Kettle 4.2源码分析第一讲--Kettle 简介
Pentaho Data Integration(PDI)简介
1. PDI结构简介
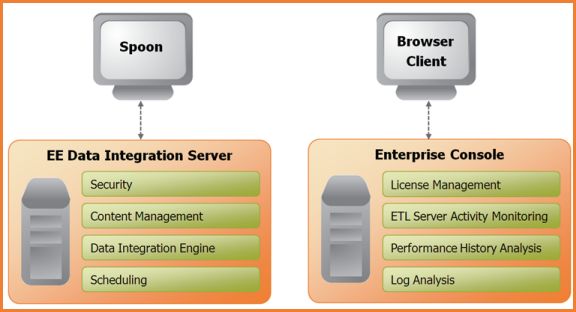
图 1‑1 PDI核心组件
Spoon是构建ETL Jobs和Transformations的工具。Spoon可以以拖拽的方式图形化设计,能够通过spoon调用专用的数据集成引擎或者集群。
Data Integration Server是一个专用的ETL Server,它的主要功能有:
| 功能 |
描述 |
| 执行 |
通过Pentaho Data Integration引擎执行ETL的作业或转换 |
| 安全性 |
管理用户、角色或集成的安全性 |
| 内容管理 |
提供一个集中的资源库,用来管理ETL的作业和转换。资源库包含所有内容和特征的历史版本。 |
| 时序安排 |
在spoon设计者环境中提供管理Data Integration Server上的活动的时序和监控的服务 |
Enterprise Console提供了一个小型的客户端,用于管理Pentaho Data Integration企业版的部署,包括企业版本的证书管理、监控和控制远程Pentaho Data Integration服务器上的活动、分析已登记的作业和转换的动态绩效。
2. PDI的组成部分
| 名称 |
描述 |
| Spoon |
通过图形接口,用于编辑作业和转换的桌面应用。 |
| Pan |
一个独立的命令行程序,用于执行由Spoon编辑的转换和作业。 |
| Kitchen |
一个独立的命令行程序,用于执行由Spoon编辑的作业。 |
| Carte |
Carte是一个轻量级的Web容器,用于建立专用、远程的ETL Server。 |
3. PDI的相关术语和基本概念

图 1‑2 PDI概念模型图
要了解Kettle的执行分为两个层次:Job和Transformation。两个层次的最主要区别在于数据传递和运行方式。
3.1. Transformation(转换)
Transformation(转换)是由一系列被称之为step(步骤)的逻辑工作的网络。转换本质上是数据流。下图是一个转换的例子,这个转换从文本文件中读取数据,过滤,然后排序,最后将数据加载到数据库。本质上,转换是一组图形化的数据转换配置的逻辑结构。
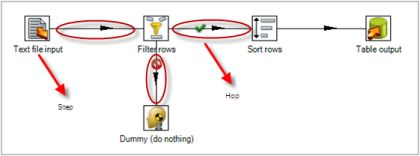
转换的两个相关的主要组成部分是step(步骤)和hops(节点连接)。
转换文件的扩展名是.ktr。
3.2. Steps(转换)
Steps(步骤)是转换的建筑模块,比如一个文本文件输入或者一个表输出就是一个步骤。在PDI中有140多个步骤,它们按不同功能进行分类,比如输入类、输出类、脚本类等。每个步骤用于完成某种特定的功能,通过配置一系列的步骤就可以完成你所需要完成的任务。
3.3. Hops(节点连接)
Hops(节点连接)是数据的通道,用于连接两个步骤,使得元数据从一个步骤传递到另一个步骤。在上图所示的转换中,它像似顺序执行发生的,但事实并非如此。节点连接决定了贯穿在步骤之间的数据流,步骤之间的顺序不是转换执行的顺序。当执行一个转换时,每个步骤都以自己的线程启动,并不断的接受和推送数据。
注意:所以的步骤是同步开启和运行的,所以步骤的初始化的顺序是不可知的。因为我们不能在第一个步骤中设置一个变量,然后在接下来的步骤中使用它。
在一个转换中,一个步骤可以有多个连接,数据流可以从一个步骤流到多个步骤。在Spoon中,hops就想是箭,它不仅允许数据从一个步骤流向另一个步骤,也决定了数据流的方向和所经步骤。如果一个步骤的数据输出到了多个步骤,那么数据既可以是复制的,也可以是分发的。
3.4. Jobs(工作)
Jobs(工作)是基于工作流模型的,协调数据源、执行过程和相关依赖性的ETL活动。
Jobs(工作)将功能性和实体过程聚合在了一起。下图是一个工作的例子。
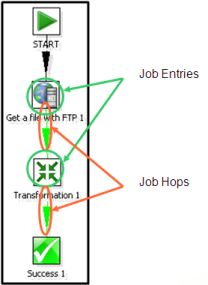
一个工作中展示的任务有从FTP获取文件、核查一个必须存在的数据库表是否存在、执行一个转换、发送邮件通知一个转换中的错误等。最终工作的结果可能是数据仓库的更新等。
工作由工作节点连接、工作实体和工作设置组成。
工作文件的扩展名是.kjb。
4. Variable(变量)
根据变量的作用域,变量被分为两类:环境变量和kettle变量。
4.1. 环境变量
环境变量可以通过edit menu下面的set environment variables对话框进行设置。使用环境变量的唯一的问题是,它不能被动态的使用。如果在同一个应用服务器中执行两个或多个使用同一环境变量的转换,将可能发生冲突。环境变量在所以使用jvm的应用中可见。
4.2. Kettle变量
Kettle变量用于在一个小的动态范围内存储少量的信息。Kettle变量是kettle本地的,作用范围可以是一个工作或转换,在工作或转换中可以设置或修改。Set variable步骤用来设置与此变量有关的工作从此设置其作用域,如:父工作、祖父工作或根工作。
5. Kitchen执行器的使用
5.1. Kitchen执行器的参数
-rep : Repository name 任务包所在存储名
-user : Repository username 执行人
-pass : Repository password 执行人密码
-job : The name of the job to launch 任务包名称
-dir : The directory (don''t forget the leading / or \)
-file : The filename (Job XML) to launch
-level : The logging level (Basic, Detailed, Debug, Rowlevel, Error, Nothing) 指定日志级别
-log : The logging file to write to 指定日志文件
-listdir : List the directories in the repository 列出指定存储中的目录结构。
-listjobs : List the jobs in the specified directory 列出指定目录下的所有任务
-listrep : List the defined repositories 列出所有的存储
-norep : Don''t log into the repository 不写日志
5.2. Kitchen命令行选项
kitchen.bat 后面可以是-也可以是/然后再加options
Options:
/rep : Repository name
/user : Repository username
/pass : Repository password
/job : The name of the job to launch
/dir : The directory (dont forget the leading /)
/file : The filename (Job XML) to launch
/level : The logging level (Basic, Detailed, Debug, Rowlevel, Error, Nothing)
/logfile : The logging file to write to
/listdir : List the directories in the repository
/listjobs : List the jobs in the specified directory
/listrep : List the available repositories
/norep : Do not log into the repository
/version : show the version, revision and build date
/param : Set a named parameter <NAME>=<VALUE>. For example -param:FOO=bar
/listparam : List information concerning the defined parameters in the specified job.
/export : Exports all linked resources of the specified job. The argument is the name of a ZIPfile.
而options 后面可以是=也可以是:也可以是空格
kitchen.bat /file d:\ 或者 -file=D:\ 或者/file:D:\等等都可以。
5.3. Windows下kitchen的执行方式的实例
kitchen.bat /norep -file=D:/kettledata/mysal2orcle.kjb >> kitchen_%date:~0,10%.log
上面的含义是,使用kitchen.bat 命令来执行job文件,job文件的存放路径是D:/kettledata/mysal2orcle.kjb,并且将执行的结果输出到 kitchen_%date:~0,10%.log文件中。
6. Pentahon XUL Framework简介
XUL Framework是一个试图为不同UI技术提供统一样式的项目。它的目标是使得多种UI技术(如:Swing、SWT、GWT)能够提交出一个统一的用户接口而不必每次重写描述层。XUL的常见案例有:普通对话框、可定制的菜单和工具栏、新的工具应用。
6.1. XUL文件
XUL是英文“XML User Interface Language”的首字母缩写。它是为了支持Mozilla系列的应用程序(如Mozilla Firefox和Mozilla Thunderbird)而开发的使用者界面标示语言。顾名思义,它是一种应用XML来描述使用者界面的标示语言。
6.2. Pentaho XUL的执行步骤
(1) 加载XUL文件
![]()
(2) 添加Event Handlers
![]()
(3) 为SWT提供菜单栏
![]()
(4) 为菜单栏添加菜单项
![]()
PS:这次仅仅介绍了Kettle的基本概念和术语,这部分是由我同学来完成的。Kettle应该还算比较小众的开源软件资料不多,希望这次的分析能够对大家有一定的帮助。大部分的分析都是自己理解的,所以有所偏差或错误请大家指正。接下来准备分析,Kettle的插件体系结构、转换机制、job运行机制。