【Lucene】近实时搜索
近实时搜索:可以使用一个打开的IndexWriter快速搜索索引的变更内容,而不必首先关闭writer,或者向该writer提交;这是2.9版本之后推出的新功能。
代码示例(本例参考《Lucene In Action》):
package com.tan.code;
import java.io.File;
import java.io.IOException;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TermQuery;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.SimpleFSDirectory;
import org.apache.lucene.util.Version;
import org.wltea.analyzer.lucene.IKAnalyzer;
public class NearRealTimeTest {
public static final String INDEX_DIR_PATH = "E:\\indexDir";
private Analyzer analyzer = null;
private File indexFile = null;
private Directory directory = null;
private IndexReader indexReader = null;
private IndexSearcher indexSearcher = null;
private IndexWriter indexWriter = null;
public void nearRealTime() throws IOException {
analyzer = new IKAnalyzer(true);
indexFile = new File(INDEX_DIR_PATH);
directory = new SimpleFSDirectory(indexFile);
indexWriter = new IndexWriter(directory, new IndexWriterConfig(
Version.LUCENE_43, analyzer));
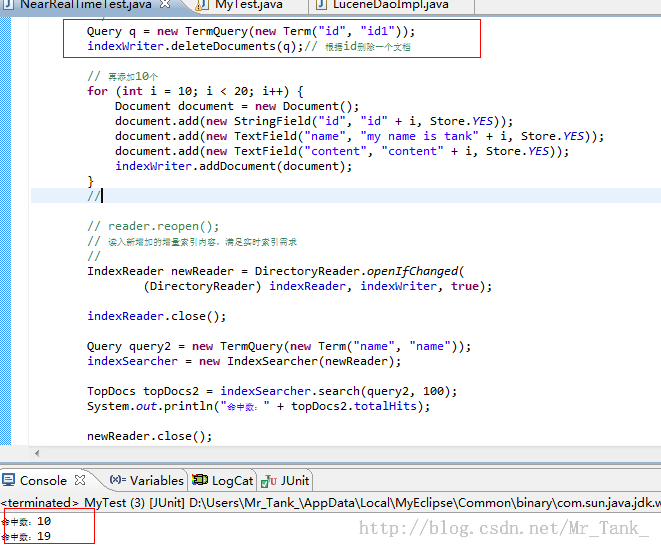
for (int i = 0; i < 10; i++) {
Document document = new Document();
document.add(new StringField("id", "id" + i, Store.YES));
document.add(new TextField("name", "my name is tank" + i, Store.YES));
document.add(new TextField("content", "content" + i, Store.YES));
indexWriter.addDocument(document);
}
// indexReader = DirectoryReader.open(directory);
// 3.x 旧版本中使用indexWriter.getReader()创建近实时reader,本示例代码使用的是4.3.1版本
indexReader = DirectoryReader.open(indexWriter, true);
indexSearcher = new IndexSearcher(indexReader);
Query query = new TermQuery(new Term("name", "name"));
TopDocs topDocs = indexSearcher.search(query, 100);
System.out.println("命中数:" + topDocs.totalHits);
/*
* 建立索引变更,但是不提交
*/
Query q = new TermQuery(new Term("id", "id1"));
indexWriter.deleteDocuments(q);// 根据id删除一个文档
// 再添加10个
for (int i = 10; i < 20; i++) {
Document document = new Document();
document.add(new StringField("id", "id" + i, Store.YES));
document.add(new TextField("name", "my name is tank" + i, Store.YES));
document.add(new TextField("content", "content" + i, Store.YES));
indexWriter.addDocument(document);
}
//
// reader.reopen();
// 读入新增加的增量索引内容,满足实时索引需求
//
IndexReader newReader = DirectoryReader.openIfChanged(
(DirectoryReader) indexReader, indexWriter, true);
indexReader.close();
Query query2 = new TermQuery(new Term("name", "name"));
indexSearcher = new IndexSearcher(newReader);
TopDocs topDocs2 = indexSearcher.search(query2, 100);
System.out.println("命中数:" + topDocs2.totalHits);
newReader.close();
indexWriter.close();
}
}
测试代码:
package com.tan.test;
import static org.junit.Assert.*;
import java.io.IOException;
import org.junit.Test;
import com.tan.code.NearRealTimeTest;
public class MyTest {
@Test
public void test() throws IOException {
//fail("Not yet implemented");
NearRealTimeTest nearRealTimeTest=new NearRealTimeTest();
nearRealTimeTest.nearRealTime();
}
}
测试结果(建议使用Luke查看索引结果):
【推荐博客:http://qindongliang1922.iteye.com/category/282568】