题目:The Nested Chinese Restaurant Process and Bayesian Nonparametric Inference of Topic Hierarchies
David M.BLEI 这个LDA领域的大牛,对LDA有诸多变形,这一片是将随机过程(stochastic process)用于无参贝叶斯推断上,构造主题层次树。
2012.9.17
刚刚开始学习,掌握了大概内容。
文中采用的方法:在贝叶斯无参推断(BNP)中,先验和后验分布不再受限于参数的分布,而是一般的随机过程。贝叶斯推断过程也不再受限于优先维空间,可以扩展到一般的无限维空间。
构造主题层次结构树(以JACM1987-2004年间536个摘要——abstract为例)
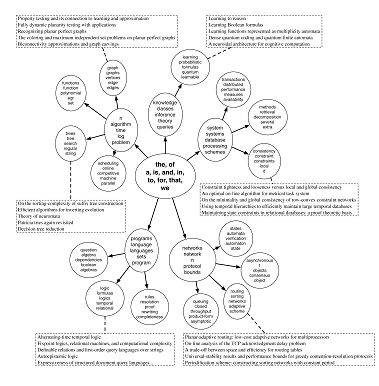
图中可以看到第一层是5个大的计算机的方向,每个方向中列出了前5个主题词,然后每个主题又有若干子主题。
该方法能够发现不同领域中基于唯一的输入数据中的有用的主题层次。通过为文档定义概率模型,不需要定义主题的层次,而是定义统计过程。
文章的结构:首先回顾随机过程和贝叶斯无参统计的必要背景;第3部分:nested Chinese restaurant procee;第4部分:在层次主题模型中使用的拓扑;第5部分:近似后验推断算法;第6部分:样本和经验评估;第7部分:相关工作和讨论。
第2部分:
Aldous 1985(Chinese restaurant process),Antoniak 1974(Dirichlet process mixture).
这部分有一系列的公式,暂时没有看懂,先跳过。
第3部分:The Nested Chinese Restaurant Process (nCRP)
nCRP过程和相关的分布被广泛地使用在Bayesian nonparametric statistics 中,因为,它使得被假设从位置类数量中获取统计模型成为可能。
nCRP的过程大致如下:假设在一个城市中有无限多个餐馆,每个餐馆中有无限多张table。一个餐馆被定义为树的root,它的无限多张table上都有一张card,上面写着其它餐馆的名字。在其它餐馆的每张table上也都有一张card,涉及到其它餐馆的名字,这个结构重复无限多次。
每个餐馆确切地被提交一次;这样这个城市中的餐馆被组织成一个具有无限分支、无限深度的树。注意每个餐馆在树中与一层相关联。树根的餐馆在第1层,根餐馆的table的card上涉及到的餐馆在第2层,如此下去。如下图。
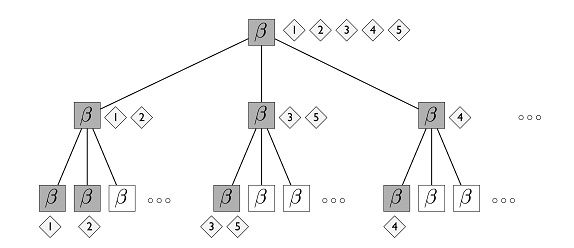
这张图中涉及到3层,每个box表示一个餐馆,有无限多table。如图第1层有5张桌子,每张桌子引用下一层的唯一的table。在这种结构中,5个游客沿着4条唯一的路径visit餐馆。在hLDA模型中,每个餐馆具有topic分布Beta.每个文档被假设假设沿着一个随机选择的路径,从topic分布中选择它的word。
一个游客到这个城市度假,第一天晚上,他进入根上的中观餐馆并且选择了一张table,采用CRP分布选择table。第二天晚上,他去第一天晚上的餐馆table上标识得餐馆,这样一直重复下去。M个游客餐馆这个城市后,路径的集合就描述了无限树的随机子树;子树中一个分支因子,在所有节点上有至多为M。
(图中每个Beta表示1个餐馆,根上表示1个餐馆(有1,2,3,4,5游客来),这个餐馆的table指向了3个餐馆,1,2游客去了第二层最左边的餐馆,3,5游客去了第二层中间的餐馆,4游客去了第二层最右边的餐馆)
有许多方法在树上设置先验分布,我们的特殊选择是基于几个考虑。首要的是,一个先验分布与似然结合以产生后验分布。
4.Hierarchical Latent Dirichlet Allocation
nCRP提供了在树拓扑上定义先验的方法,不受分支因子(数目)或深度的限制。我们采用这种分布作为概率topic模型的一个组成部分。
topic模型的目标是识别Document中word的子集。早期的topic建模起源于潜在语义分析,随后的工作将topic看做word上的概率分布,使用基于似然的方法从词库中估计这些分布。在LDA中概率topic模型被作为全Bayesian对待。
像LDA这样的topic模型,将topics对待为“flat”概率集合,在一个topic和另外topics之间没有直接的联系。这些模型可以从词库中发现topics,不能说明topic之间抽象的层次或者各种主题之间的联系。
我们提出的这个模型,建立在nCRP上,敌营了hierarchical topic model。这个模型将topics安排在tree中,具有一般性的主题应该出现在接近于root的位置,更具体的topics应该在叶子附近。
定义这样的模型,我们使用概率推断同时识别topics和他们之间的关系。我们的方法定义层次topic model,基于识别由nCRP差生的带有路径的文档。将ncRP增加到两个方式去获取文档的产生模式,首先对树中的每个节点,赋予一个主题(也就是word上的概率分布);第二,给定一个路径选择,使用GEM分布定义沿着这个路径的topic的概率分布。给定一个draw,从GEM分布,document被产生,通过重复地选择topic,根据draw定义的概率,然后从它选定的topic中选择word。
一般过程:

这里,无限树由nCRP定义,并且设置Cd表示第d个customer通过的路径(例如document)。在hierarchical LDA(hLDA)中词库中的documents是假设从上面的过程中产生的。
这里Z~Discrete(theta)分布,表示Z=i具有概率thetaI集合的离散分布.
找到摘要(abstraction)的topic主题曾是是不同于层次聚类的。层次聚类是从下到上将每个节点看成叶子,结合产生根节点。内部节点反映的是下层节点的概括。而此方法:内部节点不是他们孩子节点的概括,而是反映了一种“共享”,第1张图中,一个节点的高概率词与其下层节点高概率词是不同的。
很重要的一点事,我们的方法是无监督学习方法,在我们已经定义的概率成分是潜在变量。也就是我们不需要假设topics是预先定义,也不需要建设document的嵌套分区或者主题在预定义的哪一层上。我们从Baysian计算中推断实体,计算所有的潜在变量。
注意,即使这个方法很灵活,模型仍然做了关于tree的假设。tree的大小、形状和特征将由设置的hyerparameters集合来反映。影响最大的hyperparameter是Dirichlet参数——主题yita和stick-breaking(分块?)参数,用作topic比例{m,pi}。yita控制topics的稀疏性;{m,pi}控制文档中多少个词可能来自于各种摘要的主题。小的yita将导致在小的words集合上产生topic,topics就多。如果设m大,例如m=0.5那么将可能从每个document中分配更多的words在抽象的更高层次上。设pi是大的,例如pi=100,意味着word分布将不可能脱离这样的设置。
最后,我们注意到,hLDA是展示nCRP的最简单的模型,在更复杂的模型中,可以看率变体hLDA,每个文档展示多条树上的路径。这可以使用两层分布对word产生建模:首先选择树的路径,然后为word选择词。
最近对topic模型的扩展也可以考虑使用灵活的topic层次。在dynamic topic model中,文档time stamped和隐藏的主题随时间变化等。
我们提出了另外的方法在text分析中使用层次概念。首先,我们学习topics层次而不是术语层次,这里topics是术语的分布,描述了数据中word发生的有意义的模式。此外,当关注text时,topics是简化的word产生的分布,不依赖于词的类型等其他信息,例如词库或语法。最后,我们的方法可以适应将来的数据。
在我们的无参集合中,必须找到给定documents集合的层次、路径分配和words层次分布对象的后验分布。更进一步,我们需要能够使用计算机的有限资源去做,hLDA不能再闭集上获得,需要估计。
5.Probabilistic Inference
使用Markov chain Monte Carlo(MCMC)算法估计hLDA的后验概率。在本文中采用了Gibbs采样,使用collapsed Gibbs Simpling[Liu 1994]。
在hLDA中,我们采样每个document的路径Cd和每个词对主题的层次分布,在路径Zd,n上。我们边缘化(marginalize out)参数BetaI和每个document的topc比例Thetad。对于单个文档的Markov chain的演示如下:
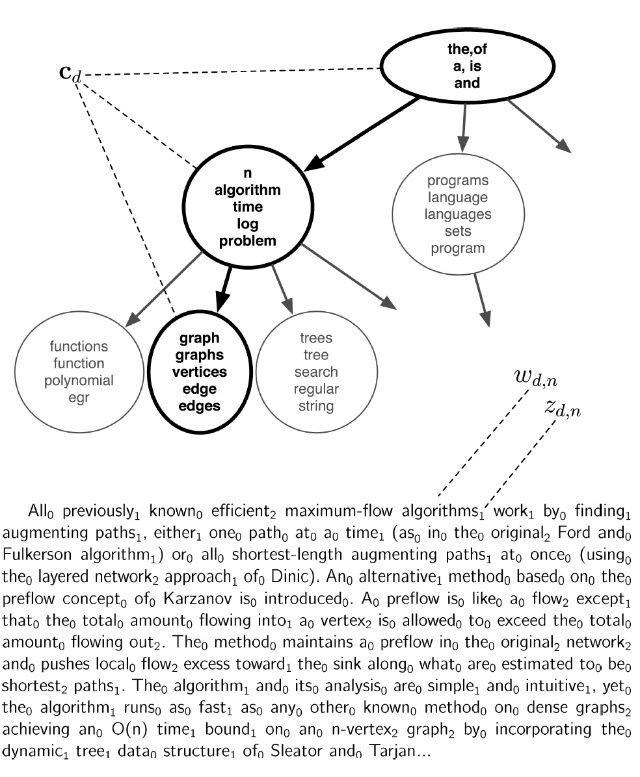
这是"A new approach to the maximum-flow problem"文章的摘要,摘要中的每个词都被Wd,n都被在路径上分配一个层次Zd,n,0表示最高层,2表示最底层。Gibbs采样迭代取得文档中所有word的Cd和Zd,n。
随后又一系列的参数推断,还没有完全看懂。
6.Examples和Empirical Results
一般来讲,我们不能期望总是获得正确的tree。这要依赖于数据集的大小,topics是多么的一致。在那些一词多以或者topics之间比较相似的数据集中tree是不容易被识别的。
hLDA与LDA的比较:首先在LDA中topic的数目是固定的参数,模式选择过程需要选择topics的数目。在层次Dirichlet process中可以解决这个问题。第二,给定topics集合,LDA没有在词库中document使用的topics加以约束;而在hLDA中,document只能访问在树中存在于单一路径上的topics。这样来讲LDA比hLDA更灵活。
所以,可以扩展hLDA,先用LDA找到topics,然后再用hLDA建立topics的层次。
进一步的工作,找到结合LDA和hLDA模型特征的合理的模型,可以考虑一个类hLDA层次模型,允许每个document沿着tree展开多条路径。这样的方法将更适用于full-text文章,而不是abstract。