Hadoop: the definitive guide 第三版 拾遗 第十章 之Pig
概述:
Pig的安装很简单,注意一下几点:
1、设置系统环境变量:
export PIG_HOME=.../pig-x.y.z export PATH=$PATH:$PIG_HOME/bin
设置完成后使用pig -help进行验证一下。
2、两种mode:
local mode:访问本地文件系统,进入shell时使用命令:pig -x local
MapReduce mode:pig将查询翻译为MapReduce作业,然后在hadoop集群上执行。此时,进入shell时的命令为:pig -x mapreduce 或者pig
hadoop@master:/usr/local/hadoop/conf$ pig -x mapreduce Warning: $HADOOP_HOME is deprecated. 2013-08-16 16:18:52,388 [main] INFO org.apache.pig.Main - Apache Pig version 0.11.1 (r1459641) compiled Mar 22 2013, 02:13:53 2013-08-16 16:18:52,389 [main] INFO org.apache.pig.Main - Logging error messages to: /usr/local/hadoop/conf/pig_1376641132384.log 2013-08-16 16:18:52,470 [main] INFO org.apache.pig.impl.util.Utils - Default bootup file /home/hadoop/.pigbootup not found 2013-08-16 16:18:52,760 [main] INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine - Connecting to hadoop file system at: hdfs://master:9000 2013-08-16 16:18:53,174 [main] INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine - Connecting to map-reduce job tracker at: master:9001
注意:使用MapReduce模式需要设置hadoop的配置文件hadoop-env.sh,加入:
export PIG_CLASSPATH=$HADOOP_HOME/conf
示例一:
.../in/ncdc/micro-tab/sample.txt文件的内容为:
1950 0 1 1950 22 1 1950 -11 1 1949 111 1 1949 78 1
在pig的shell下执行下列命令:
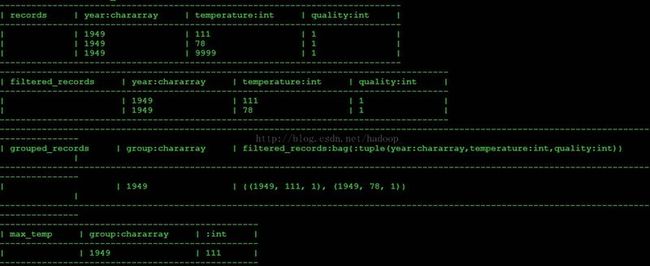
grunt> -- max_temp.pig: Finds the maximum temperature by year grunt> records = LOAD 'hdfs://master:9000/in/ncdc/micro-tab/sample.txt'--在不确定自己设置的默认路径是什么的情况下使用hdfs完整路径 >> AS (year:chararray, temperature:int, quality:int); grunt> filtered_records = FILTER records BY temperature != 9999 AND >> (quality == 0 OR quality == 1 OR quality == 4 OR quality == 5 OR quality == 9); grunt> grouped_records = GROUP filtered_records BY year; grunt> max_temp = FOREACH grouped_records GENERATE group, >> MAX(filtered_records.temperature); grunt> DUMP max_temp;
pig同时提供ILLUSTRATE操作,以生成简洁明了的数据集。
grunt>ILLUSTRATE max_temp;
输出为:
示例二:
指南中关于注释的示例,在此处,略作修改,加入schema:
grunt> B = LOAD 'input/pig/join/B' AS (chararry,int);
grunt> A = LOAD 'input/pig/join/A' AS (int,chararry);
grunt> C = JOIN A BY $0, /* ignored */ B BY $1;
grunt> DESCRIBE C
C: {A::val_0: int,A::chararry: bytearray,B::chararry: bytearray,B::val_0: int}
grunt> ILLUSTRATE C
输出为:
---------------------------------------------------- | A | val_0:int | chararry:bytearray | ---------------------------------------------------- | | 3 | Hat | | | 3 | Hat | ---------------------------------------------------- ---------------------------------------------------- | B | chararry:bytearray | val_0:int | ---------------------------------------------------- | | Eve | 3 | | | Eve | 3 | ---------------------------------------------------- ----------------------------------------------------------------------------------------------------------- | C | A::val_0:int | A::chararry:bytearray | B::chararry:bytearray | B::val_0:int | ----------------------------------------------------------------------------------------------------------- | | 3 | Hat | Eve | 3 | | | 3 | Hat | Eve | 3 | | | 3 | Hat | Eve | 3 | | | 3 | Hat | Eve | 3 | -----------------------------------------------------------------------------------------------------------
注意:Pig Latin的大小写敏感性采用混合的规则,其中:
操作和命令是大小写无关;
别名和函数大小写敏感。
例如上例中:
grunt> describe c
2013-08-16 17:14:49,397 [main] ERROR org.apache.pig.tools.grunt.Grunt - ERROR 1005: No plan for c to describe
Details at logfile: /usr/local/hadoop/conf/pig_1376641755235.log
grunt> describe C
C: {A::val_0: int,A::chararry: bytearray,B::chararry: bytearray,B::val_0: int}
grunt> DESCRIBE C
C: {A::val_0: int,A::chararry: bytearray,B::chararry: bytearray,B::val_0: int}