删除,该模式即使有多个消费者同时消费数据也能保证数据处理的顺序)
(4)发布-订阅消息传递模式(消息持久化到topic,消费者可以订阅一个或多个topic,消费者可以消费topic中所有数据,同一条数据可以被多个消费者消费,数据被消费后不会立马删除。消息生产者叫发布者,消费者叫订阅者)
(5)O(1):常量,不会随数据量变大导致处理时间变小
(6)Broker:Kafka的服务实例,可以动态添加(里有多个Partition)
(7)Topic:每条发布到Kafka集群的消息都要有类别、主题(里面是消息)
(8)Partition:Kafka把Topic分成一个或多个Partition分区,每个分区物理上对应文件夹
(9)Producer生产者:负责发布消息到Kafka Broker
(10)Consumer消费者:记录offset
(11)Consumer Group:每个消费者属于一个特定的Consumer Group,组内消费者对于数据是竞争的,组间消费者对于数据是共享
(12)offset偏移量:每条消息在文件夹中的位置
(13)offset存储机制:Consumer从Broker读取数据后可以选择commit,该操作会在Kafka保存该消费者在该Partition中读取的消息offset,在该消费者下次再读该Partition时会从下一条开始读,避免重复消费数据
(14)Replica:是Partition的副本,保障Partition分区的高可用
(15)Leader和Follow:在既有分区又有副本的情况下,对外提供服务只有一个。两者都是"Replica"的角色。Leader负责跟Producer和Consumer交互,而Follow从Leader复制数据。(拉取高水位线)
(16)Controller:Kafka集群中的服务器,用来对Leader的选举
(17)Partition里有一个或多个Replication副本,会分布在不同Broker,Partition分区的每个Replication副本在逻辑上抽象为一个日志Log对象,是一一对应的
(18)Broker挂了,这个Broker的分区不可以被消费,同时Producer不能写入
(19)ISR同步副本机制队列:如果Leader挂了,哪个Follow与主相同会优先变成Leader
(20)At most once 最多一次:消息可能丢失,消息不会重复发送和处理;At Least once 最少一次:消息不会丢失,消息可能会重复发送和处理;Exactly once 仅有一次:消息不会丢失,消息仅被处理一次
(21)幂等性:被执行多次造成的影响和只执行一次造成的影响一样。每发送给Kafka的消息都含有一个序列号,Broker使用这个序列号来删除重复数据。这个序列号被持久化到副本日志,即使分区的"Leader"挂了,其他Broker接管了Leader,新Leader仍可以判断重复发送的是否重复
(22)acks机制:Producer生产者需要Server接收到信号后返回确认信号,此项配置指Producer需要多少个这样的确认信号。acks=0,Producer不需要信号;acks=1,等Leader将数据写入本地Log,但没等所有Follow写入;acks=-1或all,Leader等所有备份都成功写入日志
(23)Kafka集群默认保留所有消息,存储168小时,因磁盘有限过了就删
(24)Kafka把Topic中的一个Partition分区从大文件拆成多个小文件段,通过多个小文件段就容易定期清除或删除已经消费完的文件,减少磁盘占用
(25)一批数据有".index"数据的偏移量和".log"是实际数据
(26)日志清理方式有两种:delete和compact(压缩,旧数据删除,key相同留下最大的values)
(27)清除的阈值有两种:过期的时间和分区内总日志大小
(28)Kafka不支持消息随机读取