sql学习笔记
1.Select用法... 2
1.1.从表中查数据 select * from table. 2
1.2不需要 FROM 子句的 SELECT 语句... 2
1.3. 给变量赋值... 2
1.4.下面两句的查询结果第一个无列名,第二个有。... 2
1.5.LIKE关键字... 2
2. Oder by使用注意... 3
2.1. 如果SELECT中用到DISTINCT关键字,还要使用ORDER BY 子句,那么,排序的列必须是包含在SELECT列表中的字段。... 3
3. 同义词(Synonym)... 3
4. Sql Server中的数据类型... 3
5. 关于Insert的使用... 3
6.数据库对象... 3
6.1.约束... 3
6.2.默认... 4
6.3.规则... 4
7.用户自定义类型... 4
8.Group By使用注意... 5
9.子查询... 5
10.UNION运算符... 5
11.Join. 5
12.索引... 5
12.1.建立索引的原则... 6
12.2.索引的分类... 6
12.3.使用T-Sql建立索引... 6
12.4.索引的分析与维护... 7
13.视图 View. 8
14.存储过程与触发器... 8
14.1.存储过程类型:... 8
14.2.触发器... 8
14.3.SqlClR存储过程触发器等... 9
15.Sql Server的安全相关... 10
15.1.sql server 2005有两种账号... 10
15.2.服务器角色... 10
15.3.数据库角色... 10
16.用户自定义函数... 10
16.1.标量用户自定义函数... 10
16.2.直接表值用户定义函数... 11
16.3.创建多语句表值用户自定义函数... 11
17.事务... 11
18.游标... 12
18.1.游标的定义... 12
18.2.游标的使用... 12
一些小知识点... 13
1.1.rowcount表示查询表的前指定行... 13
1.2.Compute. 13
1.3.HAVING子句... 13
1.4. 关于#和##创建用户本地临时对象和用户全局全局临时对象。... 13
1.5.对象引用问题... 13
1.Select用法
1.1.从表中查数据 select * from table
1.2不需要 FROM 子句的 SELECT 语句
是那些不从数据库内的任何表中选择数据的 SELECT 语句。这些 SELECT 语句只从局部变量或不对列进行操作的 Transact-SQL 函数中选择数据,例如:
SELECT GETDATE( )
这些Selcet语句查找到的是局部变量或者函数的值。
给变量赋值
SELECT col1=100, col2=200
declare @MyIntVariable nvarchar(20)
SELECT @MyIntVariable='ss'
SELECT @MyIntVariable
1.4.下面两句的查询结果第一个无列名,第二个有。
SELECT 4+3, 4-3, 4*3, 4/3
SELECT Additions=4+3, Subtractions=4-3, Multiplications=4*3, Divisions=4/3
修改查询结果中列标题(别名)
方法1:将要显示的列标题用单引号括起来后接等号(=),后接要查询的列名。
方法2:将要显示的列标题用单引号括起来,写在列名后面,两者之间空格隔开。
方法3:将要显示的列标题用单引号括起来,写在列名后面,两者之间使用AS关键字。
{kind=link}
1.5.LIKE关键字
%,百分号,匹配包含0个或多个字符的字符串
_,下划线,匹配任何单个的字符
[],排列通配符,匹配任何在范围或集合之内的单个字符,例如[m-p]匹配的是m,n,o,p单个字符。
[^],不在范围之内的字符,匹配任何不在范围或集合之内的单个字符,例如[^mnop]或[^m-p]匹配的是除了m,n,o,p之外的任何字符。
要查找通配符本身时,需要将他们用方括号括起来,如LIKE ‘[[]’表示匹配“[”.
2. Oder by使用注意
2.1. 如果SELECT中用到DISTINCT关键字,还要使用ORDER BY 子句,那么,排序的列必须是包含在SELECT列表中的字段。
select distinct AttTime from AttRecords order by AttTime 正确
select distinct Emp from AttRecords order by AttTime 错误
3. 同义词(Synonym)
3.1.在一些商业数据库中,有时信息系统的设计或开发者为了增加易读性,故意定义一些很长的表名(也可能是其它的对象)。这样虽然增加了易读性,但在引用这些表 或对象时就不那么方便,也容易产生输入错误。另外在实际的商业公司里,一些用户觉得某一个对象名有意义也很好记,但另一些用户可能觉得另一个名字更有意义,通俗的说就是某些表的别名,例如下面创建一个AttRecords的同义词AR:
create synonym AR for AttRecords
之后我们就是使用AR来对表AttRecords进行任何操作了
select * from AR
4. Sql Server中的数据类型
大体上可以分为四类:数字,字符,日期时间,其他
4.1.数字—分为Integers整数和Decimals小数
4.2.字符型:包括CHAR,VARCHAR,TEXT,NCHAR,NVARCHAR
4.3.日期时间:包括DATETIME,SMALLDATETIME
4.4.其他:BINARY,BIT,IMAGE,SQL_VARIANT,UNIQUEIDENTIFIER(GUID),XML
在Sql Server2005中用varchar(max)代替text。用nvarchar(max)代替ntext,用binary(max)代替image.为XML数据选择xml类型。
5. 关于Insert的使用
5.1.Insert into .. values
insert into AttRecords values('
5.2.Insert into .. select
insert into AttRecords(AttTime) select CardTime from Attendance
6.数据库对象
6.1.约束
数据的完整性包括实体完整性,域完整性,参照完整性,用户定义完整性4种
实体完整性:也称行完整性,说表的所有记录在某一列上的取值必须唯一。
域完整性:也称列完整性,说指定列的数据输入是否具有正确的数据类型,格式以及有效的数据范围。
参照完整性:保证参照与被参照表中的数据一致。
用户定义完整性:允许用户定义不属于其他任何完整性分类的特定规则。
约束包括check约束,primary key约束,foreign key约束,unique约束和default约束。
l check约束:用于限制输入一列或多列的值的范围,通过逻辑表达式来判断数据的有效性,也就是一个列的输入内容必须满足check约束的条件,否则,数据无法正常输入,从而强制数据的域完整性。
例如,我们创建如何check约束,AttRecords表的Dept只能为值A,B,C:
alter table AttRecords
add constraint CK_Dept check(Dept='A' or Dept='B' or Dept='C' )
删除约束:
alter table AttRecords
drop constraint CK_Dept
l primary key约束:主键约束,只能用在唯一列不为空做主键。创建语句格式同上。
l foreign key约束:外键约束。创建语句格式同上。
l unique约束:用于确保表中的两个数据行在非主键中没有相同的列值,与主键约束类似,unique约束也强制唯一性,为表中的一列或多列提供实体完整性,单Unique约束用于非主键的一列或多列组合,且一个表可以定义多个Unique约束,另外Unique约束可以用户定义多列组合。
l default约束:若在表中某列定义了default约束,用户在插入新的数据行时,如果该列没有指定数据,那么系统将默认值赋给该列,默认值也可以是空值NULL。
给Dept加default约束,Dept默认为A:
alter table AttRecords
add constraint DF_Dept default 'A' for Dept
删除该约束如下:
alter table AttRecords
drop constraint DF_Dept
6.2.默认
默认与default约束不一样,他是一种数据库对象,在数据库中只需要定义一次,多出引用。例:创建Dept的默认值为A,并绑定到表AttRecords的Dept列,这样每次插入数据该列就会有默认值,默认数据库对象在数据的可编程性—默认下:
create default MR_Dept
as 'A'
exec sp_bindefault MR_Dept,'AttRecords.Dept'
6.3.规则
通默认一样是一种数据库对象,我们创建一个规则Dept只能为A,B,C并绑定到AttRecords的Dept列,下面的@dept是个变量,绑定时会自动和绑定的列关联。
create rule GZ_Dept
as @dept='A' or @dept='B' or @dept='C'
exec sp_bindrule GZ_Dept,'AttRecords.Dept'
7.用户自定义类型
必须提供名称,新数据类型所依据的系统数据类型,数据类型是否允许为空值,例:
创建一个meetingday表示会议时间的自定义类型,基于smalldatetime
在sql server中使用系统存储过程sp_addtype来创建用户定义类型,如下:
exec sp_addtype meetingday ,smalldatetime,'not null'
删除需要使用系统存储过程 sp_droptype
8.Group By使用注意
8.1.select子句中的选项列表出现的列,必须包含在聚合函数中或者包含在Group by子句中,否则会出错。
9.子查询
9.1.子查询的select语句中不能使用order by子句,order by子句只能对最终查询结果排序。
10.UNION运算符
10.1.用于将两个或多个查询结果合并成一个结果,当使用该运算符需要遵循下面两个规则:
(1):所有查询中列数和列的顺序必须相同。
(2):所有查询中按顺序对应列的数据类型必须兼容。
例如:插入数据:
INSERT INTO AttRecords
SELECT '2008-08-02 6:45','zhangsan','A' UNION ALL
SELECT '2008-08-08 19:12','zhangsan','A' UNION ALL
SELECT '2008-08-01 6:41','ww','A' UNION ALL
SELECT '2008-08-01 8:41','ww','A'
11.Join
Sql Server中可以使用两种连接语法形式,一种是ANSI连接语句形式,此时连接用在From子句。另外一种是使用Sql Server连接语法格式,此时连接用在where子句中。下面会使用两种形式表示。
Sql Server形式:
select * from AR ,Employees e
where AR.Emp=e.WorkNo
ANSI形式:
select * from AR inner join Employees e
on AR.Emp=e.WorkNo
l left join(左连接)包含所有的左边表中的记录甚至是右边表中没有和它匹配的记录。
l right join(右连接),即包含所有的右边表中的记录甚至是左边表中没有和它匹配的记录。
l full join(全连接)顾名思义,左右表中所有记录都会选出来。
12.索引
以表为基础的数据库对象,它保存着表中排序的所以列,并且记录了索引列在数据表中的物理存储位置,实现了表中数据的逻辑排序,主要目的是提高Sql Server的系统性能,加快查询速度和减少系统的响应时间。索引就象书的目录一样记录着表中关键值指向表中的记录。
索引也有一定的代价,创建索引和维护索引都会消耗时间,当对表中的数据进行增加,删除和修改操作时,索引就要进行维护,否则索引的作用就会下降,另外,每个索引都会占用一定的物理空间,如果占用的物理空间过多会影响整个Sql Server的性能。
12.1.建立索引的原则
(1):定义有主键的数据列一定要建立索引,因为主键可以加速定位到表中的某一行。
(2):定义有外键的数据列一定要建立索引,外键列通常用于表与表之间的连接,在其上创建索引可以加快表间的连接。
(3):对于经常查询的数据列最好建立索引
(4):对于定义为text,image,bit数据类型的列不要建立索引,因为这些数据类型的数据列的数据量要不很大,要么很小,不利于使用索引。
12.2.索引的分类
(1):聚集索引:聚集索引会对表和视图进行物理排序,所以这种索引对查询非常有效,在表和视图中只能有一个聚集索引。当建立主键约束时,如果表中没有聚集索引,sql server会用主键列作为聚集索引键。可以在表的任何列或者列的组合上建立索引,实际应用中一般为定义成主键约束的列建立聚集索引。
(2):非聚集索引:非聚集索引不会对表和视图进行物理排序,如果表中不存在聚集索引,则表是未排序的,在表或视图中最多可以建立250个非聚集索引,或者249个非聚集索引和一个聚集索引。
(3):唯一索引:唯一索引不允许两行具有相同的所以值,例如在表中“姓名”字段上建立了唯一索引,则以后输入的姓名将不能同名。
聚集索引和非聚集索引都可以是唯一的,因为,只要列中数据是唯一的,就可以在同一个表上创建一个唯一的聚集索引。如果必须实施唯一性以确保数据的完整性,则应在列上创建Unique或primary key约束,而不要创建唯一索引。
创建primary key或Unique约束会在表中指定的列上自动创建唯一索引,创建Unique约束与手动创建唯一索引没有明显的区别。
12.3.使用T-Sql建立索引
(1):创建聚集,唯一,简单索引:
create unique clustered
index IX_AR on AttRecords(AttTime)
创建和使用唯一索引注意如下:
l Unique索引即可以采用聚集索引的结构,也可以采用非聚集索引的结构,如果不指明clustered选项,那么sql server索引默认采用非聚集索引的结构。
l 建立Unique索引的表在执行insert或update时,sql server将自动检验新的数据中是否存在重复值。如果存在会报错。
l 具有相同组合列,不同组合顺序的复合索引彼此是不同的。
l 如果表中已有数据,那么在创建Unique索引时,sql server会自动检验是否存在重复值,若存在,则不能创建。
(2):删除索引:drop index AttRecords.IX_AR
删除索引时注意:
l 不能用drop index语句删除由primary key约束或Unique约束创建的索引。要删除这些索引必要先删除primary key约束或Unique约束。
l 在删除聚集索引时,表中的所有非聚集索引都将被重建。
(3):查看表上索引信息:
exec sp_helpindex AttRecords
重命名索引:exec sp_rename 'AttRecords.IX_AR' ,'IX_NAR'
12.4.索引的分析与维护
可以使用showplan_all显示执行查询过程中连接表时所采取的每个步骤,以及是否选择及选择了那个索引。
可以使用statistics io显示磁盘io信息
set showplan_all on
go
select * from AR
go
set showplan_all off
set statistics IO on
go
select * from AR
go
set statistics io off
go
在创建索引后,为了得到最佳的性能,必须对索引进行维护,因为随着时间的推移用户需要在数据库上进行插入,更新和删除等一系列操作,这将使数据变得杂乱无序,从而造成索引性能下降。
Sql server提供了多种工具帮助用户进行索引的维护,下面介绍常用的方式:
(1):统计信息更新
在创建索引时,sql server会自动存储有关的统计信息,查询优化器会利用索引统计信息估算使用该索引进行查询的成本,然而,随着数据的不断变化,索引和列的统计信息可能已经超时,从而导致查询优化器选择的查询处理方法不是最佳的,因此有次要对数据库中的这些统计信息进行更新。
用户应该避免频繁地进行索引统计的更新,特别应避免在数据库操作比较集中的时间段内进行更新统计。
我们可以使用Update statistics来更新数据库中索引的统计信息,如下:
update statistics AttRecords IX_NAR
对表进行数据操作可能会导致表碎片的产生,而表碎片会导致读取额外页,从而造成数据查询性能的降低,此时,用户可以通过使用dbcc showcontig语句来扫描表,通过其返回值确定该索引页是否已经严重不连续,如下:
dbcc showcontig (AttRecords, IX_NAR)
DBCC SHOWCONTIG scanning 'AttRecords' table...
Table: 'AttRecords' (1058102810); index ID: 1, database ID: 16
TABLE level scan performed.
- Pages Scanned................................: 1
- Extents Scanned..............................: 1
- Extent Switches..............................: 0
- Avg. Pages per Extent........................: 1.0
- Scan Density [Best Count:Actual Count].......: 100.00% [1:1]
- Logical Scan Fragmentation ..................: 0.00%
- Extent Scan Fragmentation ...................: 0.00%
- Avg. Bytes Free per Page.....................: 8006.0
- Avg. Page Density (full).....................: 1.09%
DBCC execution completed. If DBCC printed error messages, contact your system administrator.
当表或视图上的聚集索引和非聚集索引页级上存在碎片时,可以通过下面指令进行整理:
dbcc indexdefrag(EIP,AttRecords, IX_NAR)
Pages Scanned Pages Moved Pages Removed
-------------------- -------------------- --------------------
1 0 0
13.视图 View
13.1.不能更新数据的视图
(1):有union等集合操作符的视图
(2):有group by子句的视图
(3):有诸如AVG,sum等函数的视图
(4):使用distinct关键字的视图
(5):部分连接表的视图
13.2.创建视图的一些规则
(1):不能将规则或者default定义关联于视图
(2):定义视图的查询中不能含有order by,computer,computer by子句和into关键字。
(3):如果视图中的某一列是一个算术表达式,构造函数或者常数,而且视图中两个或者更多的不同列拥有一个相同的名字,此时用户需要为视图的每一列指定列的名称。
14.存储过程与触发器
14.1.存储过程类型:
(1):系统存储过程
(2):本地存储过程:就是用户创建的,也是我们一般所说的存储过程。
(3):临时存储过程:如果我们在创建存储过程时,以#号作为其名称的第一个字符,则该存储过程将成为一个存放在tempdb数据库中的本地临时存储过程,临时存储过程在断开域sql server的连接后会自动删除。如果以两个##开头就是全局临时存储过程。
(4):远程存储过程:位于远程服务器上的存储过程,通常可以使用分布式和execute命令执行一个远程存储过程。
(5):扩展存储过程:是用户可以使用外部程序语言编写的存储过程,扩展存储过程通常以xp_开头,扩展存储过程是以动态链接库的形式存在,能让sql server 2005动态地装载和执行,扩展存储过程一定要存储在系统数据库master中。
14.2.触发器
触发器也是一种存储过程,它是一种在基本表被修改时自动执行的内嵌过程,主要通过事件进行触发而执行,当对某一张表进行诸如update,insert,delete这些操作时,sql server会自动执行触发器定义的sql语句。触发器的主要作用是其能实现由主键和外键不能保证的复杂的参照完整性和数据一致性。
触发器可以实现一下操作:
(1):强制比check约束更复杂的数据的完整性
(2):使用自定义的错误提示信息
(3):实现数据库中多表的级联修改
(4):比较数据库修改前后数据的状态
(5):维护规范化数据
例如:当删除一个类别后,与该类别有关的商品都标记为不可用
CREATE TRIGGER Category_Delete
ON Categories
FOR DELETE
AS
UPDATE P SET Discontinued = 1
FROM Products AS P INNER JOIN deleted AS d
ON P.CategoryID = d.CategoryID
14.3.SqlClR存储过程触发器等
首先要在Vs2008中创建数据库项目,在该数据库项目中你可以增加存储过程,触发器,用户自定义函数等,这些都是使用。Net代码来完成,我们以存储过程为例,代码如下:
using System;
using System.Data;
using System.Data.SqlClient;
using System.Data.SqlTypes;
using Microsoft.SqlServer.Server;
public partial class StoredProcedures
{
[Microsoft.SqlServer.Server.SqlProcedure]
public static void CaryStoredProcedure(string name,ref string outstr)
{
// Put your code here
using (SqlConnection cn = new SqlConnection())
{
//使用上下文链接也就是当前数据库链接
cn.ConnectionString = "context connection=true";
using (SqlCommand cmd = cn.CreateCommand())
{
cmd.CommandText = "Select * from AttRecords";
cn.Open();
//SqlContext.Pipe.Send这个方法输出结果集
//接受SqlDataReader,SqlDataRecord和string
SqlContext.Pipe.Send(cmd.ExecuteReader());
//你也可以用下边这样
//SqlContext.Pipe.ExecuteAndSend(cmd);
}
}
}
}
部署前需要在你的sql server中开放信任,如下:
alter database eip set trustworthy on
设置clr enabled
EXEC sp_configure 'clr enabled' , 1
RECONFIGURE
然后在数据库项目上右键部署,部署成功后在Sql Server的的数据库中的可编程性---程序集下有我们Vs2008的程序集,存储过程下有我们的sql clr存储过程。下面我们执行:
DECLARE @name nvarchar(4000)
DECLARE @outstr nvarchar(4000)
set @name='david fan'
-- TODO: 在此处设置参数值。
EXECUTE CaryStoredProcedure
@name
,@outstr OUTPUT
print @outstr
触发器,用户自定义函数方式与上面基本相同。
14.4.存储过程的调试
这里指的是T-Sql中的存储过程,我们需要在VS2008中打开服务器管理器,连接到相关的数据库找到存储过程,右键有单步调试进行:
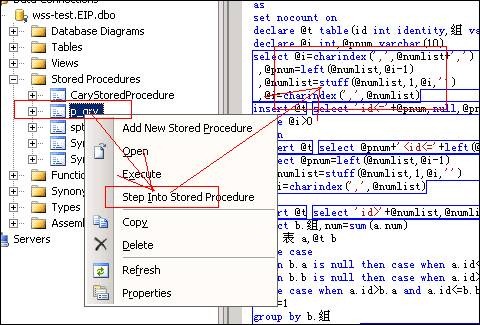{kind=link}
15.Sql Server的安全相关
15.1.sql server 2005有两种账号
一种是登录服务器的登录账号,另一种是使用数据库的用户账号。登录账号是子能登录到sql server服务器的账号,属于服务器层面,它本身不能让用户访问服务器中的数据库。要访问服务器中的数据必要使用用户账号才能够存取数据库,用户账号要在特定的数据库内创建,并关联一个登录名。
15.2.服务器角色
负责管理与维护sql server 2005的组,已定义的如下:
Sysadmin:可以执行任何活动
Serveradmin:可以设置服务器范围的配置选项,可以关闭服务器
Setupadmin:可以管理连接服务器和启动过程
Securityadmin:可以管理登录和创建数据库的权限,还可以读取错误日志和更改密码
Processadmin:可以管理在sql server中运行的进程
Dbcreator:可以创建,更改和删除数据库。
Diskadmin:可以管理磁盘文件
Bulkadmin:可以执行bulk insert语句。
15.3.数据库角色
分为标准角色和应用程序角色,标准角色有如下:
db_owner: 该角色表现得就好像它是所有其他数据库角色中的成员一样。使用这一角色能够造就这样的情形:多个用户可以完成相同的功能和任务,就好像他们是数据库的所有者一样
db_accessadmin: 实现类似于securityadmin服务器角色所实现功能的一部分,只不过这一角色仅局限于指派它并创建用户的单个数据库中(不是单个的权限)。它不能创建新的SQL Server登录账户,但是,该角色中的成员能够把Windows用户和组以及现有的SQL Server登录账户加入到数据库中
db_datareader: 能够在数据库中所有的用户表上执行SELECT语句
db_datawriter: 能够在数据库中所有的用户表上执行INSERT、UPDATE和DELETE语句
db_ddladmin: 能够在数据库中添加、修改或删除对象
db_securityadmin: securityadmin服务器角色的数据库级别的等价物。这一数据库角色不能在数据库中创建新的用户,但是,能够管理角色和数据库角色的成员,并能在数据库中管理语句和对象的许可权限
db_backupoperator: 备份数据库(打赌你不会想到那样一个角色!)
db_denydatareader: 提供一种等同于在数据库中所有表和视图上DENY SELECT的效果
db_denydatawriter: 类似于db_denydatareader,只不过这里影响的是INSERT、UPDATE和DELETE语句
16.用户自定义函数
Sql server 2005支持的用户自定义函数分为3中,标量用户自定义函数,直接表值用户定义函数,多语句表值用户自定义函数。
16.1.标量用户自定义函数
标量用户自定义函数返回一个简单的数值,如int,char,decimal等,但禁止使用text,ntext,image,cursor和timestamp作为返回的参数。例如:
返回指定部门中AttTime的最大值,并返回。
create function GetMaxAttTimeByDept(@dept nvarchar(3))
returns datetime
as begin
declare @maxAtttime datetime
set @maxAtttime=
(
select max(Atttime) from AR where Dept=@dept
)
return @maxAtttime
end
--执行
select dbo.GetMaxAttTimeByDept('A') as 'MaxAttTime'
16.2.直接表值用户定义函数
表值函数返回一个Table型数据,对直接表值用户定义函数而言,返回的结果只是一系列表值,没有明确的函数体。该表是select语句的结果集。例如:
create function AttRecordInfo(@dept nvarchar(3))
returns table
as
return(select * from AR where Dept=@dept)
--执行
select * from dbo.AttRecordInfo('A')
16.3.创建多语句表值用户自定义函数
多语句表值用户自定义函数是以begin语句开始,end语句结束的函数体,这些语句可将行插入返回的表中。
create function GetMaxAttTimeByDept1(@dept nvarchar(3))
returns @GetMaxAttTimeByDept table(AT datetime,emp nvarchar(20),dept nvarchar(20))
as begin
insert @GetMaxAttTimeByDept
select * from AR where Dept=@dept
return
end
--执行
select * from dbo.GetMaxAttTimeByDept1('A')
17.事务
17.1.例:当dept为A的记录多余4条即插入不成功,回滚。
begin transaction
insert AttRecords values('
insert AttRecords values('
insert AttRecords values('
insert AttRecords values('
declare @countnum int
set @countnum=(select count(*) from AttRecords where dept='A')
if @countnum>4
begin
rollback tran
print 'Dept为A的条目不能超过四条!'
end
else
begin
commit tran
print '操作成功!'
end
17.2.回滚到指定位置
--事务操纵语句,回滚到指定位置
begin tran
insert into [order details] values(10248,14,42.4,500,0.0)
save transaction savepoint
update [order details] set quantity=500 where orderid=10248
rollback transaction savepoint
18.游标
游标是一种数据访问机制,它允许用户访问单独的数据行,而并非对整个行集合进行操作。用户可以通过单独处理每一行逐条收集信息并对数据逐行进行操作,这样,可以降低系统的开销和潜在的阻隔。用户也可以使用这些数据生成的T-SQL代码并立即执行或输出,从另一个角度看,游标是用户使用T-SQL代码可能获得数据集中最紧密的数据的一种方法。
18.1.游标的定义
游标是一个与T-SQL的select语句相关联的符号名,它使用户可逐行访问由sql server返回的结果集。游标包括以下两个部分:
(1):游标结果集:由定义该游标的select语句返回的行结合。
(2):游标位置:指向这个行集合某一行的当前指针。
18.2.游标的使用
--定义游标
declare cu_getalldata cursor
for select * from AR
--打开游标
open cu_getalldata
--检索下一行记录,每次执行都会返回当前记录的下一行
fetch next from cu_getalldata
--更新当前游标所在行
update AR set emp='testcursor' where current of cu_getalldata
--关闭游标
close cu_getalldata
--释放游标
deallocate cu_getalldata
一些小知识点
1.1.rowcount表示查询表的前指定行
set rowcount 1
select * from AttRecords
1.2.Compute
Compute子句用来计算总计或进行分组小计,总计值或小计值将作为附件的新行出现,该子句用在where子句之后。
select * from AR where Dept='A'
compute min(AttTime)
compute by子句对by后面给出的列进行分组显示,并计算该列的分组小计,使用compute by子句必须按照order by和compute by中by指定的列进行排序。
select * from AR
order by Dept
compute min(AttTime) by Dept
1.3.HAVING子句
用于限定组或聚合函数的查询条件,该子句常常用在group by子句之后,在结果集分组之后再进行判断,如果没有group by时having与where是同等作用,只不过having可以包含聚合函数。Having和where的区别就是前者是先分组,在对分组后的数据进行筛选,后者是先对所有数据进行筛选在分组。如下:
select dept,AttTime from AR
group by dept,AttTime
having Dept='A'
select dept,AttTime from AR
where Dept='A'
group by dept,AttTime
1.4. 关于#和##创建用户本地临时对象和用户全局全局临时对象。
这些都临时存储在tempdb中,该数据库在sql server的每次启动时都会清空原来的数据并重建。
变量:局部变量@name,全局变量@@name
1.5.对象引用问题
当引用某个特定对象时,不必中为sql server指定表示该对系那个的服务器,数据库,所有者,可以省略中间级节点,而使用句点表示这些位置,下面都是有效的格式:
Server.database.owner.object
Server.database..object
Server..owner.object
Database..object
http://www.cnblogs.com/carysun/archive/2010/06/09/1755073.html
作者:生鱼片 出处:http://carysun.cnblogs.com/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。