关于iptables的u32匹配
前面一篇文章----阐释了iptables最新的bpf match,说它将多个matches并成了一个经过编译的解释型bytecode bpf match,早在bpf match之前,u32 match也可以做到matches合并,虽然语法让人费解没有分离match可读性强之外,效率还真是高!它可以做到无状态检测的很多事情,不能做到有状态检测比如基于conntrack的检测是因为IP协议本身就是无状态的!这篇文章详细介绍了u32 match的用法。 本文介绍了详细用法
本文从一个实际可用的例子出发,来了解一下这个u32 match。
1.基于包的路由负载均衡
即使不使用statistic match,也能实现基于包的路由负载均衡,答案就是u32。统观IP头,没有什么其他字段好用,唯一的一个就是ID字段,我们知道,这个ID字段是为了区分IP报文的,可以是所有四层协议全局的递增字段,也可以是四层协议私有的递增字段,因此我们可以用该字段的奇偶来作为负载均衡的依据:
echo "100 A" >> /etc/iproute2/rt_tables
echo "200 B" >> /etc/iproute2/rt_tables
ip route add default via $gw_A table A
ip route add default via $gw_B table B
ip rule add fwmark 10 table A
ip rule add fwmark 20 table B
iptables -t mangle -A OUTPUT/FORWARD -m u32 --u32 "2&0x1=0" -j MARK --set-mark 10
iptables -t mangle -A OUTPUT/FORWARD -m u32 --u32 "2&0x1=1" -j MARK --set-mark 20
如此就完成了负载均衡的配置。没有用到conntrack状态,也没有用到单独的statistic match。
插曲:起初我以为在filter表中使用MARK target,由于OUTPUT这个HOOK是位于route动作之后的,一般而言,对于OUTPUT包,标准route过后,如果发现mark,destination等影响路由动作的字段被hook function改变之后,会reroute,也就是调用ip_route_me_harder函数的,然而filter表的职责就是filter,即使mark改变了,它也并不会去reroute,即使set-mark能成功,其意义也会默默失效(也许POSTROUTING中也能用到这个MARK,但不经常)。因此只能在mangle表中使用。然而我有点生气了,既然不能用,那为何不直接在filter表中set-mark时就报错呢?最讨厌一些机制默默地起作用或者默默地失效!如果有问题,你可以抱怨,但是不能沉默!
2.u32 match详情
上述的“2&0x1=0”这句怎么理解呢?其实还有更加复杂的,比如“ 0>>22&0x3C@ 12>>26&0x3C@ 0=0x5353482D”等。实际上,如果理解了u32 match的语法,上面这些也没有什么难的。
简单的讲,u32 match就是一个算式,该算式是一个由&&拼起来的多个子match的集合,每一个子match可以理解成一个标准的iptables match比如-p udp,--dport 1194之类的。每一个子match有4个运算符可以用,分别是:
&:按位与操作。该操作可以过滤出一个IP数据报中我们需要的最多四个字节。
<<:左移操作。该操作的含义和C语言一致。
>>:右移操作。同上
@:向前推进操作。该操作允许你将匹配向前skip掉你不感兴趣的字节数
这些可以从man手册或者 http://www.stearns.org/doc/iptables-u32.v0.1.7.html上得到更详细的描述。本质上u32 match可以理解成下面的形式:
location = value && location = value ...
其中,location可以有几种方式得到:
立即数方式:取从IP报头开始的立即数指示的偏移初的绝对字节值;
数值移位方式:先取数值偏移位置的4字节绝对数值,将绝对数据通过移位转换为相对数值;
数值&掩码方式:取立即数指示的偏移位置的4字节数值,屏蔽掉不感兴趣的位;
数值@偏移:跳过数值指示的字节,然后取当前锚点后偏移处的值;
注意上述的location计算是可以嵌套的,也就是说立即数可以通过上述的运算法计算得到,比如如下的算式:
0>>22&0x3C@4=0x29
其中0>>22&0x3C计算出一个数值为X,@表示跳过X字节,4作为相对偏移加上X得到绝对偏移,取值,与0x29比较,进一步分析0>>22,它的含义是取IP报头的第0偏移处的4字节值一共32位,右移22位得到10位的数值,接下来和0x3C即二进制的111100按位与,得到上述的IP头长度X。
需要注意的是,u32的匹配操作是以4字节为单位的,这就引出了下面一个小节的主题!
3.为什么要减去3
在u32的操作文档上,Start@Mask的方式中,Start的计算为匹配的最后一个字节的偏移减去3,这个3到底是怎么回事呢?实际上这完全是为了书写上的简单,为了将最后在特定位置取得的数值移动到4字节的低位,举例如下,如果Start从0开始,那么如果匹配IP报头的proto字段为ICMP的话,可以这么写:
9&0xff000000 = 0x01000000;
这个写法非常长,因为匹配是从前到后的,因此掩码就必须把后面的位清除,保留最前面的高位,最终的location = value算式中,value的值也不得不写成低位清除的方式,如果一开始就从第4字节开始计算偏移,就可以解决这个问题。为了总是能将mask过滤后匹配字段留在低位,需要一个不是0的基准偏移,以后其它的偏移都由需要匹配的最后面字节的偏移和这个不是0的基准偏移相减得到,由于u32是基于4字节操作的,因此这个基准偏移就第4字节的偏移,即3!如下图所示:
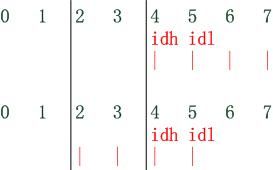
理解了上面的论述后,仍以匹配proto为ICMP为例,其实以下的书写是一致的:
9&0xff000000 = 0x01000000
6&0xff = 0x01
所以不要再为这个3而纠结了!
4.做一个包装
如果说写上述的6&0xff = 0x01之类的东西实在不可读,那么可以做一个封装,编写一个解释器,将可读的诸如bpf的语法翻译成u32的语法,类似:
-m u32 --u32 `u32-compiler 'tcp port 80 and dst 1.2.3.4'`
这个u32-compiler应该非常好写,简单的可以根据u32操作文档的“Tests”小节中给出的用例做一个一一映射表,参数从外部接收即可,文档最后的用例给出了大量的例子:
-
"2&0xFFFF=0x2:0x0100" - Test for IPID's between 2 and 256
-
"0&0xFFFF=0x100:0xFFFF" - Check for packets with 256 or more bytes.
-
"5&0xFF=0:3" - Match packets with a TTL of 3 or less.
-
"16=0xE0000001" - Destination IP address is 224.0.0.1
-
"12&0xFFFFFF00=0xC0A80F00" - Source IP is in the 192.168.15.X class C network.
-
0&0x00FF0000>>16=0x08 - Is the TOS field 8 (Maximize Throughput)?
-
"3&0x20>>5=1" - Is the More Fragments flag set?
-
"6&0xFF=0x6" - Is the packet a TCP packet?
- ......
-
"6&0xFF=1" - Is this an ICMP packet? (From Don Cohen's documentation)
-
"6&0xFF=17" - Is this a UDP packet?
-
"4&0x3FFF=0" - Is the fragment offset 0 and MF cleared? (If so, this is anunfragmented packet).
-
"4&0x3FFF=1:0x3FFF" - Is the fragment offset greater than 0 or MF set? (If so,this is a fragment).
- ......
这个可以用C实现,也可以用脚本实现,毕竟u32不像bpf是一个标准的东西,有自己的规范,u32编译实际上需要做的仅仅就是字符串转换而已。
5.u32和bpf的异同
效率角度
u32和bpf这两个match都可以将诸多的matches浓缩到一个,本质上就是针对IP报文开刀,直接在IP报文游走匹配,非常高效。二者的区别在于,u32的效率完全取决于编码者对整体匹配的认知,而bpf则不需要这样,可以将优化交给JIT编译器来做。
实现角度
在内部实现上,u32 match会涉及到bits copy/compare等操作,而bpf的代码则更紧凑,compare操作内置于bpf的bytecode中,不像u32那样必须先提取完所有信息,然后再比较。
配置角度
在rule可读性上,由于bpf的语法和JIT是分离的,因此你可以写成--bytecode `nfbpf_compiler RAW <可读性强的filter>`,然而由于u32没有所谓的编译期,你必须一开始在rule的编写时就写好它,采用类似start&mask = value之类的令人费解的语法。