【E2LSH源代码分析】p稳定分布LSH算法初探
上一节,我们分析了LSH算法的通用框架,主要是建立索引结构和查询近似近期邻。这一小节,我们从p稳定分布LSH(p-Stable LSH)入手,逐渐深入学习LSH的精髓,进而灵活应用到解决大规模数据的检索问题上。
相应海明距离的LSH称为位採样算法(bit sampling),该算法是比較得到的哈希值的海明距离,可是一般距离都是用欧式距离进行度量的,将欧式距离映射到海明空间再比較其的海明距离比較麻烦。于是,研究者提出了基于p-稳定分布的位置敏感哈希算法,能够直接处理欧式距离,并解决(R,c)-近邻问题。
1、p-Stable分布
定义:对于一个实数集R上的分布D,假设存在P>=0,对不论什么n个实数v1,…,vn和n个满足D分布的变量X1,…,Xn,随机变量ΣiviXi和(Σi|vi|p)1/pX有同样的分布,当中X是服从D分布的一个随机变量,则称D为 一个p稳定分布。
对不论什么p∈(0,2]存在稳定分布:
p=1是柯西分布,概率密度函数为c(x)=1/[π(1+x2)];
p=2时是高斯分布,概率密度函数为g(x)=1/(2π)1/2*e-x^2/2。
利用p-stable分布能够有效的近似高维特征向量,并在保证度量距离的同一时候,对高维特征向量进行降维,其关键思想是,产生一个d维的随机向量a,随机向量a中的每一维随机的、独立的从p-stable分布中产生。对于一个d维的特征向量v,如定义,随机变量a·v具有和(Σi|vi|p)1/pX一样的分布,因此能够用a·v表示向量v来估算||v||p 。
2、p-Stable分布LSH中的哈希函数
p-Stable分布的LSH利用p-Stable的思想,使用它对每个特征向量v赋予一个哈希值。该哈希函数是局部敏感的,因此假设v1和v2距离非常近,它们的哈希值将同样,并被哈希到同一个桶中的概率会非常大。
依据p-Stable分布,两个向量v1和v2的映射距离a·v1-a·v2和||v1-v2||pX 的分布是一样的。
a·v将特征向量v映射到实数集R,假设将实轴以宽度w等分,并对每一段进行标号,则a·v落到那个区间,就将此区间标号作为哈希值赋给它,这样的方法构造的哈希函数对于两个向量之间的距离具有局部保护作用。
哈希函数格式定义例如以下:
ha,b(v):Rd->N,映射一个d维特征向量v到一个整数集。哈希函数中又两个随机变量a和b,当中a为一个d维向量,每一维是一个独立选自满足p-Stable的随机变量,b为[0,w]范围内的随机数,对于一个固定的a,b,则哈希函数ha,b(v)为
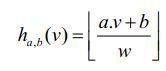

图1 p-Stable LSH在二维空间的演示样例
3、特征向量碰撞概率
随机选取一个哈希函数ha,b(v),则特征向量v1和v2落在同一桶中的概率该怎样计算呢?
首先定义c=||v1-v2||p,fp(t)为p-Stable分布的概率密度函数的绝对值,那么特征向量v1和v2映射到一个随机向量a上的距离是|a·v1-a·v2|<w,即|(v1-v2)·a|<w,依据p-Stable分布的特性,||v1-v2||pX=|cX|<w,当中随机变量X满足p-Stable分布。
可得其碰撞概率p(c):
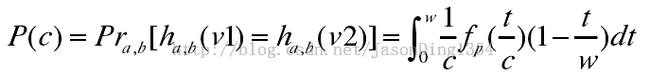
依据该式,能够得出两个特征向量的冲突碰撞概率随着距离c的添加而减小。
4、p-Stable分布LSH的相似性搜索算法
经过哈希函数哈希之后,g(v)=(h1(v),...,hk(v)),但将(h1(v),...,hk(v))直接存入哈希表,即占用内存,又不便于查找,为解决此问题,现定义另外两个哈希函数:

因为每个哈希桶(Hash Buckets)gi被映射成Zk,函数h1是普通哈希策略的哈希函数,函数h2用来确定链表中的哈希桶。
(1)要在一个链表中存储一个哈希桶gi(v)=(x1,...,xk)时,实际上存的不过h2(x1,...,xk)构造的指纹,而不是存储向量(x1,...,xk),因此一个哈希桶gi(v)=(x1,...,xk)在链表中的相关信息仅有标识(identifier)指纹h2(x1,...,xk)和桶中的原始数据点。
(2)利用哈希函数h2,而不是存储gi(v)=(x1,...,xk)的值有两个原因:首先,用h2(x1,...,xk)构造的指纹能够大大降低哈希桶的存储空间;其次,利用指纹值能够更快的检索哈希表中哈希桶。通过选取一个足够大的值以非常大的概率来保证随意在一个链表的两个不同的哈希桶有不同的h2指纹值。

图2 桶哈希策略示意图
5、不足与缺陷
LSH方法存在双方面的不足:首先是典型的基于概率模型生成索引编码的结果并不稳定。尽管编码位数添加,可是查询准确率的提高确十分缓慢;其次是须要大量的存储空间,不适合于大规模数据的索引。E2LSH方法的目标是保证查询结果的准确率和查全率,并不关注索引结构须要的存储空间的大小。E2LSH使用多个索引空间以及多次哈希表查询,生成的索引文件的大小是原始数据大小的数十倍甚至数百倍。
转载请注明作者及文章出处:http://blog.csdn.net/jasonding1354/article/details/38237353
參考资料:
1、王旭乐.基于内容的图像检索系统中高维索引技术的研究[D].华中科技大学.2008
2、M.Datar,N.Immorlica,P.Indyk,and V.Mirrokni,“Locality-SensitiveHashing Scheme Based on p-Stable Distributions,”Proc.Symp. ComputationalGeometry, 2004.
3、A.Andoni,“Nearest Neighbor Search:The Old, theNew, and the Impossible”PhD dissertation,MIT,2009.
4、A.Andoni,P.Indyk.E2lsh:Exact Euclidean locality-sensitive hashing.http://web.mit.edu/andoni/www/LSH/.2004.